
 Just as in the past 2 years since I’ve been blogging, I revisit that spot in the road, get into a strange-looking taxi, and head to “Midnight With Birnbaum”. There are a couple of brief (12/31/13) updates at the end.
Just as in the past 2 years since I’ve been blogging, I revisit that spot in the road, get into a strange-looking taxi, and head to “Midnight With Birnbaum”. There are a couple of brief (12/31/13) updates at the end.
You know how in that (not-so) recent movie, “Midnight in Paris,” the main character (I forget who plays it, I saw it on a plane) is a writer finishing a novel, and he steps into a cab that mysteriously picks him up at midnight and transports him back in time where he gets to run his work by such famous authors as Hemingway and Virginia Wolf? He is impressed when his work earns their approval and he comes back each night in the same mysterious cab…Well, imagine an error statistical philosopher is picked up in a mysterious taxi at midnight (New Year’s Eve 2011 2012, 2013) and is taken back fifty years and, lo and behold, finds herself in the company of Allan Birnbaum.[i]
ERROR STATISTICIAN: It’s wonderful to meet you Professor Birnbaum; I’ve always been extremely impressed with the important impact your work has had on philosophical foundations of statistics. I happen to be writing on your famous argument about the likelihood principle (LP). (whispers: I can’t believe this!)
BIRNBAUM: Ultimately you know I rejected the LP as failing to control the error probabilities needed for my Confidence concept.
ERROR STATISTICIAN: Yes, but I actually don’t think your argument shows that the LP follows from such frequentist concepts as sufficiency S and the weak conditionality principle WLP.[ii] Sorry,…I know it’s famous…
BIRNBAUM: Well, I shall happily invite you to take any case that violates the LP and allow me to demonstrate that the frequentist is led to inconsistency, provided she also wishes to adhere to the WLP and sufficiency (although less than S is needed).
ERROR STATISTICIAN: Well I happen to be a frequentist (error statistical) philosopher; I have recently (2006) found a hole in your proof,..er…well I hope we can discuss it.
BIRNBAUM: Well, well, well: I’ll bet you a bottle of Elba Grease champagne that I can demonstrate it!
ERROR STATISTICAL PHILOSOPHER: It is a great drink, I must admit that: I love lemons.
BIRNBAUM: OK. (A waiter brings a bottle, they each pour a glass and resume talking). Whoever wins this little argument pays for this whole bottle of vintage Ebar or Elbow or whatever it is Grease.
ERROR STATISTICAL PHILOSOPHER: I really don’t mind paying for the bottle.
BIRNBAUM: Good, you will have to. Take any LP violation. Let x’ be 2-standard deviation difference from the null (asserting m = 0) in testing a normal mean from the fixed sample size experiment E’, say n = 100; and let x” be a 2-standard deviation difference from an optional stopping experiment E”, which happens to stop at 100. Do you agree that:
(0) For a frequentist, outcome x’ from E’ (fixed sample size) is NOT evidentially equivalent to x” from E” (optional stopping that stops at n)
ERROR STATISTICAL PHILOSOPHER: Yes, that’s a clear case where we reject the strong LP, and it makes perfect sense to distinguish their corresponding p-values (which we can write as p’ and p”, respectively). The searching in the optional stopping experiment makes the p-value quite a bit higher than with the fixed sample size. For n = 100, data x’ yields p’= ~.05; while p” is ~.3. Clearly, p’ is not equal to p”, I don’t see how you can make them equal. Continue reading



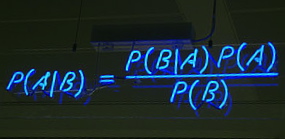










")

