

Förster
I thought the criticisms of social psychologist Jens Förster were already quite damning (despite some attempts to explain them as mere QRPs), but there’s recently been some pushback from two of his co-authors Liberman and Denzler. Their objections are directed to the application of a distinct method, touted as “Bayesian forensics”, to their joint work with Förster. I discussed it very briefly in a recent “rejected post“. Perhaps the earlier method of criticism was inapplicable to these additional papers, and there’s an interest in seeing those papers retracted as well as the one that was. I don’t claim to know. A distinct “policy” issue is whether there should be uniform standards for retraction calls. At the very least, one would think new methods should be well-vetted before subjecting authors to their indictment (particularly methods which are incapable of issuing in exculpatory evidence, like this one). Here’s a portion of their response. I don’t claim to be up on this case, but I’d be very glad to have reader feedback.
Nira Liberman, School of Psychological Sciences, Tel Aviv University, Israel
Markus Denzler, Federal University of Applied Administrative Sciences, Germany
June 7, 2015
Response to a Report Published by the University of Amsterdam
The University of Amsterdam (UvA) has recently announced the completion of a report that summarizes an examination of all the empirical articles by Jens Förster (JF) during the years of his affiliation with UvA, including those co-authored by us. The report is available online. The report relies solely on statistical evaluation, using the method originally employed in the anonymous complaint against JF, as well as a new version of a method for detecting “low scientific veracity” of data, developed by Prof. Klaassen (2015). The report concludes that some of the examined publications show “strong statistical evidence for low scientific veracity”, some show “inconclusive evidence for low scientific veracity”, and some show “no evidence for low veracity”. UvA announced that on the basis of that report, it would send letters to the Journals, asking them to retract articles from the first category, and to consider retraction of articles in the second category.
After examining the report, we have reached the conclusion that it is misleading, biased and is based on erroneous statistical procedures. In view of that we surmise that it does not present reliable evidence for “low scientific veracity”.
We ask you to consider our criticism of the methods used in UvA’s report and the procedures leading to their recommendations in your decision.
Let us emphasize that we never fabricated or manipulated data, nor have we ever witnessed such behavior on the part of Jens Förster or other co-authors.
Here are our major points of criticism. Please note that, due to time considerations, our examination and criticism focus on papers co-authored by us. Below, we provide some background information and then elaborate on these points.
- The new method is falsely portrayed as “standard procedure in Bayesian forensic inference.” In fact, it is set up in such a way that evidence can only strengthen a prior belief in low data veracity. This method is not widely accepted among other experts, and has never been published in a peer-reviewed journal.
Despite that, UvA’s recommendations for all but one of the papers in question are solely based on this method. No confirming (not to mention disconfirming) evidence from independent sources was sought or considered.
- The new method’s criteria for “low veracity” are too inclusive (5-8% chance to wrongly accuse a publication as having “strong evidence of low veracity” and as high as 40% chance to wrongly accuse a publication as showing “inconclusive evidence for low veracity”). Illustrating the potential consequences, a failed replication paper by other authors that we examined was flagged by this method.
- The new method (and in fact also the “old method” used in former cases against JF) rests on a wrong assumption that dependence of errors between experimental conditions necessarily indicates “low veracity”, whereas in real experimental settings many (benign) reasons may contribute to such dependence.
- The reports treats between-subjects designs of 3 x 2 as two independent instances of 3-level single-factor experiments. However, the same (benign) procedures may render this assumption questionable, thus inflating the indicators for “low veracity” used in the report.
- The new method (and also the old method) estimate fraud as extent of deviation from a linear contrast. This contrast cannot be applied to “control” variables (or control conditions) for which experimental effects were neither predicted nor found, as was done in the report. The misguided application of the linear contrast to control variables also produces, in some cases, inflated estimates of “low veracity”.
- The new method appears to be critically sensitive to minute changes in values that are within the boundaries of rounding.
- Finally, we examine every co-authored paper that was classified as showing “strong” or “inconclusive” evidence of low veracity (excluding one paper that is already retracted), and show that it does not feature any reliable evidence for low veracity.
