
 It’s good to know that in this incredibly stressed month[i], as we deal with end of semester deadlines, exams, applications and whatnot, that some people have found time for the errorstatistics palindrome contest–in fact, it’s the first time ever that I’ve received three (quite good) candidates (below)! (Help the Elba judges by voting for 1-3, error@vt.edu) Continue reading
It’s good to know that in this incredibly stressed month[i], as we deal with end of semester deadlines, exams, applications and whatnot, that some people have found time for the errorstatistics palindrome contest–in fact, it’s the first time ever that I’ve received three (quite good) candidates (below)! (Help the Elba judges by voting for 1-3, error@vt.edu) Continue reading
Monthly Archives: April 2014
Able Stats Elba: 3 Palindrome nominees for April! (rejected post)
Categories: Palindrome
2 Comments
Reliability and Reproducibility: Fraudulent p-values through multiple testing (and other biases): S. Stanley Young (Phil 6334: Day#13)

 S. Stanley Young, PhD
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
Here are Dr. Stanley Young’s slides from our April 25 seminar. They contain several tips for unearthing deception by fraudulent p-value reports. Since it’s Saturday night, you might wish to perform an experiment with three 10-sided dice*,recording the results of 100 rolls (3 at a time) on the form on slide 13. An entry, e.g., (0,1,3) becomes an imaginary p-value of .013 associated with the type of tumor, male-female, old-young. You report only hypotheses whose null is rejected at a “p-value” less than .05. Forward your results to me for publication in a peer-reviewed journal.
*Sets of 10-sided dice will be offered as a palindrome prize beginning in May.
Categories: Phil6334, science communication, spurious p values, Statistical fraudbusting, Statistics
Tags: S. Stanley Young
12 Comments
Phil 6334 Visitor: S. Stanley Young, “Statistics and Scientific Integrity”
We are pleased to announce our guest speaker at Thursday’s seminar (April 24, 2014): “Statistics and Scientific Integrity”:
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
Author of Resampling-Based Multiple Testing, Westfall and Young (1993) Wiley.

The main readings for the discussion are:
- Young, S. & Karr, A. (2011). Deming, Data and Observational Studies. Signif. 8 (3), 116–120.
- Begley & Ellis (2012) Raise standards for preclinical cancer research. Nature 483: 531-533.
- Ioannidis (2005). Why most published research findings are false. PLoS Med 2(8): e124.
- Peng, R. D., Dominici, F. & Zeger, S. L. (2006). “Reproducible Epidemiologic Research” American Journal of Epidemiology 163 (9), 783-789.
Phil 6334: Foundations of statistics and its consequences: Day #12
 We interspersed key issues from the reading for this session (from Howson and Urbach) with portions of my presentation at the Boston Colloquium (Feb, 2014): Revisiting the Foundations of Statistics in the Era of Big Data: Scaling Up to Meet the Challenge. (Slides below)*.
We interspersed key issues from the reading for this session (from Howson and Urbach) with portions of my presentation at the Boston Colloquium (Feb, 2014): Revisiting the Foundations of Statistics in the Era of Big Data: Scaling Up to Meet the Challenge. (Slides below)*.
Someone sent us a recording (mp3)of the panel discussion from that Colloquium (there’s a lot on “big data” and its politics) including: Mayo, Xiao-Li Meng (Harvard), Kent Staley (St. Louis), and Mark van der Laan (Berkeley).
See if this works: | mp3
*There’s a prelude here to our visitor on April 24: Professor Stanley Young from the National Institute of Statistical Sciences.
Categories: Bayesian/frequentist, Error Statistics, Phil6334
43 Comments
Getting Credit (or blame) for Something You Didn’t Do (BP oil spill)

