
 Day #2, Part 1: D. Mayo:
Day #2, Part 1: D. Mayo:
Class, Part 2: A. Spanos:
Probability/Statistics Lecture Notes 1: Introduction to Probability and Statistical Inference
Day #1 slides are here.
Day #2, Part 1: D. Mayo:
Class, Part 2: A. Spanos:
Probability/Statistics Lecture Notes 1: Introduction to Probability and Statistical Inference
Day #1 slides are here.

Download the 54th Annual Program
REVISITING THE FOUNDATIONS OF STATISTICS IN THE ERA OF BIG DATA: SCALING UP TO MEET THE CHALLENGE
Cosponsored by the Department of Mathematics & Statistics at Boston University.
Friday, February 21, 2014
10 a.m. – 5:30 p.m.
Photonics Center, 9th Floor Colloquium Room (Rm 906)
8 St. Mary’s Street
10 a.m.–noon
1:30–5:30 p.m.
Panel Discussion

 Winner of the January 2014 Palindrome Context
Winner of the January 2014 Palindrome Context
Karthik Durvasula
Visiting Assistant Professor in Phonology & Phonetics at Michigan State University
Palindrome: Test’s optimal? Agreed! Able to honor? O no! Hot Elba deer gala. MIT-post set.
The requirement was: A palindrome with “optimal” and “Elba”.
Bio: I’m a Visiting Assistant Professor in Phonology & Phonetics at Michigan State University. My work primarily deals with probing people’s subconscious knowledge of (abstract) sound patterns. Recently, I have been working on auditory illusions that stem from the bias that such subconscious knowledge introduces.
Statement: “Trying to get a palindrome that was at least partially meaningful was fun and challenging. Plus I get an awesome book for my efforts. What more could a guy ask for! I also want to thank Mayo for being excellent about email correspondence, and answering my (sometimes silly) questions tirelessly.”
Book choice: EGEK 1996! 🙂
[i.e.,Mayo (1996): “Error and the Growth of Experimental Knowledge”]
CONGRATULATIONS! And thanks so much for your interest!
February contest: Elba plus deviate (deviation)*
New Rule: Using both deviate and deviant tops an acceptable palindrome that only uses deviate (but can earn 1/2 prize voucher for doubling on another month).
On weekends this spring (in connection with Phil 6334, but not limited to seminar participants) I will post relevant “comedy hours”, invites to analyze short papers or blogs (“U-Phils”, as in “U-philosophize”), and some of my “deconstructions” of articles. To begin with a “U-Phil”, consider a note by Andrew Gelman: “Ethics and the statistical use of prior information,”[i].
 I invite you to send (to error@vt.edu) informal analyses (“U-Phil”, ~500-750 words) by February 10) [iv]. Indicate if you want your remarks considered for possible posting on this blog.
I invite you to send (to error@vt.edu) informal analyses (“U-Phil”, ~500-750 words) by February 10) [iv]. Indicate if you want your remarks considered for possible posting on this blog.
Writing philosophy differs from other types of writing: Some links to earlier U-Phils are here. Also relevant is this note: “So you want to do a philosophical analysis?”
U-Phil (2/10/14): In section 3 Gelman comments on some of David Cox’s remarks in a (highly informal and non-scripted) conversation we recorded:
“A Statistical Scientist Meets a Philosopher of Science: A Conversation between Sir David Cox and Deborah Mayo,” published in Rationality, Markets and Morals [iii] (Section 2 has some remarks on Larry Wasserman, by the way.)
Here’s the relevant portion of the conversation:
COX: Deborah, in some fields foundations do not seem very important, but we both think foundations of statistical inference are important; why do you think that is?
MAYO: I think because they ask about fundamental questions of evidence, inference, and probability. I don’t think that foundations of different fields are all alike; because in statistics we’re so intimately connected to the scientific interest in learning about the world, we invariably cross into philosophical questions about empirical knowledge and inductive inference.