Background
On April 2nd each of us received an email from the head of the Psychology Department at the University of Amsterdam (UvA), Prof. De Groot, on behalf of University’s Executive Board. She informed us that all the empirical articles by Jens Förster (JF) during the years of his affiliation with UvA, including those co-authored by us, have been examined by three statisticians who submitted their report. According to this (earlier version of the) report, we were told, some of the examined publications had “strong statistical evidence for fabrication”, some had “questionable veracity,” and some showed “no statistical evidence for fabrication”. Prof. De Groot also wrote that on the basis of that report, letters would be sent to the relevant Journals, asking them to retract articles from the first two categories. It is important to note that this was the first time we were officially informed about the investigation. None of the co-authors had been ever contacted by UvA to assist with the investigation. The University could have taken interest in the data files, or in earlier drafts of the papers, or in information on when, where and by whom the studies were run. Apparently, however, UvA’s Executive Board did not find any of these relevant for judging the potential veracity of the publications and requesting retraction.
Only upon repeated requests, on April 7th, 2015 we received the 109-page report (dated March 31st, 2015) and were given 2.5 weeks to respond. This deadline was determined one-sidedly. Also, UvA did not provide the R-code used to investigate our papers for almost two weeks (until April 22nd), despite the fact that it was listed as an attachment to the initial report. We responded on April 27th, following which the authors of the report corrected it (henceforth Report-R) and wrote a response letter (henceforth, the PKW letter, after authors Peeters, Klaassen, and de Wiel ). Both documents are dated May 15, 2015, but were sent to us only on June 2, the same day that UvA also published the news regarding the report and its conclusions on its official site, and the final report was leaked. Thus, we were not allowed any time to read Report-R or the PKW letter before the report and UvA’s conclusions were made public. These and other procedural decisions by the UvA were needlessly detrimental to us.
The present response letter refers to Report-R. The R-Report is almost unchanged compared to the original report, except that the language of the report and the labels for the qualitative assessments of the papers is somewhat softened, to refer to “low veracity” rather than “fraud” or “manipulation”. This has been done to reflect the authors’ own acknowledgement that their methods “cannot demarcate fabrication from erroneous or questionable research practices.” UvA’s retraction decisions only slightly changed in response to this acknowledgement. They are still requesting retraction of papers with “strong evidence for low veracity”. They are also asking journals to “consider retraction” for papers with “inconclusive evidence for low veracity,” which seems not to match this lukewarm new label (also see Point 2 below about the likelihood for a paper to to receive this label erroneously).
Unlike our initial response letter, this letter is not addressed to UvA, but rather to editors who read Report-R or reports about it. To keep things simple, we will refer to the PKW letter by citing from it only when necessary. In this way, a reader can follow our argument by reading Report-R and the present letter, but is not required to also read the original version of the report, our previous response letter, and the PKW letter.
Because of time pressure, we decided to respond only to findings that concerned co-authored papers, excluding the by-now-retracted paper Förster and Denzler (2012, SPPS). We therefore looked at the general introduction of Report-R and at the sections that concern the following papers:
In the “strong evidence for low veracity” category
Förster and Denzler, 2012, JESP
Förster, Epstude, and Ozelsel, 2009, PSPB
Förster, Liberman, and Shapira, 2009, JEP:G
Liberman and Förster, 2009, JPSP
In the “inconclusive evidence for low veracity” category
Denzler, Förster, and Liberman, 2009, JESP
Förster, Liberman, and Kuschel, 2008, JPSP
Kuschel, Förster, and Denzler, 2010, SPPS
This is not meant to suggest that our criticism does not apply to the other parts of Report-R. We just did not have sufficient time to carefully examine them. We would like to elaborate now on points 1-7 above and explain in detail why we think that UvA’s report is biased, misleading, and flawed.
- The new method by Klaassen (2015) (the V method) is inherently biased
Report-R heavily relies on a new method for detecting low veracity (Klaassen, 2015), whose author, Prof. Klaassen, is also one of the authors of Report-R (and its previous version).
In this method (which we’ll refer to as the V method), a V coefficient is computed and used as an indicator of data veracity. V is called “evidential value” and is treated as the belief-updating coefficient in Bayes formula, as in equation (2) in Klaassen (2015) 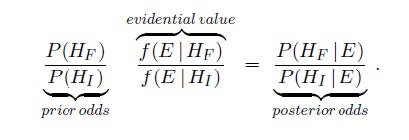 For example, according to the V method, when we examine a new study with V = 2, our posterior odds for fabrication should be double the prior odds. If we now add another study with V = 3, our confidence in fabrication should triple still. Klaassen, 2015, writes “When a paper contains more than one study based on independent data, then the evidential values of these studies can and may be combined into an overall evidential value by multiplication in order to determine the validity of the whole paper” (p. 10).