Spill Cam
Four years ago, many of us were glued to the “spill cam” showing, in real time, the gushing oil from the April 20, 2010 explosion sinking the Deepwater Horizon oil rig in the Gulf of Mexico, killing 11, and spewing oil until July 15 (see video clip that was added below).Remember junk shots, top kill, blowout preventers? [1] The EPA has lifted its gulf drilling ban on BP just a couple of weeks ago* (BP has paid around $13 $27 billion in fines and compensation), and April 20, 2014, is the deadline to properly file forms for new compensations.
(*After which BP had another small spill in Lake Michigan.)
But what happened to the 200 million gallons of oil? Has it vanished or just sunk to the bottom of the sea by dispersants which may have caused hidden destruction of sea life? I don’t know, but given it’s Saturday night, let’s listen in to a reblog of a spill-related variation on the second of two original “overheard at the comedy hour” jokes.
Categories: Comedy, Statistics
8 Comments
Duality: Confidence intervals and the severity of tests
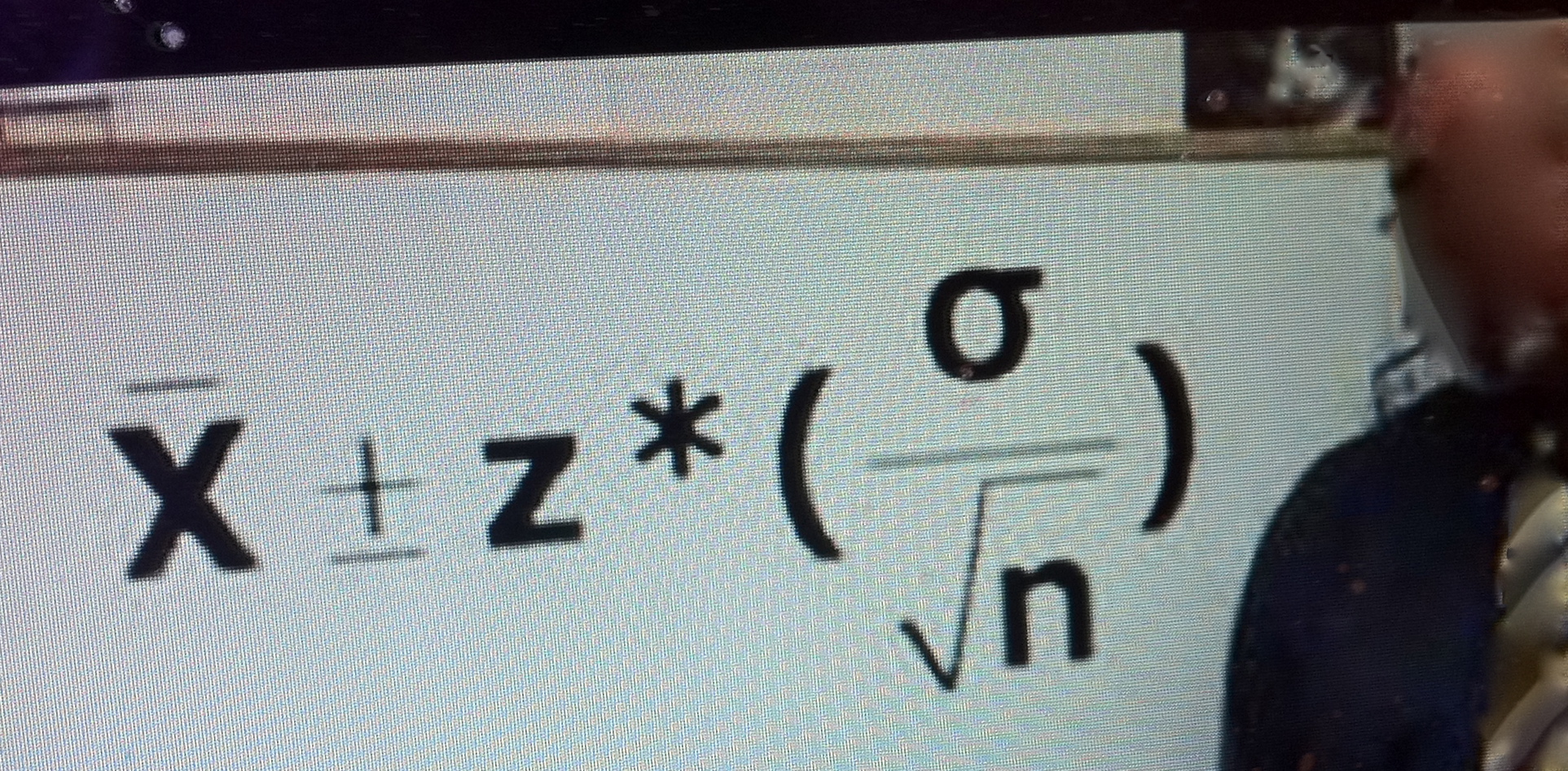 A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer: Continue reading
A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer: Continue reading
Categories: confidence intervals and tests, Phil6334
Leave a comment
A. Spanos: Jerzy Neyman and his Enduring Legacy
 A Statistical Model as a Chance Mechanism
A Statistical Model as a Chance Mechanism
Aris Spanos
Jerzy Neyman (April 16, 1894 – August 5, 1981), was a Polish/American statistician[i] who spent most of his professional career at the University of California, Berkeley. Neyman is best known in statistics for his pioneering contributions in framing the Neyman-Pearson (N-P) optimal theory of hypothesis testing and his theory of Confidence Intervals. (This article was first posted here.)

