
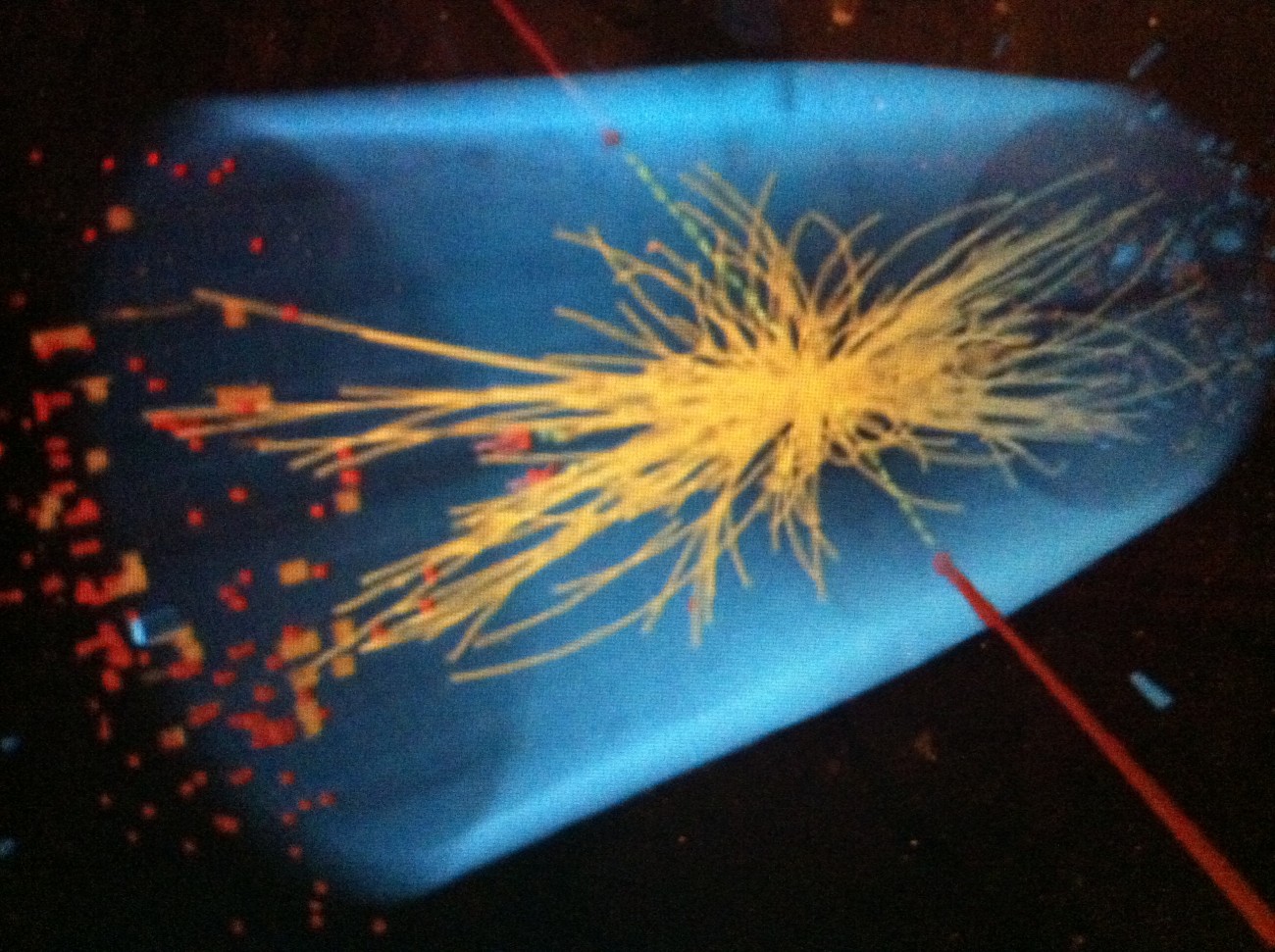
 I am always impressed at how researchers flout the popular philosophical conception of scientists as being happy as clams when their theories are ‘born out’ by data, while terribly dismayed to find any anomalies that might demand “revolutionary science” (as Kuhn famously called it). Scientists, says Kuhn, are really only trained to do “normal science”—science within a paradigm of hard core theories that are almost never, ever to be questioned.[i] It is rather the opposite, and the reports out last week updating the Higgs data analysis reflect this yen to uncover radical anomalies from which scientists can push the boundaries of knowledge. While it is welcome news that the new data do not invalidate the earlier inference of a Higgs-like particle, many scientists are somewhat dismayed to learn that it appears to be quite in keeping with the Standard Model. In a March 15 article in National Geographic News:
I am always impressed at how researchers flout the popular philosophical conception of scientists as being happy as clams when their theories are ‘born out’ by data, while terribly dismayed to find any anomalies that might demand “revolutionary science” (as Kuhn famously called it). Scientists, says Kuhn, are really only trained to do “normal science”—science within a paradigm of hard core theories that are almost never, ever to be questioned.[i] It is rather the opposite, and the reports out last week updating the Higgs data analysis reflect this yen to uncover radical anomalies from which scientists can push the boundaries of knowledge. While it is welcome news that the new data do not invalidate the earlier inference of a Higgs-like particle, many scientists are somewhat dismayed to learn that it appears to be quite in keeping with the Standard Model. In a March 15 article in National Geographic News:
Although a full picture of the Higgs boson has yet to emerge, some physicists have expressed disappointment that the new particle is so far behaving exactly as theory predicts.
“This is looking very much like a garden-variety [Standard Model] Higgs, which is discouraging for hopes of hints about how to get beyond the Standard Model,” Peter Woit, a mathematician at Columbia University in New York, wrote on his blog Not Even Wrong.
And cosmologist Sean Carroll of Caltech tweeted that the new data on the Higgs boson is “looking pretty vanilla.”
The only real indication of a potential anomaly with the simple Standard Model has to do with the prediction of 0 spin, and many scientists were anxiously awaiting evidence that the anomaly was real. Yet on the basis of the most recent data, they ruled that it can be disregarded as a “statistical fluke”.