COX: One aspect of it is that it forces us to say what it is that we really want to know when we analyze a situation statistically. Do we want to put in a lot of information external to the data, or as little as possible. It forces us to think about questions of that sort.
MAYO: But key questions, I think, are not so much a matter of putting in a lot or a little information. …What matters is the kind of information, and how to use it to learn. This gets to the question of how we manage to be so successful in learning about the world, despite knowledge gaps, uncertainties and errors. To me that’s one of the deepest questions and it’s the main one I care about. I don’t think a (deductive) Bayesian computation can adequately answer it.…..
COX: There’s a lot of talk about what used to be called inverse probability and is now called Bayesian theory. That represents at least two extremely different approaches. How do you see the two? Do you see them as part of a single whole? Or as very different? Continue reading
 First installment 6334 syllabus (Mayo and Spanos)
First installment 6334 syllabus (Mayo and Spanos)
D. Mayo slides from Day #1: Jan 23, 2014
I will post seminar slides here (they will generally be ragtag affairs), links to the papers are in the syllabus.
FURTHER UPDATED: New course for Spring 2014: Thurs 3:30-6:15 (Randolph 209)
first installment 6334 syllabus_SYLLABUS (first) Phil 6334: Philosophy of Statistical Inference and Modeling

D. Mayo and A. Spanos
Contact: error@vt.edu
This new course, to be jointly taught by Professors D. Mayo (Philosophy) and A. Spanos (Economics) will provide an introductory, in-depth introduction to graduate level research in philosophy of inductive-statistical inference and probabilistic methods of evidence (a branch of formal epistemology). We explore philosophical problems of confirmation and induction, the philosophy and history of frequentist and Bayesian approaches, and key foundational controversies surrounding tools of statistical data analytics, modeling and hypothesis testing in the natural and social sciences, and in evidence-based policy.
We now have some tentative topics and dates:
| 1. 1/23 | Introduction to the Course: 4 waves of controversy in the philosophy of statistics |
| 2. 1/30 | How to tell what’s true about statistical inference: Probabilism, performance and probativeness |
| 3. 2/6 | Induction and Confirmation: Formal Epistemology |
| 4. 2/13 | Induction, falsification, severe tests: Popper and Beyond |
| 5. 2/20 | Statistical models and estimation: the Basics |
| 6. 2/27 | Fundamentals of significance tests and severe testing |
| 7. 3/6 | Five sigma and the Higgs Boson discovery Is it “bad science”? |
| SPRING BREAK Statistical Exercises While Sunning | |
| 8. 3/20 | Fraudbusting and Scapegoating: Replicability and big data: are most scientific results false? |
| 9. 3/27 | How can we test the assumptions of statistical models? All models are false; no methods are objective: Philosophical problems of misspecification testing: Spanos method |
| 10. 4/3 | Fundamentals of Statistical Testing: Family Feuds and 70 years of controversy |
| 11. 4/10 | Error Statistical Philosophy: Highly Probable vs Highly Probed Some howlers of testing |
| 12. 4/17 | What ever happened to Bayesian Philosophical Foundations? Dutch books etc. Fundamental of Bayesian statistics |
| 13. 4/24 | Bayesian-frequentist reconciliations, unifications, and O-Bayesians |
| 14. 5/1 | Overview: Answering the critics: Should statistical philosophy be divorced from methodology? |
| (15. TBA) | Topic to be chosen (Resampling statistics and new journal policies? Likelihood principle) |
Interested in attending? E.R.R.O.R.S.* can fund travel (presumably driving) and provide accommodation for Thurs. night in a conference lodge in Blacksburg for a few people through (or part of) the semester. If interested, write ASAP for details (with a brief description of your interest and background) to error@vt.edu. (Several people asked about long-distance hook-ups: We will try to provide some sessions by Skype, and will put each of the seminar items here (also check the Phil6334 page on this blog).
A sample of questions we consider*:
D. Mayo (books):
How to Tell What’s True About Statistical Inference, (Cambridge, in progress).