Neyman: 16 April 1894 – 5 Aug 1981
One of Neyman’s most remarkable, but least recognized, achievements was his adapting of Fisher’s (1922) notion of a statistical model to render it pertinent for non-random samples. Continue reading
Categories: phil/history of stat, Spanos, Statistics
Tags: frequentist statistics, Spanos
4 Comments
Phil 6334: Notes on Bayesian Inference: Day #11 Slides

.
A. Spanos Probability/Statistics Lecture Notes 7: An Introduction to Bayesian Inference (4/10/14)
Categories: Bayesian/frequentist, Phil 6334 class material, Statistics
11 Comments
“Murder or Coincidence?” Statistical Error in Court: Richard Gill (TEDx video)
 “There was a vain and ambitious hospital director. A bad statistician. ..There were good medics and bad medics, good nurses and bad nurses, good cops and bad cops … Apparently, even some people in the Public Prosecution service found the witch hunt deeply disturbing.”
“There was a vain and ambitious hospital director. A bad statistician. ..There were good medics and bad medics, good nurses and bad nurses, good cops and bad cops … Apparently, even some people in the Public Prosecution service found the witch hunt deeply disturbing.”
This is how Richard Gill, statistician at Leiden University, describes a feature film (Lucia de B.) just released about the case of Lucia de Berk, a nurse found guilty of several murders based largely on statistics. Gill is widely-known (among other things) for showing the flawed statistical analysis used to convict her, which ultimately led (after Gill’s tireless efforts) to her conviction being revoked. (I hope they translate the film into English.) In a recent e-mail Gill writes:
“The Dutch are going into an orgy of feel-good tear-jerking sentimentality as a movie comes out (the premiere is tonight) about the case. It will be a good movie, actually, but it only tells one side of the story. …When a jumbo jet goes down we find out what went wrong and prevent it from happening again. The Lucia case was a similar disaster. But no one even *knows* what went wrong. It can happen again tomorrow.
I spoke about it a couple of days ago at a TEDx event (Flanders).
You can find some p-values in my slides [“Murder by Numbers”, pasted below the video]. They were important – first in convicting Lucia, later in getting her a fair re-trial.”
Since it’s Saturday night, let’s watch Gill’s TEDx talk, “Statistical Error in court”.
Slides from the Talk: “Murder by Numbers”:
Categories: junk science, P-values, PhilStatLaw, science communication, Statistics
Tags: Richard Gill
Leave a comment
“Out Damned Pseudoscience: Non-significant results are the new ‘Significant’ results!” (update)

Sell me that antiseptic!
We were reading “Out, Damned Spot: Can the ‘Macbeth effect’ be replicated?” (Earp,B., Everett,J., Madva,E., and Hamlin,J. 2014, in Basic and Applied Social Psychology 36: 91-8) in an informal gathering of our 6334 seminar yesterday afternoon at Thebes. Some of the graduate students are interested in so-called “experimental” philosophy, and I asked for an example that used statistics for purposes of analysis. The example–and it’s a great one (thanks Rory M!)–revolves around priming research in social psychology. Yes the field that has come in for so much criticism as of late, especially after Diederik Stapel was found to have been fabricating data altogether (search this blog, e.g., here).[1] Continue reading
Categories: fallacy of non-significance, junk science, reformers, Statistics
15 Comments
Phil 6334: Duhem’s Problem, highly probable vs highly probed; Day #9 Slides
April 3, 2014: We interspersed discussion with slides; these cover the main readings of the day (check syllabus): the Duhem’s Problem and the Bayesian Way, and “Highly probable vs Highly Probed”. syllabus four. Slides are below (followers of this blog will be familiar with most of this, e.g., here). We also did further work on misspecification testing.
Monday, April 7, is an optional outing, “a seminar class trip”