I warn that my understanding of the physics of this case is of the layperson variety, based on some excellent detailed discussions (linked within this post). The pattern is similar to other particle physics experiments: The recorded data involve how many excess events of a given type are “observed” (from creating zillions of collisions). Here it is in comparison to the number (or proportion) that would be expected from background alone and not due to a Higgs boson[ii]. Such excess events {d(X) > d(x)} give a “signal like” result, but throughout the history of Higgs experiments, statistically significant indications regularly disappeared as do “statistical flukes”!
Only after considerable work did they get to the stage of July 2012 where genuine evidence could be based on the 5 sigma observed effect. What’s the probability the set of tests would yield “results as or more signal-like than observed” were the observed excess events due to “background noise only” (no Higgs particle)? Extremely (some say “astronomically”) low. The improbability of the 5 sigma excess alludes to the sampling distribution associated with such signal-like results (or “bumps”), fortified with much cross-checking of results:
P(tests would yield at least a 5 sigma excess; Ho: background only) = extremely low.
The probability that last year’s data identifying the Higgs boson was a statistical fluke—and that researchers hadn’t discovered the long-sought particle—”is now becoming astronomically low,” said Tim Barklow, an experimental physicist with the ATLAS Experiment who’s based at Stanford University’s SLAC National Accelerator Laboratory.
The new evidence is compelling enough that some scientists have thrown caution to the wind and have stopped referring to the new particle as being merely “Higgs-like” and just calling it the Higgs boson. (National Geographic News).
The move from calling it merely “Higgs-like” to Higgs boson Yet a distinct move would be from inferring evidence of a Higgs boson to evidence of a Standard Model Higgs*. This takes us to the issue of the anomalous evidence. It concerns the inference, not to the existence of the particle, but to its properties. Particle physicist Matt Strassler has a great website with detailed discussions. He notes:
The only measurements of its production and decay properties which are notably out of alignment with predictions for a Standard Model Higgs particle are in the process in which a Higgs is produced and then decays to two photons; this occurs about 1.65 times as often as expected, according to the ATLAS experiment’s new measurement, with uncertainties that put this result about 2.3 standard deviations above the Standard Model prediction. That’s not nearly enough to be anything more than intriguing [we’d want at least 3 standard deviations to get excited and something like 5 to be convinced], and the excess is slightly smaller (and of similar statistical significance) to their last measurement, which suggests the excess is gradually going away as more data is collected.