Error and the Growth of Experimental Knowledge, Chicago: Chicago University Press, 1996. (Winner of 1998 Lakatos Prize).
Acceptable Evidence: Science and Values in Risk Management, co-edited with Rachelle Hollander, New York: Oxford University Press, 1994.
Aris Spanos (books):
Probability Theory and Statistical Inference, Cambridge, 1999.
Statistical Foundations of Econometric Modeling, Cambridge, 1986.
Joint (books): Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability and the Objectivity and Rationality of Science, D. Mayo & A. Spanos (eds.), Cambridge: Cambridge University Press, 2010. [Intro, Background & Chapter 1. (The book includes both papers and exchanges between Mayo and A. Chalmers, A. Musgrave, P. Achinstein, J. Worrall, C. Glymour, A. Spanos, and joint papers with Mayo and Sir David Cox)].
![]() You might not have thought there could be new material for 2014, but there is, and if you look a bit more closely, you’ll see that it’s actually not Jay Leno who is standing up there at the mike ….
You might not have thought there could be new material for 2014, but there is, and if you look a bit more closely, you’ll see that it’s actually not Jay Leno who is standing up there at the mike ….
 It’s Sir Harold Jeffreys himself! And his (very famous) joke, I admit, is funny. So, since it’s Saturday night, let’s listen in on Sir Harold’s howler* in criticizing the use of p-values.
It’s Sir Harold Jeffreys himself! And his (very famous) joke, I admit, is funny. So, since it’s Saturday night, let’s listen in on Sir Harold’s howler* in criticizing the use of p-values.
“Did you hear the one about significance testers rejecting H0 because of outcomes H0 didn’t predict?
‘What’s unusual about that?’ you ask?
Well, what’s unusual, is that they do it when these unpredicted outcomes haven’t even occurred!”
Much laughter.
[The actual quote from Jeffreys: Using p-values implies that “An hypothesis that may be true is rejected because it has failed to predict observable results that have not occurred. This seems a remarkable procedure.” (Jeffreys 1939, 316)]
I say it’s funny, so to see why I’ll strive to give it a generous interpretation.
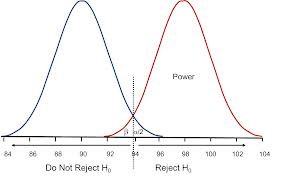
We can view p-values in terms of rejecting H0, as in the joke: There’s a test statistic D such that H0 is rejected if its observed value d0 reaches or exceeds a cut-off d* where Pr(D > d*; H0) is small, say .025.
Reject H0 if Pr(D > d0; H0) < .025.
The report might be “reject H0 at level .025″.
Example: H0: The mean light deflection effect is 0. So if we observe a 1.96 standard deviation difference (in one-sided Normal testing) we’d reject H0 .
Now it’s true that if the observation were further into the rejection region, say 2, 3 or 4 standard deviations, it too would result in rejecting the null, and with an even smaller p-value. It’s also true that H0 “has not predicted” a 2, 3, 4, 5 etc. standard deviation difference in the sense that differences so large are “far from” or improbable under the null. But wait a minute. What if we’ve only observed a 1 standard deviation difference (p-value = .16)? It is unfair to count it against the null that 1.96, 2, 3, 4 etc. standard deviation differences would have diverged seriously from the null, when we’ve only observed the 1 standard deviation difference. Yet the p-value tells you to compute Pr(D > 1; H0), which includes these more extreme outcomes! This is “a remarkable procedure” indeed! [i]
So much for making out the howler. The only problem is that significance tests do not do this, that is, they do not reject with, say, D = 1 because larger D values might have occurred (but did not). D = 1 does not reach the cut-off, and does not lead to rejecting H0. Moreover, looking at the tail area makes it harder, not easier, to reject the null (although this isn’t the only function of the tail area): since it requires not merely that Pr(D = d0 ; H0 ) be small, but that Pr(D > d0 ; H0 ) be small. And this is well justified because when this probability is not small, you should not regard it as evidence of discrepancy from the null. Before getting to this …. Continue reading
 Andrew Gelman says that as a philosopher, I should appreciate his blog today in which he records his frustration: “Against aggressive definitions: No, I don’t think it helps to describe Bayes as ‘the analysis of subjective beliefs’…” Gelman writes:
Andrew Gelman says that as a philosopher, I should appreciate his blog today in which he records his frustration: “Against aggressive definitions: No, I don’t think it helps to describe Bayes as ‘the analysis of subjective beliefs’…” Gelman writes:
I get frustrated with what might be called “aggressive definitions,” where people use a restrictive definition of something they don’t like. For example, Larry Wasserman writes (as reported by Deborah Mayo):
“I wish people were clearer about what Bayes is/is not and what frequentist inference is/is not. Bayes is the analysis of subjective beliefs but provides no frequency guarantees. Frequentist inference is about making procedures that have frequency guarantees but makes no pretense of representing anyone’s beliefs.”