“Thebes”, Blacksburg, VA
you might say, here at Thebes at which time we will analyze the statistical curves of the mountains, pie charts of pizza, and (seriously) study some experiments on the problem of replication in “the Hamlet Effect in social psychology”. If you’re around please bop in!
Mayo’s slides on Duhem’s Problem and more from April 3 (Day#9):
Who is allowed to cheat? I.J. Good and that after dinner comedy hour….
 It was from my Virginia Tech colleague I.J. Good (in statistics), who died five years ago (April 5, 2009), at 93, that I learned most of what I call “howlers” on this blog. His favorites were based on the “paradoxes” of stopping rules. (I had posted this last year here.)
It was from my Virginia Tech colleague I.J. Good (in statistics), who died five years ago (April 5, 2009), at 93, that I learned most of what I call “howlers” on this blog. His favorites were based on the “paradoxes” of stopping rules. (I had posted this last year here.)
“In conversation I have emphasized to other statisticians, starting in 1950, that, in virtue of the ‘law of the iterated logarithm,’ by optional stopping an arbitrarily high sigmage, and therefore an arbitrarily small tail-area probability, can be attained even when the null hypothesis is true. In other words if a Fisherian is prepared to use optional stopping (which usually he is not) he can be sure of rejecting a true null hypothesis provided that he is prepared to go on sampling for a long time. The way I usually express this ‘paradox’ is that a Fisherian [but not a Bayesian] can cheat by pretending he has a plane to catch like a gambler who leaves the table when he is ahead” (Good 1983, 135) [*]
Categories: Bayesian/frequentist, Comedy, Statistics
Tags: argument from intentions, frequentist criticisms, Stopping rules
18 Comments
Self-referential blogpost (conditionally accepted*)
This is a blogpost on a talk (by Jeremy Fox) on blogging that will be live tweeted here at Virginia Tech on Monday April 7, and the moment I post this blog on “Blogging as a Mode of Scientific Communication” it will be tweeted. Live.
Jeremy’s upcoming talk on blogging will be live-tweeted by @FisheriesBlog, 1 pm EDT Apr. 7
Posted on April 3, 2014 by Jeremy Fox
If you like to follow live tweets of talks, you’re in luck: my upcoming Virginia Tech talk on blogging will be live tweeted by Brandon Peoples, a grad student there who co-authors The Fisheries Blog. Follow @FisheriesBlog at 1 pm US Eastern Daylight Time on Monday, April 7 for the live tweets.
Jeremy Fox’s excellent blog, “Dynamic Ecology,” often discusses matters statistical from a perspective in sync with error statistics.
I’ve never been invited to talk about blogging or even to blog about blogging, maybe this is a new trend. I look forward to meeting him (live!).

* Posts that don’t directly pertain to philosophy of science/statistics are placed under “rejected posts” but since this is a metablogpost on a talk on a blog pertaining to statistics it has been “conditionally accepted”, unconditionally, i.e., without conditions.
Categories: Announcement, Metablog
Leave a comment
Skeptical and enthusiastic Bayesian priors for beliefs about insane asylum renovations at Dept of Homeland Security: I’m skeptical and unenthusiastic

Danvers State Hospital
I had heard of medical designs that employ individuals who supply Bayesian subjective priors that are deemed either “enthusiastic” or “skeptical” as regards the probable value of medical treatments.[i] From what I gather, these priors are combined with data from trials in order to help decide whether to stop trials early or continue. But I’d never heard of these Bayesian designs in relation to decisions about building security or renovations! Listen to this…. Continue reading
Categories: junk science, Statistics
11 Comments

The Statistics Wars & Their Casualties

LSE PH500 Research Seminar (May 21-June 25, 2020): Controversies in Phil Stat
")
Summer Seminar 2019 (article)

Experts convene to explore new philosophy of statistics field