In other words, the July, 2012 data gave evidence of the existence of a Higgs-like particle, but also showed some hints of anomaly with the “plain vanilla” particle of the Standard Model (wrt “production and decay properties”). There are rivals to the Standard Model that would also predict a Higgs particle, but not of the simple plain vanilla type[iii], as regards properties of spin (also parity).With this new data analysis, the former is strengthened (to over 7 sigma), the latter weakened to the extent that it appears just like a great many interesting looking bumps that have disappeared. Given the sources of systematic error, they are prepared to regard it as a statistical fluke. Moreover, Strassler continues
Each time the excess has remained, though it has become a bit smaller each time, and therefore the statistical significance of the result has not really increased. That’s an unfortunate sign, if one is hoping the excess isn’t just a statistical fluke. [Note that, by contrast, the statistical significance of the evidence for the Higgs particle’s very existence has gone up each time we’ve seen new data.] (my emphasis)[iv] (link is here.)
Disappearing with more data is just what’s expected with statistical flukes.
Telling What’s True About P-values:
In updating a section of a book I’m writing with the latest Higgs data report, it occurs to me that it can be relevant for explicating the central issues that keep cropping up regarding the proper interpretation and relevance of statistical significance levels and p-values (for a recent link). Outside the (small?) circle of people wearing ideological blinkers, many are earnestly trying to get to the bottom of this issue, and I have to admit that it has not been as easy as I imagined to explicate it.
So how might this case help? Readers might recall that when the July 2012 report came out, a number of people set out to grade the different interpretations of the p-value report: thumbs up or down[v]. Thumbs up, for example, to the the ATLAS group report:
“A statistical combination of these channels and others puts the significance of the signal at 5 sigma, meaning that only one experiment in three million would see an apparent signal this strong in a universe without a Higgs.”
Thumbs down to reports such as:
There is less than a one in a million chance that their results are a statistical fluke.
The link is here.
Yet now we see highly sophisticated analysts using the same, supposedly prohibited language, and I think this may be a place to see what’s true about these reports, as well as give a basis for the critics’ worries. This is to be continued in a later post. For now, I hope interested readers will read either of the following:
(1) A discussion in the New York Times (Science) “Chasing the Higgs Boson” that gives an overview of events from 2010 to the present.
(2) Matt Strassler’s blog “Of Particular Significance” (March 14 and 15, 2013):
“From Higgs-like Particle to Standard Model-like Higgs”
“CMS Sees no Excess in Higgs Decays to Photons”[vi]
*I owe experimental particle physicist, Matt Strassler, a large debt of gratitude for contacting me on Skype today to correct at least a few of my misunderstandings/misstatements about the case. The crossed out phrase is one example. there may be others.
[i] Should anomalies be so severe, and the data so incapable of being forced into line with theory, researchers enter what he calls “crisis science”, requiring a “gestalt” shift of theory, methods, and even basic aims. (For a discussion, see chapter 2 of EGEK 1996).
[ii] When the results were first reported, Lindley had Tony O’Hagan send around a letter asking why they were demanding 5 standard deviations and did not the scientists know that using p-values was “bad science”? But their call for a subjective Bayesian analysis is very different from the issue on which I am now focusing.
[iii] And there are also rivals that would predict the simple plain vanilla type. So these other theories are still not ruled out.
[iv] So there are two distinct inferences, one we may call positive, the other negative: The positive one is to the existence of a Higgs-like particle, the negative one is a denial of evidence that the particle has properties (regarding spin) at odds with the simple particle of the Standard Model. To show the anomalies are not corroborated, it suffices to show that the data are consistent with the simple Higgs expectation regarding spin (also parity).
