
 “Probability/Statistics Lecture Notes 6: An Introduction to Mis-Specification (M-S) Testing” (Aris Spanos)
“Probability/Statistics Lecture Notes 6: An Introduction to Mis-Specification (M-S) Testing” (Aris Spanos)
[Other slides from Day 9 by guest, John Byrd, can be found here.]
“Probability/Statistics Lecture Notes 6: An Introduction to Mis-Specification (M-S) Testing” (Aris Spanos)
[Other slides from Day 9 by guest, John Byrd, can be found here.]
Winner of the March 2014 Palindrome Contest
Caitlin Parker
Palindrome:Able, we’d well aim on. I bet on a note. Binomial? Lewd. Ew, Elba!
The requirement was: A palindrome with Elba plus Binomial with an optional second word: bet. A palindrome that uses both Binomial and bet topped an acceptable palindrome that only uses Binomial.
Short bio:
Caitlin Parker is a first-year master’s student in the Philosophy department at Virginia Tech. Though her interests are in philosophy of science and statistics, she also has experience doing psychological research. Continue reading
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Central Identification Laboratory
JPAC
Guest, March 27, PHil 6334
“Statistical Considerations of the Histomorphometric Test Protocol for Determination of Human Origin of Skeletal Remains”
By:
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Maria-Teresa Tersigni-Tarrant, Ph.D.
Central Identification Laboratory
JPAC

.
We’re going to be discussing the philosophy of m-s testing today in our seminar, so I’m reblogging this from Feb. 2012. I’ve linked the 3 follow-ups below. Check the original posts for some good discussion. (Note visitor*)
“This is the kind of cure that kills the patient!”
is the line of Aris Spanos that I most remember from when I first heard him talk about testing assumptions of, and respecifying, statistical models in 1999. (The patient, of course, is the statistical model.) On finishing my book, EGEK 1996, I had been keen to fill its central gaps one of which was fleshing out a crucial piece of the error-statistical framework of learning from error: How to validate the assumptions of statistical models. But the whole problem turned out to be far more philosophically—not to mention technically—challenging than I imagined. I will try (in 3 short posts) to sketch a procedure that I think puts the entire process of model validation on a sound logical footing. Continue reading

Philosopher
“Philosophy majors rule” according to this recent article. We philosophers should be getting the word out. Admittedly, the type of people inclined to do well in philosophy are already likely to succeed in analytic areas. Coupled with the chuzpah of taking up an “outmoded and impractical” major like philosophy in the first place, innovative tendencies are not surprising. But can the study of philosophy also promote these capacities? I think it can and does; yet it could be far more effective than it is, if it was less hermetic and more engaged with problem-solving across the landscape of science,statistics,law,medicine,and evidence-based policy. Here’s the article: Continue reading

.
We spent the first half of Thursday’s seminar discussing the Fisher, Neyman, and E. Pearson “triad”[i]. So, since it’s Saturday night, join me in rereading for the nth time these three very short articles. The key issues were: error of the second kind, behavioristic vs evidential interpretations, and Fisher’s mysterious fiducial intervals. Although we often hear exaggerated accounts of the differences in the Fisherian vs Neyman-Pearson (NP) methodology, in fact, N-P were simply providing Fisher’s tests with a logical ground (even though other foundations for tests are still possible), and Fisher welcomed this gladly. Notably, with the single null hypothesis, N-P showed that it was possible to have tests where the probability of rejecting the null when true exceeded the probability of rejecting it when false. Hacking called such tests “worse than useless”, and N-P develop a theory of testing that avoids such problems. Statistical journalists who report on the alleged “inconsistent hybrid” (a term popularized by Gigerenzer) should recognize the extent to which the apparent disagreements on method reflect professional squabbling between Fisher and Neyman after 1935 [A recent example is a Nature article by R. Nuzzo in ii below]. The two types of tests are best seen as asking different questions in different contexts. They both follow error-statistical reasoning. Continue reading