I’ll accept Larry’s definition of frequentist inference. But as for his definition of Bayesian inference: No no no no no. The probabilities we use in our Bayesian inference are not subjective, or, they’re no more subjective than the logistic regressions and normal distributions and Poisson distributions and so forth that fill up all the textbooks on frequentist inference.
To quickly record some of my own frustrations:*: First, I would disagree with Wasserman’s characterization of frequentist inference, but as is clear from Larry’s comments to (my reaction to him), I think he concurs that he was just giving a broad contrast. Please see Note [1] for a remark from my post: Comments on Wasserman’s “what is Bayesian/frequentist inference?” Also relevant is a Gelman post on the Bayesian name: [2].
Second, Gelman’s “no more subjective than…” evokes remarks I’ve made before. For example, in “What should philosophers of science do…” I wrote:
Arguments given for some very popular slogans (mostly by non-philosophers), are too readily taken on faith as canon by others, and are repeated as gospel. Examples are easily found: all models are false, no models are falsifiable, everything is subjective, or equally subjective and objective, and the only properly epistemological use of probability is to supply posterior probabilities for quantifying actual or rational degrees of belief. Then there is the cluster of “howlers” allegedly committed by frequentist error statistical methods repeated verbatim (discussed on this blog).
I’ve written a lot about objectivity on this blog, e.g., here, here and here (and in real life), but what’s the point if people just rehearse the “everything is a mixture…” line, without making deeply important distinctions? I really think that, next to the “all models are false” slogan, the most confusion has been engendered by the “no methods are objective” slogan. However much we may aim at objective constraints, it is often urged, we can never have “clean hands” free of the influence of beliefs and interests, and we invariably sully methods of inquiry by the entry of background beliefs and personal judgments in their specification and interpretation. Continue reading
 “StatSci meets PhilSci”. (1/14/14)
“StatSci meets PhilSci”. (1/14/14)
As “Wasserman on Wasserman” (and links within) continues to rack up record hits (N.D.: you see you shouldn’t quit blogging)*, I’ve been asked about the origins of his and related discussions on this blog. For a quick answer:** many grew out of attempts to tackle the general question: “Statistical Science and Philosophy of Science: Where Do (Should) They meet?”–the title of a conference I organized (with A. Spanos***) at the London School of Economics, Center for the Philosophy of Natural and Social Science, CPNSS, in June 2010. In tackling this question, errorstatistics.com regularly returns to a set of contributions stemming from the conference, and conversations initiated soon after (with Andrew Gelman and Larry Wasserman)****. The conference site is here. My reflections in this general arena (Sept. 26, 2012) are here.
Opening with an informal (recorded) exchange: “A statistical scientist meets a philosopher of science: a conversation between Sir David Cox and Deborah Mayo”, this special topic of the on-line journal, Rationality, Markets and Morals (RMM), edited by Max Albert[i],—also a conference participant —has been an excellent home for continual updates (to which we may return at some point!)