Comparing the evidence for these two inference, Howard Gordon, the ATLAS deputy collaboration board chair noted that “The Higgs’ spin and parity are ‘not as definitive as the fact that we have a new particle’”.
[v] This also came up on Normal Deviate’s blog: http://normaldeviate.wordpress.com/2012/07/11/the-higgs-boson-and-the-p-value-police/
[vii] CMS is the Compact Muon Solenoid.


")


Very interesting, and a lovely case study for students of statistical inference.
Do you think that a correction for multiple looks at the data is applied? Or should be? (I don’t!)
Michael: The so-called “look elsewhere effect” is taken into account earlier, but I don’t know the details of the analysis. It’s discussed in many places however.
“Yet now we see highly sophisticated analysts using the same, supposedly prohibited language, and I think this may be a place to see what’s true about these reports”
This makes me curious. So you’re willing to make concessions in this direction now?
I don’t know what concessions you mean.
Christian: I hope it is clear that I meant that we’ll see what true about the experimental particle physicist’s reports.
Ah, so not about the “prohibited language”?
Christian: I meant they were using language that earned them a’ thumbs down’, but in fact that language is warranted, if correctly understood.
Gelman’s blog today alludes to “those silly debates about how best to explain p-values (or, worse, the sidebar about whether it’s kosher to call a p-value a conditional probability)” arising from a remark I made on his blog last week, discussed as well on Normal Deviate’s blog.
But I really think that my current discussion, growing out of experimental particle physics statistics (but it could be any example), will use this very point to illuminate something very much at the heart of confusions about statistical inference.
Unfortunately, most commentators on my remark (about p-values not being conditional probabilities*) saw their goal as needing to invent a way to view significance levels as conditional probabilities, rather than trying–just for a minute–to see if a different perspective emerges from going with my point. I think it does, and hope to bring out why it is relevant (and not silly) in the next post or two. (Traveling at the moment.)
*On both Gelman’s and the Normal Deviate’s blogs:http://normaldeviate.wordpress.com/2013/03/14/double-misunderstandings-about-p-values/
Mayo: As you know, I’ve been following the p-value discussion, and it seems to me that it’s just an expression of the conflict over the appropriate real-world use of mathematical probability theory. There’s no empirical frequency distribution for which a p-value is a conditional frequency. There are uncountable plausibility/belief measures for which a p-value is a conditional Jaynes-style/Gelman-style/subjective/whatever probability. What more is there to say that isn’t already a part of the frequentist/Bayesian disagreement?
Corey: You talk as if THE “frequentist/Bayesian disagreement” is something at all clear, but it isn’t, as this blog has shown. Further evidence of the muddiness is your reference to “uncountable plausibility/belief measures for which a p-value is a conditional Jaynes-style/Gelman-style/subjective/whatever probability.” Perhaps Gelman has uncountably many beliefs about these issues, but that just muddies things further. For a couple of examples, alluding to him:
older:
https://errorstatistics.com/2012/03/10/a-further-comment-on-gelman-by-c-hennig/
https://errorstatistics.com/2012/03/06/2645/
newer:
https://errorstatistics.com/2012/10/12/u-phils-hennig-and-aktunc-on-gelman-2012/
https://errorstatistics.com/2012/10/05/deconstructing-gelman-part-1-a-bayesian-wants-everybody-else-to-be-a-non-bayesian/
Mayo wrote: “You talk as if THE “frequentist/Bayesian disagreement” is something at all clear, but it isn’t, as this blog has shown.”
Yes, sure, you’ve nailed a tangentially related imprecision in writing. (As for “uncountably many”, all I meant is that, mathematically speaking, there are uncountably many prior distributions on the parameter space, irrespective of the philosophical interpretation one ascribes to any of them.) I still want to know: what more is there to say about the conditionality or lack thereof of p-values that isn’t already a part of the 46,656 varieties of muddied, unclear frequentist/Bayesian disagreement?
Typo: “imprecision in writing” should be “imprecision in my writing”.