Senn
Stephen Senn
Head, Methodology and Statistics Group,
Competence Center for Methodology and Statistics (CCMS),
Luxembourg
Delta Force
To what extent is clinical relevance relevant?
Inspiration
This note has been inspired by a Twitter exchange with respected scientist and famous blogger David Colquhoun. He queried whether a treatment that had 2/3 of an effect that would be described as clinically relevant could be useful. I was surprised at the question, since I would regard it as being pretty obvious that it could but, on reflection, I realise that things that may seem obvious to some who have worked in drug development may not be obvious to others, and if they are not obvious to others are either in need of a defence or wrong. I don’t think I am wrong and this note is to explain my thinking on the subject. Continue reading
 Karthik Durvasula, a blog follower[i], sent me a highly apt severity app that he created: https://karthikdurvasula.shinyapps.io/Severity_Calculator/
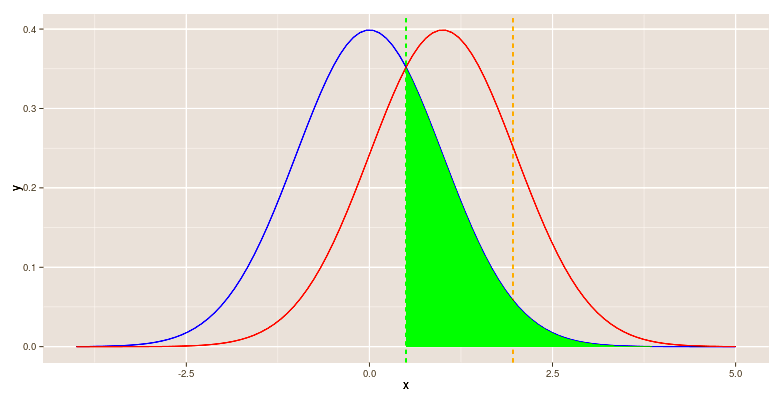
Karthik Durvasula, a blog follower[i], sent me a highly apt severity app that he created: https://karthikdurvasula.shinyapps.io/Severity_Calculator/ If a test’s power to detect µ’ is low then a statistically significant result is good/lousy evidence of discrepancy µ’? Which is it?
If a test’s power to detect µ’ is low then a statistically significant result is good/lousy evidence of discrepancy µ’? Which is it?
If your smoke alarm has little capability of triggering unless your house is fully ablaze, then if it has triggered, is that a strong or weak indication of a fire? Compare this insensitive smoke alarm to one that is so sensitive that burning toast sets it off. The answer is: that the alarm from the insensitive detector is triggered is a good indication of the presence of (some) fire, while hearing the ultra sensitive alarm go off is not.[i]
Yet I often hear people say things to the effect that: Continue reading
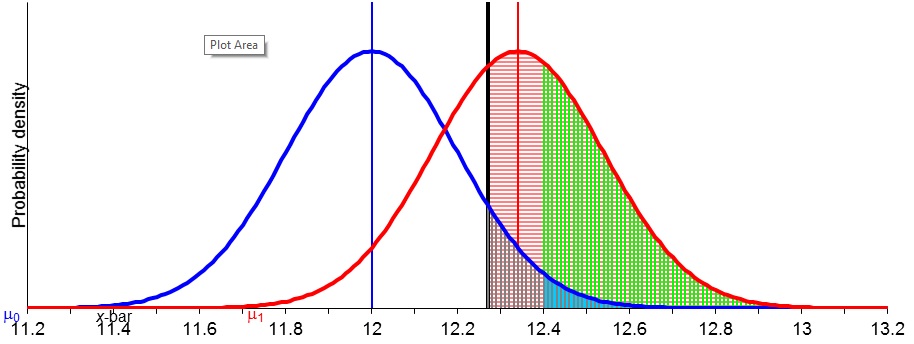 Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.
Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.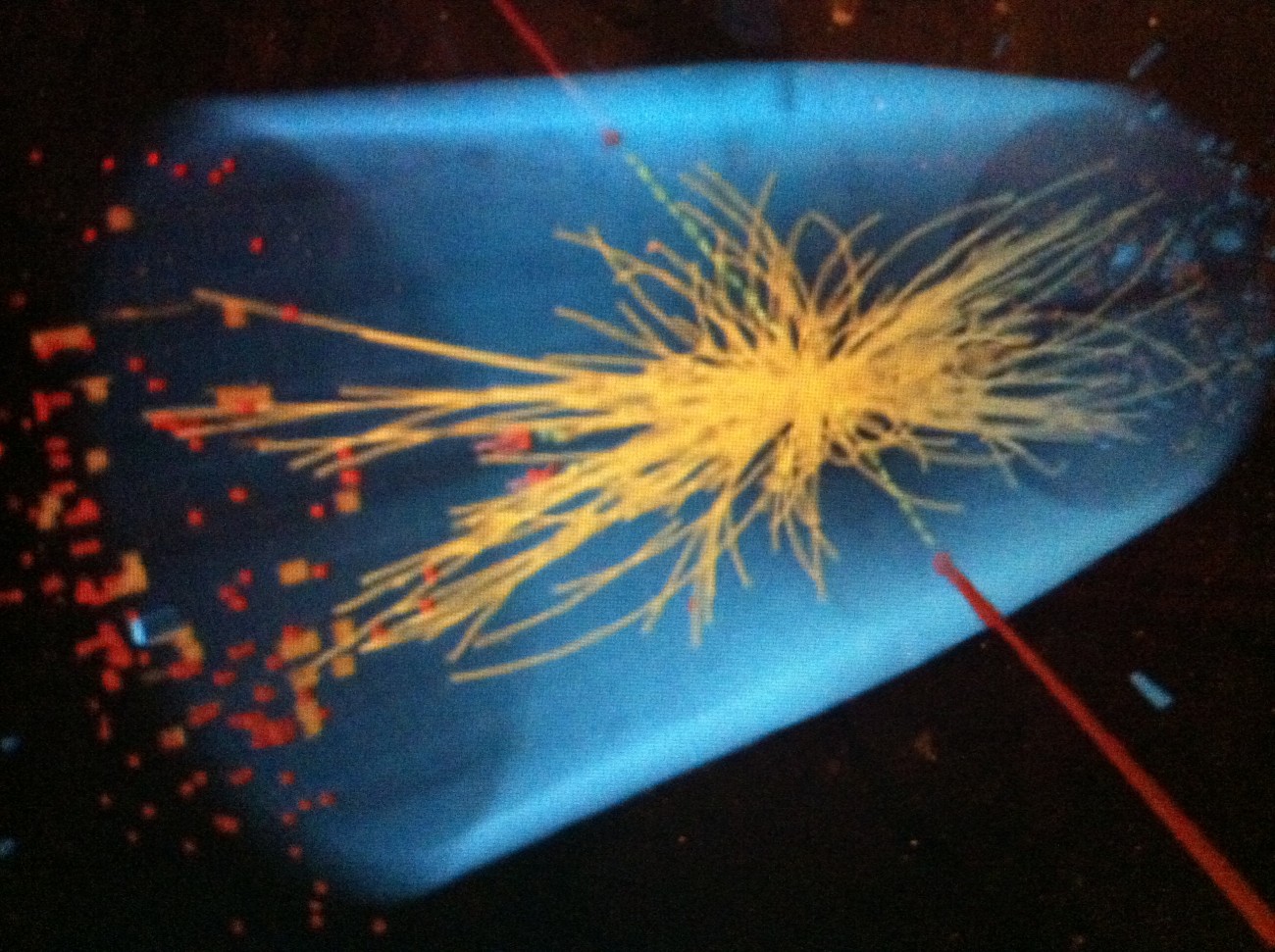
We spent the rest of the seminar computing significance levels, rejection regions, and power (by hand and with the Excel program). Here is the updated syllabus (3rd installment).
A relevant paper on selection effects on this blog is here.
 Any Jackie Mason fans out there? In connection with our discussion of power,and associated fallacies of rejection*–and since it’s Saturday night–I’m reblogging the following post.
Any Jackie Mason fans out there? In connection with our discussion of power,and associated fallacies of rejection*–and since it’s Saturday night–I’m reblogging the following post.
In February [2012], in London, criminologist Katrin H. and I went to see Jackie Mason do his shtick, a one-man show billed as his swan song to England. It was like a repertoire of his “Greatest Hits” without a new or updated joke in the mix. Still, hearing his rants for the nth time was often quite hilarious.
A sample: If you want to eat nothing, eat nouvelle cuisine. Do you know what it means? No food. The smaller the portion the more impressed people are, so long as the food’s got a fancy French name, haute cuisine. An empty plate with sauce!
As one critic wrote, Mason’s jokes “offer a window to a different era,” one whose caricatures and biases one can only hope we’ve moved beyond: But it’s one thing for Jackie Mason to scowl at a seat in the front row and yell to the shocked audience member in his imagination, “These are jokes! They are just jokes!” and another to reprise statistical howlers, which are not jokes, to me. This blog found its reason for being partly as a place to expose, understand, and avoid them. Recall the September 26, 2011 post “Whipping Boys and Witch Hunters”: [i]
Fortunately, philosophers of statistics would surely not reprise decades-old howlers and fallacies. After all, it is the philosopher’s job to clarify and expose the conceptual and logical foibles of others; and even if we do not agree, we would never merely disregard and fail to address the criticisms in published work by other philosophers. Oh wait, ….one of the leading texts repeats the fallacy in their third edition: Continue reading
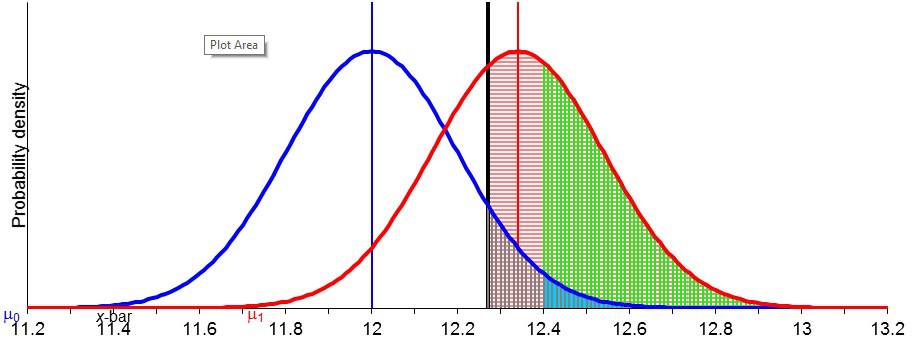 Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
[i]I was tempted to say power is one of the “most powerful” notions.It is.True, severity leads us to look, not at the cut-off for rejection (as with power) but the actual observed value, or observed p-value. But the reasoning is the same. Likewise for less artificial cases where the standard deviation has to be estimated. See Mayo and Spanos 2006.
[ii]
You can find a link to the Severity Excel Program (from which the pictures came) on the left hand column of this blog, and a link to basic instructions.This corresponds to EXAMPLE SET 1 pdf for Phil 6334.
Howson, C. and P. Urbach (2006). Scientific Reasoning: The Bayesian Approach. La Salle, Il: Open Court.
Mayo, D. G. and A. Spanos (2006) “Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction“ British Journal of Philosophy of Science, 57: 323-357.
Morrison and Henkel (1970), The significance Test controversy.
Ziliak, Z. and McCloskey, D. (2008), The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice and Lives, University of Michigan Press.

