
 Imagine. The New York Times reported a few days ago that the FBI erroneously identified criminals 96% of the time based on probability assessments using forensic hair samples (up until 2000). Sometimes the hair wasn’t even human, it might have come from a dog, a cat or a fur coat! I posted on the unreliability of hair forensics a few years ago. The forensics of bite marks aren’t much better.[i] John Byrd, forensic analyst and reader of this blog had commented at the time that: “At the root of it is the tradition of hiring non-scientists into the technical positions in the labs. They tended to be agents. That explains a lot about misinterpretation of the weight of evidence and the inability to explain the import of lab findings in court.” DNA is supposed to cure all that. So is it? I don’t know, but apparently the FBI “has agreed to provide free DNA testing where there is either a court order or a request for testing by the prosecution.”[ii] See the FBI report.
Imagine. The New York Times reported a few days ago that the FBI erroneously identified criminals 96% of the time based on probability assessments using forensic hair samples (up until 2000). Sometimes the hair wasn’t even human, it might have come from a dog, a cat or a fur coat! I posted on the unreliability of hair forensics a few years ago. The forensics of bite marks aren’t much better.[i] John Byrd, forensic analyst and reader of this blog had commented at the time that: “At the root of it is the tradition of hiring non-scientists into the technical positions in the labs. They tended to be agents. That explains a lot about misinterpretation of the weight of evidence and the inability to explain the import of lab findings in court.” DNA is supposed to cure all that. So is it? I don’t know, but apparently the FBI “has agreed to provide free DNA testing where there is either a court order or a request for testing by the prosecution.”[ii] See the FBI report.
Here’s the op-ed from the New York Times from April 27, 2015:
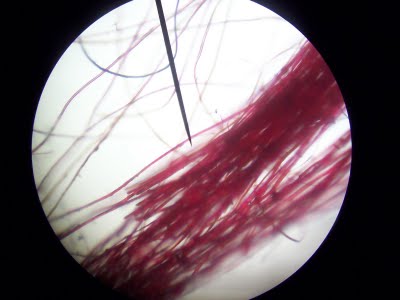
The odds were 10-million-to-one, the prosecution said, against hair strands found at the scene of a 1978 murder of a Washington, D.C., taxi driver belonging to anyone but Santae Tribble. Based largely on this compelling statistic, drawn from the testimony of an analyst with the Federal Bureau of Investigation, Mr. Tribble, 17 at the time, was convicted of the crime and sentenced to 20 years to life.
But the hair did not belong to Mr. Tribble. Some of it wasn’t even human. In 2012, a judge vacated Mr. Tribble’s conviction and dismissed the charges against him when DNA testing showed there was no match between the hair samples, and that one strand had come from a dog.
Mr. Tribble’s case — along with the exoneration of two other men who served decades in prison based on faulty hair-sample analysis — spurred the F.B.I. to conduct a sweeping post-conviction review of 2,500 cases in which its hair-sample lab reported a match.
The preliminary results of that review, which Spencer Hsu of The Washington Post reported last week, are breathtaking: out of 268 criminal cases nationwide between 1985 and 1999, the bureau’s “elite” forensic hair-sample analysts testified wrongly in favor of the prosecution, in 257, or 96 percent of the time. Thirty-two defendants in those cases were sentenced to death; 14 have since been executed or died in prison.
The agency is continuing to review the rest of the cases from the pre-DNA era. The Justice Department is working with the Innocence Project and the National Association of Criminal Defense Lawyers to notify the defendants in those cases that they may have grounds for an appeal. It cannot, however, address the thousands of additional cases where potentially flawed testimony came from one of the 500 to 1,000 state or local analysts trained by the F.B.I. Peter Neufeld, co-founder of the Innocence Project, rightly called this a “complete disaster.”
Law enforcement agencies have long known of the dubious value of hair-sample analysis. A 2009 report by the National Research Council found “no scientific support” and “no uniform standards” for the method’s use in positively identifying a suspect. At best, hair-sample analysis can rule out a suspect, or identify a wide class of people with similar characteristics.
Yet until DNA testing became commonplace in the late 1990s, forensic analysts testified confidently to the near-certainty of matches between hair found at crime scenes and samples taken from defendants. The F.B.I. did not even have written standards on how analysts should testify about their findings until 2012.
















")


{kind=link}