I don’t see how Gelman really gets pulled in on the Bayesian side, as far as I can make out his position, he is a Bayesian in name only. He rejects Bayesian updating, doesn’t believe in subjective priors, but most telling, he wants to test priors (i.e., models and assumptions on his account)–so what’s Bayesian about this? If it looks like a frequentist, walks like a frequentist and quacks like a frequentist…you get my point, Calling such a position Bayesian really muddies the waters.
(oops, my second half got cut off,) And, I wanted to add, this is why I think it is important and necessary to lay out the foundations of various positions for public scrutiny because especially with the new Objective/reference Bayesian positions being carved out, it is unclear what their foundations are, making it difficult to either critique or embrace them. And the frequentists need to clean house too, which I take it is what D. Mayo has been attempting to do.
Jean: Yes we need to clean our igloos, tents, adobes and mansions!
Jean: Well one time he said he didn’t even like the name…But I think you’re right (though i prefer “error statistician” for one who employs sampling distributions to obtain error probabilities, and “an account of severity based on error statistics” for one who employs error probabilities to evaluate and assess severity. Error statistics also includes behavioristic or performance-oriented uses of error probabilities of procedures.)
Some people have said that Gel-Bayesianism allows them to pass muster in the brotherhood but with a wink and a nod. Someone else whose name I will not mention told me there was a “gentleman’s agreement” not to point up any schizoid or bipolar behavior. but I am not a gentleman.
“as far as I can make out his position, he is a Bayesian in name only.”
Jean: Well, Gelman qua statistician publishes papers on choosing priors and computing posteriors; qua political scientist, he publishes papers reporting posterior distributions for parameters of models relevant to political science. Even disregarding his seminal text entitled “Bayesian Data Analysis”, that sort of thing earns a dude the label “Bayesian”, no matter how “schizoid” his philosophy of probability might be.
Corey: Yes, he’s “earned” the label ‘Bayesian”.
Corey: I thought Gelman does not advocate reporting posteriors for parameters in models. Not that I’m sure just what he advocates. Yesterday* he reminds us:
: “Indeed, when I say that a Bayesian wants other researchers to be non-Bayesian, what I mean is that I want people to give me their data or their summary statistics, unpolluted by any prior distributions. But I certainly don’t want them to discard all their numbers in exchange for a simple yes/no statement on statistical significance.”
So the researcher presents their data unpolluted by priors. That’s good (does this include likelihoods?** I presume so else one cannot update or assess ), but then what? I take it (from an earlier post on this blog) then the reader supplies his or her prior (which might reflect knowledge or belief, or might just be a mathematical concept for getting a posterior). Why? Presumably the prior is influenced by seeing the data, but I’m not sure if that makes them less polluted. What’s to stop someone adjusting the prior, having seen the data, so that they like the posterior?
Besides, if people could readily move from a report of data to an assessment of evidential import, they’d not bother with statistics.
*http://andrewgelman.com/2013/03/25/the-harm-done-by-tests-of-significance/#comments
**What about information regarding multiple testing and selection effects?
Corey: Your query is still unclear. But spoze I agree that this matter is intertwined with the muddy foundations of the nature of statistical inference. Why would that mean I’ve nothing new to say about it? I aim to cut-through the mud with a sharp knife –one that is considerably over the maximum of 2.3 or whatever inches soon to be allowed on planes.
Mayo: Not just intertwined — encompassed. As far as I can see, the conditionality-of-p-values issue is really very simple, so naturally I think that at this point there’s little to be said specifically about it that hasn’t already been said. Am I mistaken?
Corey: I don’t plan to talk about the non-conditionality of p-values. The nature of statistical inference is a question still inadequately answered and a problem still to be solved. This was demonstrated–among many other places–in the exchange you and I had (on this blog) regarding “bad tests”, and the inability to capture that notion adequately in Bayesian terms. But no one is forcing you to tune in…
A comment came in today from an April 2012 post that might be relevant:
https://errorstatistics.com/2012/04/03/history-and-philosophy-of-evidence-based-health-care/#comments
It is from Alexandre. He notes that error probabilities are not evidential relation measures, and gives a link to a paper on this. This has often been discussed on this blog, but lacking a new post, let me post my reply to him:
Yes, that is why error probabilities of tests, and hypotheses within tests, do not follow probability logic. For a blatant example, both H and not-H can be very poorly corroborated. With error probabilities it’s a matter of how easy (probable) it is to be wrong, and a test that has many more ways to go wrong, or many more ways to get results by chance, be it from asking more questions (like more disjuncts), or selection effects or the like, has altered error probabilities. The is the wonderful thing about error statistics, and not at all something to wish different. Mine is not an evidential-relation account, it completely throws overboard the “logicist” assumptions of logical empiricist accounts of evidence. That may not have trickled down to the formal philosophers as of yet.