DGM playing the slots
I may have been exaggerating one year ago when I started this post with “Hardly a day goes by”, but now it is literally the case*. (This also pertains to reading for Phil6334 for Thurs. March 6):
Hardly a day goes by where I do not come across an article on the problems for statistical inference based on fallaciously capitalizing on chance: high-powered computer searches and “big” data trolling offer rich hunting grounds out of which apparently impressive results may be “cherry-picked”:
When the hypotheses are tested on the same data that suggested them and when tests of significance are based on such data, then a spurious impression of validity may result. The computed level of significance may have almost no relation to the true level. . . . Suppose that twenty sets of differences have been examined, that one difference seems large enough to test and that this difference turns out to be “significant at the 5 percent level.” Does this mean that differences as large as the one tested would occur by chance only 5 percent of the time when the true difference is zero? The answer is no, because the difference tested has been selected from the twenty differences that were examined. The actual level of significance is not 5 percent, but 64 percent! (Selvin 1970, 104)[1]
…Oh wait -this is from a contributor to Morrison and Henkel way back in 1970! But there is one big contrast, I find, that makes current day reports so much more worrisome: critics of the Morrison and Henkel ilk clearly report that to ignore a variety of “selection effects” results in a fallacious computation of the actual significance level associated with a given inference; clear terminology is used to distinguish the “computed” or “nominal” significance level on the one hand, and the actual or warranted significance level on the other. Continue reading
Slides (2 sets) from Phil 6334 2/27/14 class (Day#6).