Authors are: David Cox, Andrew Gelman, David F. Hendry, Deborah G. Mayo, Stephen Senn, Aris Spanos, Jan Sprenger, Larry Wasserman
To those who ask me what to read as background to some of the issues, have a look at those contributions. Many of them are discussed in specific blogposts (with “deconstructions” [by me], responses by authors, and insightful “U-Phil” analyses by readers) and comments.[ii]. (Search under U-Phil.) I have gathered a list of issues that we either haven’t taken up, or need to return to.
Here is the RMM blub:
Rationality, Markets and Morals: Studies at the Intersection of Philosophy and Economics
Guest Editors: Deborah G. Mayo, Aris Spanos and Kent W. StaleyStatistical Science Meets Philosophy of Science: The Two-Way Street
At one level of analysis, statisticians and philosophers of science ask many of the same questions: What should be observed and what may justifiably be inferred from the resulting data? How well-tested or confirmed are hypotheses with data? How can statistical models and methods bridge the gaps between data and scientific claims of interest? These general questions are entwined with long standing philosophical debates, so it is no wonder that the statistics crosses over so often into philosophical territory.
The “meeting grounds” of statistical science and philosophy of science are or should be connected by a two-way street: while general philosophical questions about evidence and inference bear on statistical questions (about methods to use, and how to interpret them), statistical methods bear on philosophical problems about inference and knowledge. As interesting as this two-way street has been over many years, we seem to be in need of some entirely new traffic patterns! That is the basis for this forum.
[i] Along with Hartmut Kliemt and Bernd Lahno.
[ii] The “deconstruction” activity on this blog began with my reaction to a paper by Jim Berger, in a recently reblogged post. Berger had replied in ‘Jim Berger on Jim Berger’.
*From the WordPress 2013 “annual report”: The busiest day of the year was February 18th. The most popular post that day was R. A. Fisher: how an outsider revolutionized statistics.
Also attracting huge hits was the guest post by Larry Laudan: Why Presuming Innocence is Not a Bayesian Prior: https://errorstatistics.com/2013/07/20/guest-post-larry-laudan-why-presuming-innocence-is-not-a-bayesian-prior/ Many other biggies (especially from guest posters) have attracted a large number of comments and views.
** This post adapts an earlier one here. This blog is on philosophy, after all: only careful and frequent rereading brings illumination.
***For a full list of collaborators, sponsors, logisticians, and related collaborations, see the conference page. The full list of speakers is found there as well. Should we do a 2015 update? or wait for ERROR 2016?
****Conference participants who never got around to sending papers: I think there’s still time.
 The blog “It’s Chancy” (Corey Yanofsky) has a post today about “two severities” which warrants clarification. Two distinctions are being blurred: between formal and informal severity assessments, and between a statistical philosophy (something Corey says he’s interested in) and its relevance to philosophy of science (which he isn’t). I call the latter an error statistical philosophy of science. The former requires both formal, semi-formal and informal severity assessments. Here’s his post:
The blog “It’s Chancy” (Corey Yanofsky) has a post today about “two severities” which warrants clarification. Two distinctions are being blurred: between formal and informal severity assessments, and between a statistical philosophy (something Corey says he’s interested in) and its relevance to philosophy of science (which he isn’t). I call the latter an error statistical philosophy of science. The former requires both formal, semi-formal and informal severity assessments. Here’s his post:
In the comments to my first post on severity, Professor Mayo noted some apparent and some actual misstatements of her views.To avert misunderstandings, she directed readers to two of her articles, one of which opens by making this distinction:
“Error statistics refers to a standpoint regarding both (1) a general philosophy of science and the roles probability plays in inductive inference, and (2) a cluster of statistical tools, their interpretation, and their justification.”
In Mayo’s writings I see two interrelated notions of severity corresponding to the two items listed in the quote: (1) an informal severity notion that Mayo uses when discussing philosophy of science and specific scientific investigations, and (2) Mayo’s formalization of severity at the data analysis level.