For example, according to the V method, when we examine a new study with V = 2, our posterior odds for fabrication should be double the prior odds. If we now add another study with V = 3, our confidence in fabrication should triple still. Klaassen, 2015, writes “When a paper contains more than one study based on independent data, then the evidential values of these studies can and may be combined into an overall evidential value by multiplication in order to determine the validity of the whole paper” (p. 10).
The problem is that V is not allowed to be less than unity. This means that there is nothing that can ever reduce confidence in the hypothesis of “low data veracity”. The V method entails, for example, that the more studies there are in a paper, the more we should get convinced that the data has low veracity.
Klaassen (2015) writes “we apply the by now standard approach in Forensic Statistics” (p. 1). We doubt very much, however, that an approach that can only increase confidence in a defendant’s guilt could be a standard approach in court.
We consulted an expert in Bayesian statistics (s/he preferred not to disclose her name). S/he found the V method problematic, and noted that quite contrary to the V method, typical Bayesian methods would allow both upward and downward changes in one’s confidence in a prior hypothesis.
In their letter, PKW defend the V method by saying that it has been used in the Stapel and Smeesters cases. As far as we know, however, in these cases there was other, independent evidence of fraud (e.g., Stapel reported significant effects with t-test values smaller than 1, in a Smeesters’ data individual scores were distributed too evenly; see Simonsohn, 2013) and the V method was only supporting other evidence. In contrast, in our case, labeling the papers in question as having “low scientific veracity” is almost always based only on V values – the second method for testing “ultra-linearity” in a set of studies (ΔF combined with the Fisher’s method) either could not be applied due to a low number of independent studies in the paper or was applied and did not yield a reason for concern. We do not know what weight the V method received in the Staple and Smeesters cases (relative to other evidence), and whether all the experts who examined those cases found the method useful. As noted before, a statistician we consulted found the method very problematic.
The authors of Report-R do acknowledge that combining V values becomes problematic as the number of studies increases (e.g., p. 4) and explain in the PKW letter that “the conclusions reached in the report are never based on overall evidential values, but on the (number of) evidential values of individual samples/sub-experiments that are considered substantial”. They nevertheless proceed to compute overall V’s and report them repeatedly in Report-R (e.g., “The overall V has a lower bound of 9.93”, p. 31; “The overall V amounts to 8.77”, on p. 66). Why?
- The criteria for “low veracity” are too inclusive
… applying the V method across the board would result in erroneously retracting 1/12-1/19 of all published papers with experimental designs similar to those examined in Report-R (before taking into account those flagged as exhibiting “inconclusive” evidence).
In their letter, PKW write “these probabilities are in line with (statistical) standards for accepting a chance-result as scientific evidence”. In fact, these p-values are higher than is commonly acceptable in science. One would think that in “forensic” contexts of “fraud detection” the threshold should be, if anything, even higher (meaning, with lower chance for error).
Report-R says “When there is no strong evidence for low scientific veracity (according to the judgment above), but there are multiple constituent (sub)experiments with a substantial evidential value, then the evidence for low scientific veracity of a publication is considered inconclusive (p.2).” As already mentioned, UvA plans to ask journals to consider retraction of such papers. For example, in Denzler, Förster, and Liberman (2009) there are two Vs that are greater than 6 (Table 14.2) out of 17 V values computed for that paper in Report-R. The probability of obtaining two or more values of 6 or more out of 17 computed values by chance is 0.40. Let us reiterate this figure – 40% chance of type-I error.
Do these thresholds provide good enough reasons to ask journals to retract a paper or consider retraction? Apparently, the Executive Board of the University of Amsterdam thinks so. We are sure that many would disagree.
An anecdotal demonstration of the potential consequences of applying such liberal standards comes from our examination of a recent publication by Blanken, de Ven, Zeelenberg, and Meijers (2014, Social Psychology) using the V method. We chose this paper because it had the appropriate design (three between-subjects conditions) and was conducted as part of an Open Science replication initiative. It presents three failures to replicate the moral licensing effect (e.g., Merritt, Effron, & Monin, 2010) . The whole research process is fully transparent and materials and data are available online. The three experiments in this paper yield 10 V values, two of which are higher than 6 (9.02 and 6.18; we thank PKW for correcting a slight error in our earlier computation). The probability of obtaining two or more V-values of 6 or more out of 10 by chance is 0.19. By the criteria of Report-R, this paper would be classified as showing “inconclusive evidence of low veracity”. By the standards of UvA’s Executive Board, which did not seek any confirming evidence to statistical findings based on the V method, this would require sending a note to the journal asking it to consider retraction of this failed replication paper. We doubt if many would find this reasonable.
