
Slides from my March 17 presentation on “Severe Testing: The Key to Error Correction” given at the Boston Colloquium for Philosophy of Science Alfred I.Taub forum on “Understanding Reproducibility and Error Correction in Science.”
Slides from my March 17 presentation on “Severe Testing: The Key to Error Correction” given at the Boston Colloquium for Philosophy of Science Alfred I.Taub forum on “Understanding Reproducibility and Error Correction in Science.”

Download the 57th Annual Program
The Alfred I. Taub forum:
UNDERSTANDING REPRODUCIBILITY & ERROR CORRECTION IN SCIENCE
Cosponsored by GMS and BU’s BEST at Boston University.
Friday, March 17, 2017
1:00 p.m. – 5:00 p.m.
The Terrace Lounge, George Sherman Union
775 Commonwealth Avenue


I’m surprised it’s a year already since posting my published comments on the ASA Document on P-Values. Since then, there have been a slew of papers rehearsing the well-worn fallacies of tests (a tad bit more than the usual rate). Doubtless, the P-value Pow Wow raised people’s consciousnesses. I’m interested in hearing reader reactions/experiences in connection with the P-Value project (positive and negative) over the past year. (Use the comments, share links to papers; and/or send me something slightly longer for a possible guest post.)
Some people sent me a diagram from a talk by Stephen Senn (on “P-values and the art of herding cats”). He presents an array of different cat commentators, and for some reason Mayo cat is in the middle but way over on the left side,near the wall. I never got the key to interpretation. My contribution is below:
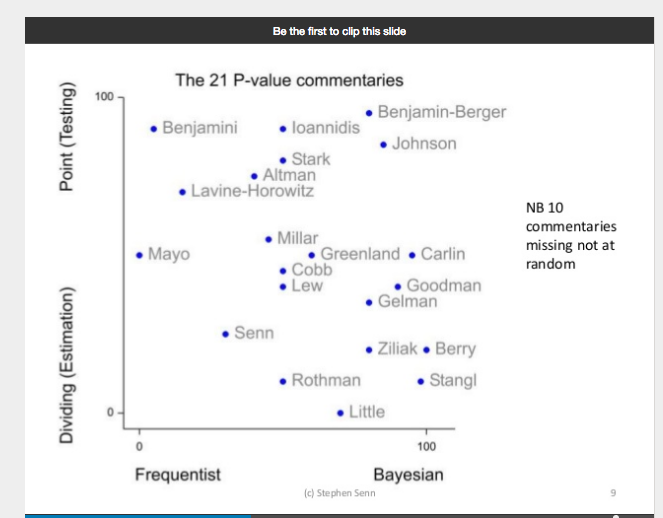
Chart by S.Senn
“Don’t Throw Out The Error Control Baby With the Bad Statistics Bathwater”
D. Mayo*[1]
The American Statistical Association is to be credited with opening up a discussion into p-values; now an examination of the foundations of other key statistical concepts is needed. Continue reading

")

Experts convene to explore new philosophy of statistics field


{kind=link}