One of my besetting flaws is a tendency to take a narrow conceptual focus to the detriment of the wider context. In the case of Severity, part one, I think I ended up making claims about severity that were wrong. I was narrowly focused on severity in sense (2) — in fact, on one specific equation within (2) — but used a mish-mash of ideas and terminology drawn from all of my readings of Mayo’s work. When read through a philosophy-of-science lens, the result is a distorted and misstated version of severity in sense (1) .
As a philosopher of science, I’m a rank amateur; I’m not equipped to add anything to the conversation about severity as a philosophy of science. My topic is statistics, not philosophy, and so I want to warn readers against interpreting Severity, part one as a description of Mayo’s philosophy of science; it’s more of a wordy introduction to the formal definition of severity in sense (2).[It’s Chancy, Jan 11, 2014)
A needed clarification may be found in a post of mine which begins:
Error statistics: (1) There is a “statistical philosophy” and a philosophy of science. (a) An error-statistical philosophy alludes to the methodological principles and foundations associated with frequentist error-statistical methods. (b) An error-statistical philosophy of science, on the other hand, involves using the error-statistical methods, formally or informally, to deal with problems of philosophy of science: to model scientific inference (actual or rational), to scrutinize principles of inference, and to address philosophical problems about evidence and inference (the problem of induction, underdetermination, warranting evidence, theory testing, etc.).
I assume the interest here* is on the former, (a). I have stated it in numerous ways, but the basic position is that inductive inference—i.e., data-transcending inference—calls for methods of controlling and evaluating error probabilities (even if only approximate). An inductive inference, in this conception, takes the form of inferring hypotheses or claims to the extent that they have been well tested. It also requires reporting claims that have not passed severely, or have passed with low severity. In the “severe testing” philosophy of induction, the quantitative assessment offered by error probabilities tells us not “how probable” but, rather, “how well probed” hypotheses are. The local canonical hypotheses of formal tests and estimation methods need not be the ones we entertain post data; but they give us a place to start without having to go “the designer-clothes” route.
The post-data interpretations might be formal, semi-formal, or informal.
See also: Staley’s review of Error and Inference (Mayo and Spanos eds.)
New course for Spring 2014: Thursday 3:30-6:15
 Phil 6334: Philosophy of Statistical Inference and Modeling
Phil 6334: Philosophy of Statistical Inference and Modeling
D. Mayo and A. Spanos
Contact: error@vt.edu
This new course, to be jointly taught by Professors D. Mayo (Philosophy) and A. Spanos (Economics) will provide an introductory, in-depth introduction to graduate level research in philosophy of inductive-statistical inference and probabilistic methods of evidence (a branch of formal epistemology). We explore philosophical problems of confirmation and induction, the philosophy and history of frequentist and Bayesian approaches, and key foundational controversies surrounding tools of statistical data analytics, modeling and hypothesis testing in the natural and social sciences, and in evidence-based policy.
A sample of questions we consider*:
Interested in attending? E.R.R.O.R.S.* can fund travel (presumably driving) and provide lodging for Thurs. night in a conference lodge in Blacksburg for a few people through (or part of) the semester. Topics will be posted over the next week, but if you might be interested, write ASAP for details (with a brief description of your interest and background) to error@vt.edu.
*This course will be a brand new version of related seminar we’ve led in the past, so we don’t have the syllabus set yet. We’re going to try something different this time. I’ll be updating in subsequent installments to the blog.
Dates: January 23, 30; February 6, 13, 20, 27; March 6, [March 8-16 break], 20, 27; April 3,10, 17, 24; May 1
D. Mayo (books):
How to Tell What’s True About Statistical Inference, (Cambridge, in progress).
Error and the Growth of Experimental Knowledge, Chicago: Chicago University Press, 1996. (Winner of 1998 Lakatos Prize).