It is interesting in this context to note that in a different investigation that applied a variation of the V method (investigation of the Smeesters case) a V = 9 was used as the threshold. Simply adopting that threshold from previous work in the current report would dramatically change the conclusions. Of the 20 V values deemed “substantial” in the papers we consider here, only four have Vs over 9, which would qualify them as “substantial” with this higher threshold. Accordingly, none of the papers would have made it to the “strong evidence” category. In addition, three of the four Vs that are above 9 pertain to control conditions – we elaborate later on why this might be problematic.
- Dependence of measurement errors does not necessarily indicate low veracity
Klaassen (2015) writes: “If authors are fiddling around with data and are fabricating and falsifying data, they tend to underestimate the variation that the data should show due to the randomness within the model. Within the framework of the above ANOVA-regression case, we model this by introducing dependence between the normal random variables ε ij , which represent the measurement errors” (p. 3). Thus, the argument that underlies the V method is that if fraud tends to create dependence of measurement errors between independent samples, then any evidence of such dependence is indicative of fraud. This is a logically invalid deduction. There are many benign causes that might create dependency between measurement errors in independent conditions. ……
See the entire response: Response to a Report Published by the University of Amsterdam.
Klaassen, C. A. J. (2015). Evidential value in ANOVA-regression results in scientific integrity studies. arXiv:1405.4540v2 [stat.ME].
Discussion of the Klaassen method on pubpeer review https://pubpeer.com/publications/5439C6BFF5744F6F47A2E0E9456703
Some previous posts on Jens Förster case:
- May 10, 2014: Who ya gonna call for statistical Fraudbusting? R.A. Fisher, P-values, and error statistics (again)
- January 18, 2015: Power Analysis and Non-Replicability: If bad statistics is prevalent in your field, does it follow you can’t be guilty of scientific fraud?


")


I would like to flag up a principle of evidence shared by medical practice, scientific research and law. Contemporaneous records are an important aspect of evidence. When I was trained in medicine, I was taught that the patient’s symptoms, signs, and test results had to be recorded at the time they were obtained (usually in hand-writing). When I was trained in the laboratory, I wrote all my results in a bench book (often with print-outs of results stapled in). During clinical trials, the results were all recorded on a carefully prepared paper or electronic form for each patient. In a court of law, it is only records made at the time of an observed event that one is allowed to refer to in court (e.g. the policeman’s note-book). These are all examples of ‘primary sources’ and they are often ‘proven’ or ‘verified’ also by cross examination of the ‘witness’ (a scientist being a ‘witness’ of nature).
All other evidence, such as medical summaries, research papers, and legal statements are regarded as ‘secondary sources’. Any reasoning or calculations based on these non-primary sources are not properly ‘evidence-based’. They may raise questions and suggests conclusions but they are not regarded as reliable evidence. So, whatever calculations and inferences (Bayesian or otherwise) were applied to the results sections of Forster’s papers, they should not be regarded as conclusive. They only raise serious questions based on various probabilities of scientific misconduct. The only reliable way of assessing the ‘veracity’ of the work is by examining the original items of ‘raw’ data obtained from the subjects of the research and re-analysing them.
The problem was that these original records had apparently been destroyed by Professor Forster before they could be examined in this way. This is the crux of the matter. If a doctor was found to have done this he would be guilty of professional misconduct. My understanding is that it was this destruction of evidence that was the ‘fact’ that led to the papers being withdrawn from publication (correct me someone if I am wrong). This destruction of evidence also meant that Professor Forster’s results could not be verified or found to have been fabricated, so the allegations arising from the Bayesian calculations etc. remain unproven.
If you argue like this you also have to mention that when it comes to paper questionnaires it has been confirmed by various of his colleagues that it was not his idea to get rid of them. He and the rest of his colleagues had to do that upon the request of the research director of the department. The reason was a relocation of the department into a building with smaller office space. Interestingly, the research director “forgot” to mention this fact in her hearing in the first round of the investigation. She has faced zero consequences for that and is still a member of a national committee for data storage. Only when things became public the remaining colleagues tried to correct the initial misinformation about that matter, but were not heard very widely.
If you read the co-authors’ statement carefully you will notice that the current investigators did not express any interest in data, nor did they seem to ever have contacted any of the affected people. Given that Forster is not the first author of some of the flagged papers this is an issue. He might not even have been related to the data collection at all. So the U. of Amsterdam seems to strongly believe in these statistical methods, and has a “guilty by default” and “guilty by association” approach. This is the actual problem here. People are publicly accused of something, but the evidence is very problematic. How are you supposed to defend yourself against such evidence? One seemingly has to have some stats friends who can help. Otherwise you’re doomed.