Mayo I fully agree with you. I just have some comments:
“For a blatant example, both H and not-H can be very poorly corroborated.”
Yes, this happens! The proposed measure of the paper: http://arxiv.org/abs/1201.0400 has three types of decisions:
Let s be the proposed measure of the paper and H be very general hypothesis (it can be so general as you can think), then we have
Either s(H) = 1 or s(~H) = 1 for any H. The following are types of conclusions based on the properties of the measure s:
1. If s(H) is approximately 0 and s(~H) = 1, then we should reject H
2. If s(H) = 1 and s(~H) is approximately 0, then we should accept H
3. If s(H) = 1 and s(~H) = 1, then we do not information to accept or reject. We should collect more data.
It is possible to define thresholds to state precisely what “approximately” means above.
Observe that when s(H) = 1, then the maximum likelihood lies inside the null parameter space, on the other hand, when s(~H) = 1 then the maximum likelihood lies inside the complement of null parameter space. If the maximum likelihood lies inside the null parameter space and if it is far from the alternative one, it is quite natural to accept the null hypothesis. Don’t you think?
When s(H) = s(~H) = 1, then the maximum likelihood exactly lies in the border of the closure of null parameter space.
When s(H) is approximately 1 and s(~H) = 1, then the maximum likelihood lies inside of the null parameter space, but it is close to the alternative one. (that is: we have no evidence to reject neither accept H, we are close to absolute ignorance)
When s(~H) is approximately 1 and s(H) = 1, then the maximum likelihood lies inside of the alternative parameter space, but it is close to the null one. (that is: we have no evidence to reject neither accept H, we are close to absolute ignorance)
And so on…
PS: this proposed measure “s” is a p-value based on the likelihood ratio statistic for very specific hypothesis (and for monotonic ratio statistics). Therefore, this rule can be used for these p-values in this specific situation.
Some corrections:
“(that is: we have no evidence to reject neither accept H, we are close to absolute ignorance)”
should be read as
“(that is: we have evidence neither to reject nor to accept H, we are close to absolute ignorance)”
“Therefore, this rule can be used for these p-values in this specific situation.”
should be read as
“Therefore, this rule can be used for these specific p-values under such specific situations.”
Having evidence for neither is not ignorance.
Reposting here a comment made on the other thread:
Mayo, thanks for your response:
In this paper, I am not against the use of p-values, actually I just redefine them in a formal fashion in order to understand what is happening. The thing basically is: a statistic that has optimal behavior (in some sense) should vary with the null hypotheses (as you know). That is to say: it has optimal behavior for THAT specific null hypothesis. I know that you are aware of this fact, but when we write:
P(T > t ; under H0),
we are feeding many controversies, since it is not well defined (see the introduction of the paper: http://arxiv.org/abs/1201.0400).
A new measure of evidence, that *complements* the p-value and severity measures, with interesting interpretations on grounds of confidence regions is proposed and studied. It is important to say that p-values are not demonized in the paper, however if one also wants a support measure over Theta that does not depend on prior probabilities, the proposed measure can be successfully used.
It should be said that ma-many practitioners (in medical fields) use statistical hypothesis testing in their studies and they use nested hypotheses a lot. Well, p-values cannot be used in such contexts and they deserve to know it. Don’t you think?
Alexandre: I will look at your paper before commenting. thanks much. Mayo
I fail to see where you have shown that p-values are not well defined.
Elbians: Thanks SO much for fixing the screen on my Mac Air, it’s been so long that I’ve been lugging around the heavy Mac in and out of subways. Killing my back! But don’t I owe like $500?