Excursion 4: Objectivity and Auditing (blurbs of Tours I – IV)

.
Excursion 4 Tour I: The Myth of “The Myth of Objectivity”
Blanket slogans such as “all methods are equally objective and subjective” trivialize into oblivion the problem of objectivity. Such cavalier attitudes are at odds with the moves to take back science The goal of this tour is to identify what there is in objectivity that we won’t give up, and shouldn’t. While knowledge gaps leave room for biases and wishful thinking, we regularly come up against data that thwart our expectations and disagree with predictions we try to foist upon the world. This pushback supplies objective constraints on which our critical capacity is built. Supposing an objective method is to supply formal, mechanical, rules to process data is a holdover of a discredited logical positivist philosophy.Discretion in data generation and modeling does not warrant concluding: statistical inference is a matter of subjective belief. It is one thing to talk of our models as objects of belief and quite another to maintain that our task is to model beliefs. For a severe tester, a statistical method’s objectivity requires the ability to audit an inference: check assumptions, pinpoint blame for anomalies, falsify, and directly register how biasing selection effects–hunting, multiple testing and cherry-picking–alter its error probing capacities.
Keywords
objective vs. subjective, objectivity requirements, auditing, dirty hands argument, phenomena vs. epiphenomena, logical positivism, verificationism, loss and cost functions, default Bayesians, equipoise assignments, (Bayesian) wash-out theorems, degenerating program, transparency, epistemology: internal/external distinction
Excursion 4 Tour II: Rejection Fallacies: Whose Exaggerating What?
We begin with the Mountains out of Molehills Fallacy (large n problem): The fallacy of taking a (P-level) rejection of H0 with larger sample size as indicating greater discrepancy from H0 than with a smaller sample size. (4.3). The Jeffreys-Lindley paradox shows with large enough n, a .05 significant result can correspond to assigning H0 a high probability .95. There are family feuds as to whether this is a problem for Bayesians or frequentists! The severe tester takes account of sample size in interpreting the discrepancy indicated. A modification of confidence intervals (CIs) is required.
It is commonly charged that significance levels overstate the evidence against the null hypothesis (4.4, 4.5). What’s meant? One answer considered here, is that the P-value can be smaller than a posterior probability to the null hypothesis, based on a lump prior (often .5) to a point null hypothesis. There are battles between and within tribes of Bayesians and frequentists. Some argue for lowering the P-value to bring it into line with a particular posterior. Others argue the supposed exaggeration results from an unwarranted lump prior to a wrongly formulated null.We consider how to evaluate reforms based on bayes factor standards (4.5). Rather than dismiss criticisms of error statistical methods that assume a standard from a rival account, we give them a generous reading. Only once the minimal principle for severity is violated do we reject them. Souvenir R summarizes the severe tester’s interpretation of a rejection in a statistical significance test. At least 2 benchmarks are needed: reports of discrepancies (from a test hypothesis) that are, and those that are not, well indicated by the observed difference.
Keywords
significance test controversy, mountains out of molehills fallacy, large n problem, confidence intervals, P-values exaggerate evidence, Jeffreys-Lindley paradox, Bayes/Fisher disagreement, uninformative (diffuse) priors, Bayes factors, spiked priors, spike and slab, equivocating terms, severity interpretation of rejection (SIR)
Excursion 4 Tour III: Auditing: Biasing Selection Effects & Randomization
Tour III takes up Peirce’s “two rules of inductive inference”: predesignation (4.6) and randomization (4.7). The Tour opens on a court case transpiring: the CEO of a drug company is being charged with giving shareholders an overly rosy report based on post-data dredging for nominally significant benefits. Auditing a result includes checking for (i) selection effects, (ii) violations of model assumptions, and (iii) obstacles to moving from statistical to substantive claims. We hear it’s too easy to obtain small P-values, yet replication attempts find it difficult to get small P-values with preregistered results. I call this the paradox of replication. The problem isn’t P-values but failing to adjust them for cherry picking and other biasing selection effects. Adjustments by Bonferroni and false discovery rates are considered. There is a tension between popular calls for preregistering data analysis, and accounts that downplay error probabilities. Worse, in the interest of promoting a methodology that rejects error probabilities, researchers who most deserve lambasting are thrown a handy line of defense. However, data dependent searching need not be pejorative. In some cases, it can improve severity. (4.6)
Big Data cannot ignore experimental design principles. Unless we take account of the sampling distribution, it becomes difficult to justify resampling and randomization. We consider RCTs in development economics (RCT4D) and genomics. Failing to randomize microarrays is thought to have resulted in a decade lost in genomics. Granted the rejection of error probabilities is often tied to presupposing their relevance is limited to long-run behavioristic goals, which we reject. They are essential for an epistemic goal: controlling and assessing how well or poorly tested claims are. (4.7)
Keywords
error probabilities and severity, predesignation, biasing selection effects, paradox of replication, capitalizing on chance, bayes factors, batch effects, preregistration, randomization: Bayes-frequentist rationale, bonferroni adjustment, false discovery rates, RCT4D, genome-wide association studies (GWAS)
Excursion 4 Tour IV: More Auditing: Objectivity and Model Checking
While all models are false, it’s also the case that no useful models are true. Were a model so complex as to represent data realistically, it wouldn’t be useful for finding things out. A statistical model is useful by being adequate for a problem, meaning it enables controlling and assessing if purported solutions are well or poorly probed and to what degree. We give a way to define severity in terms of solving a problem.(4.8) When it comes to testing model assumptions, many Bayesians agree with George Box (1983) that “it requires frequentist theory of significance tests” (p. 57). Tests of model assumptions, also called misspecification (M-S) tests, are thus a promising area for Bayes-frequentist collaboration. (4.9) When the model is in doubt, the likelihood principle is inapplicable or violated. We illustrate a non-parametric bootstrap resampling. It works without relying on a theoretical probability distribution, but it still has assumptions. (4.10). We turn to the M-S testing approach of econometrician Aris Spanos.(4.11) I present the high points for unearthing spurious correlations, and assumptions of linear regression, employing 7 figures. M-S tests differ importantly from model selection–the latter uses a criterion for choosing among models, but does not test their statistical assumptions. They test fit rather than whether a model has captured the systematic information in the data.
Keywords
adequacy for a problem, severity (in terms of problem solving), model testing/misspecification (M-S) tests, likelihood principle conflicts, bootstrap, resampling, Bayesian p-value, central limit theorem, nonsense regression, significance tests in model checking, probabilistic reduction, respecification
Where you are in the Journey 


 Little bit of logic (5 little problems for you)[i]
Little bit of logic (5 little problems for you)[i]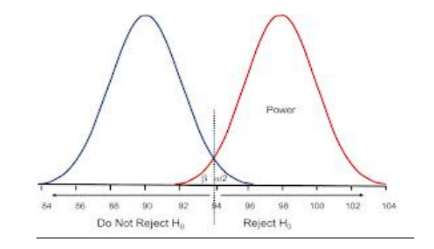













")