I agree with Dr. Mayo’s statement that a method should be properly vetted before you put people through the public humiliation. Even if you are critical about the Forster the procedural matters of this investigation should seem appalling.
> The only reliable way of assessing the ‘veracity’ of the work is by examining the original items of ‘raw’ data obtained from the subjects of the research and re-analysing them.
Well put and unfortunately the incentive to destroy or have legal barriers to their access.
Keith O’Rourke
I agree very much with Huw Llewelyn’s remarks.
Another point is the following. Science is public. When you publish a paper, it is up for discussion. I think that these “scientific integrity” discussions and “retraction calls” degenerate into witch-hunts and also degenerate into legal wrangling.
I think that the research done by Klaassen, Peeters and van der Wiel into further works of Förster needed to be done, and that their findings needed to be published. It can be applauded that not only their report but also their R code is available.
I think it is wrong that authorities at the UvA now ask journals for retraction. The correct procedure is: disseminate the report, make sure that the authors of the criticised papers and the journals where they are published are informed. Let the research community in social psychology figure out whether the published work was reliable or not. Let the statistics methodology community figure out whether or not the methodology of KPW is reliable. First and foremost, get those two communities communicating with one another. Get those QRP’s understood and get them abolished. If you *need* QRP’s in order to get publishable research in some research field, there is something very unhealthy going on in that field.
*Please* let’s keep the administrators, managers and lawyers out of the game.
If the result of normal scientific discussion is that some published work is unreliable in some way or other, then the authors should publish correction notes or even request “retraction” … which by the way, should not mean that papers are erased from the scientific record.
If after all that, it turns out that some scientist has “not done the right thing” then the people who pay for their salary might like to take further actions. But this is something which belongs in the private sphere.
I suggest that PubPeer discussions are started on each of the papers which KPW find the most “suspicious” features. Let the authors of those papers publish their data and explain their research procedures.
Please also see comments here:
http://rejectedpostsofdmayo.com/2015/06/09/fraudulent-until-proved-innocent-is-this-really-the-new-bayesian-forensics-rejected-post/
I should add that I completely agree with Liberman and Denzler’s critique on the purported Bayesian underpinnings of the V method and with their critique of the procedure followed by UvA. I already wrote this on Mayo’s “rejected posts” blog and even earlier, elsewhere in the social media.
IMHO, “V” is “just another frequentist statistic for testing too-good-to-be-true”. It appears to have higher power than the usual left-tail F statistic. It is interesting and potentially very useful. It has to be used wisely.
IMHO, the “forensic statistics” approach in the Klaassen 2014 preprint is *not* how things are done in forensic statistics, and the reasoning in the preprint is faulty. The author confuses hypotheses and evidence, and confuses hypotheses at the “study” level and hypotheses at the “paper” level.
What do you mean it confuses hypothesis and evidence? If it does, I don’t see how notions of power can make sense. Before a claim is warranted by a method, that method should have had a good or reasonable capability to have discerned its falsity.
Read it, Mayo!
The Bayesian talk is all mixed up. Contains evident nonsense. But the mathematical derivation of frequentist properties of a sensibly frequentistically motivated test statistic makes good sense.
The two are quite independent of one another. The Bayes talk is in one section. The frequentist maths in another. They have no relation with one another. (I didn’t check if they really are in different sections, but they might just as well be. Separate them, delete the Bayes stuff: what’s left is fine).
In the Bayesian talk, author identifies “V >= 6” with “low scientific veracity”. But “V >= 6” is evidence. The value of V is evidence. “Low scientific veracity” is a hypothesis.
There are hypotheses about an individual study, and there are hypotheses about a complete scientific paper (containing results of a number of studies). These two need to be distinguished.
http://arxiv.org/abs/1506.07447 Fraud detection with statistics: A comment on “Evidential Value in ANOVA-Regression Results in Scientific Integrity Studies” (Klaassen, 2015) by Hannes Matuschek
Abstract: Klaassen in (Klaassen 2015) proposed a method for the detection of data manipulation given the means and standard deviations for the cells of a oneway ANOVA design. This comment critically reviews this method. In addition, inspired by this analysis, an alternative approach to test sample correlations over several experiments is derived. The results are in close agreement with the initial analysis reported by an anonymous whistleblower. Importantly, the statistic requires several similar experiments; a test for correlations between 3 sample means based on a single experiment must be considered as unreliable.