Acceptable Evidence: Science and Values in Risk Management, co-edited with Rachelle Hollander, New York: Oxford University Press, 1994.
Aris Spanos (books):
Probability Theory and Statistical Inference, Cambridge, 1999.
Statistical Foundations of Econometric Modeling, Cambridge, 1986.
Joint (books): Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability and the Objectivity and Rationality of Science, D. Mayo & A. Spanos (eds.), Cambridge: Cambridge University Press, 2010. [Intro, Background & Chapter 1. (The book includes both papers and exchanges between Mayo and A. Chalmers, A. Musgrave, P. Achinstein, J. Worrall, C. Glymour, A. Spanos, and joint papers with Mayo and Sir David Cox)].
 A reader asks how I would complete the following sentence:
A reader asks how I would complete the following sentence:
I wish that new articles* written in 2014 would refrain from_______.
Here are my quick answers, in no special order:
(a) rehearsing the howlers of significance tests and other frequentist statistical methods;
(b) misinterpreting p-values, ignoring discrepancy assessments (and thus committing fallacies of rejection and non-rejection);
(c) confusing an assessment of boosts in belief (or support) in claim H ,with assessing what (if anything) has been done to ensure/increase the severity of the tests H passes;
(d) declaring that “what we really want” are posterior probability assignments in statistical hypotheses without explaining what they would mean, and why we should want them;
(e) promoting the myth that frequentist tests (and estimates) form an inconsistent hybrid of incompatible philosophies (from Fisher and Neyman-Pearson);
(f) presupposing that a relevant assessment of the scientific credentials of research would be an estimate of the percentage of null hypothesis that are “true” (selected from an “urn of nulls”) given they are rejectable with a low p-value in an “up-down” use of tests;
(g) sidestepping the main sources of pseudoscience: insevere tests through interpretational and inferential latitude, and violations of statistical model assumptions.
The “2014 wishing well” stands ready for your sentence completions.
*The question alluded to articles linked with philosophy & methodology of statistical science.

I blog ergo I blog
Error Statistics Philosophy: 2013
Organized by Nicole Jinn & Jean Anne Miller*
January 2013
(1/2) Severity as a ‘Metastatistical’ Assessment
(1/4) Severity Calculator
(1/6) Guest post: Bad Pharma? (S. Senn)
(1/9) RCTs, skeptics, and evidence-based policy
(1/10) James M. Buchanan
(1/11) Aris Spanos: James M. Buchanan: a scholar, teacher and friend
(1/12) Error Statistics Blog: Table of Contents
(1/15) Ontology & Methodology: Second call for Abstracts, Papers![]()
(1/18) New Kvetch/PhilStock
(1/19) Saturday Night Brainstorming and Task Forces: (2013) TFSI on NHST
(1/22) New PhilStock
(1/23) P-values as posterior odds?
(1/26) Coming up: December U-Phil Contributions….
(1/27) U-Phil: S. Fletcher & N.Jinn
(1/30) U-Phil: J. A. Miller: Blogging the SLP
February 2013
(2/2) U-Phil: Ton o’ Bricks
(2/4) January Palindrome Winner
(2/6) Mark Chang (now) gets it right about circularity
(2/8) From Gelman’s blog: philosophy and the practice of Bayesian statistics
(2/9) New kvetch: Filly Fury
(2/10) U-PHIL: Gandenberger & Hennig: Blogging Birnbaum’s Proof
(2/11) U-Phil: Mayo’s response to Hennig and Gandenberger
(2/13) Statistics as a Counter to Heavyweights…who wrote this?
(2/16) Fisher and Neyman after anger management?
(2/17) R. A. Fisher: how an outsider revolutionized statistics
(2/20) Fisher: from ‘Two New Properties of Mathematical Likelihood’
(2/23) Stephen Senn: Also Smith and Jones
(2/26) PhilStock: DO < $70
(2/26) Statistically speaking… Continue reading

")

Experts convene to explore new philosophy of statistics field