D. Mayo:
“Frequentist Statistics as a Theory of Inductive Inference”
A. Spanos
“Probability/Statistics Lecture Notes 4: Hypothesis Testing”
 News Flash! Congratulations to Cosma Shalizi who announced yesterday that he’d been granted tenure (Statistics, Carnegie Mellon). Cosma is a leading error statistician, a creative polymath and long-time blogger (at Three-Toad sloth). Shalizi wrote an early book review of EGEK (Mayo 1996)* that people still send me from time to time, in case I hadn’t seen it! You can find it on this blog from 2 years ago (posted by Jean Miller). A discussion of a meeting of the minds between Shalizi and Andrew Gelman is here.
News Flash! Congratulations to Cosma Shalizi who announced yesterday that he’d been granted tenure (Statistics, Carnegie Mellon). Cosma is a leading error statistician, a creative polymath and long-time blogger (at Three-Toad sloth). Shalizi wrote an early book review of EGEK (Mayo 1996)* that people still send me from time to time, in case I hadn’t seen it! You can find it on this blog from 2 years ago (posted by Jean Miller). A discussion of a meeting of the minds between Shalizi and Andrew Gelman is here.
*Error and the Growth of Experimental Knowledge.

")

Experts convene to explore new philosophy of statistics field



Power taboos: Statue of Liberty, Senn, Neyman, Carnap, Severity
My fire alarm analogy is here. My analogy presumes you are assessing the situation (about the fire) long distance. Continue reading →