
 In this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures. Science writers are under similar pressures, and to this end they have found a way to deliver up at least one fire-breathing, front page article a month. How? By writing minor variations on an article about how in this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures.
In this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures. Science writers are under similar pressures, and to this end they have found a way to deliver up at least one fire-breathing, front page article a month. How? By writing minor variations on an article about how in this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures.
Thus every month or so we see retreads on why most scientific claims are unreliable, biased, wrong, and not even wrong. Maybe that’s the reason the authors of a recent article in The Economist (“Trouble at the Lab“) remain anonymous.
I don’t disagree with everything in the article; on the contrary, part of their strategy is to include such well known problems as publication bias, problems with priming studies in psychology, and failed statistical assumptions. But the “big news”–the one that sells– is that “to an alarming degree” science (as a whole) is not reliable and not self-correcting. The main evidence is that there are the factory-like (thumbs up/thumbs down) applications of statistics in exploratory, hypotheses generating contexts wherein the goal is merely screening through reams of associations to identify a smaller batch for further analysis. But do even those screening efforts claim to have evidence of a genuine relationship when a given H is spewed out of their industrial complexes? Do they go straight to press after one statistically significant result? I don’t know, maybe some do. What I do know is that the generalizations we are seeing in these “gotcha” articles are every bit as guilty of sensationalizing without substance as the bad statistics they purport to be impugning. As they see it, scientists, upon finding a single statistically significant result at the 5% level, declare an effect real or a hypothesis true, and then move on to the next hypothesis. No real follow-up scrutiny, no building on discrepancies found, no triangulation, self-scrutiny, etc.
But even so, the argument which purports to follow from “statistical logic”, but which actually is a jumble of “up-down” significance testing, Bayesian calculations, and computations that might at best hold for crude screening exercises (e.g., for associations between genes and disease) commits blunders about statistical power, and founders. Never mind that if the highest rate of true outputs was wanted, scientists would dabble in trivialities….Never mind that I guarantee if you asked Nobel prize winning scientists the rate of correct attempts vs blind alleys they went through before their Prize winning results, they’d say far more than 50% errors, (Perrin and Brownian motion, Prusiner and Prions, experimental general relativity, just to name some I know.)
But what about the statistics?
It is assumed that we know that, in any (?) field of science, 90% of hypotheses are false. Who knows how, we just do. Further, this will serve as a Bayesian prior probability to be multiplied by rejection rates in non-Bayesian hypothesis testing.
Ok so (1) 90% of the hypotheses that scientists consider are false. Let γ be “the power”. Then the probability of a false discovery, assuming we reject H0 at the α level is given by the computation I’m pasting from an older article on Normal Deviate’s blog.
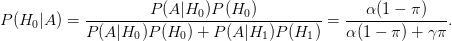
Again, γ is “the power” and A = “the event of rejecting H0 at the α level”. They use α = .05.
So, let’s see…
(1) is equated to 90% of null hypotheses in significance testing are true!
(2) So P(H0) = .9, and P(not-H0) = .1.
A false hypothesis means the null of a significance test is true. What is a true hypothesis? It would seem to be the denial of H0 , i.e.,not-H0. Then the existence of any discrepancy from the null would be a case in which the alternative hypothesis is true. Yet their example considers
P(x reaches cut-off to reject H0|not-H0) = .8.
They call this a power of .8. But the power is only defined relative to detecting a specific alternative or discrepancy from the null, in a given test. You can’t just speak about the power of a test (not that it stops the front page article from doing just this). But to try and make sense of this, they appear to mean
“a hypothesis is true” = there is truly some discrepancy from H0 = not-H0 is true.
But we know the power against (i.e., for detecting) parameter values very close to H0 is scarcely more than .05 (the power at H0 being .05)!
So it can’t be that what they mean by a true hypothesis is “not-H0 is true”.
Let’s try to use their power of .8. to figure out, then,what a true hypothesis is supposed to be.
Let x* be the .05 cut-off for the test in question (1 or 2-sided, we’re not told, I assume 1-sided).
P(test rejects H0 at the .05 level| H’) = .8.
So all we have to do to find H’ is consider an alternative against which this test has .8 power.
But H0 together with H’ do not exhaust the space of parameters. So you can’t have this true/false dichotomy referring to them. Let’s try a different interpretation.
Let “a hypothesis is true” mean that H’ is true (where the test has .8 power against H’). Then
“a hypothesis is false” = the true parameter value is closer to H0 than is H’ .
But then the .05 probability of erroneous rejections is no longer .05, but would be much larger—very close to the power .8. So I fail to see how this argument can hold up.
Suppose, for example, we are applying a Normal test T+ of H0: µ ≤ 0 against H1: µ > 0 , and x* is the ~.025 cut-off: 0 + 2(σ/ √n), where for simplicity let σ be known (and assume iid is not itself problematic). Then
x* + 1(σ/ √n)
brings us to µ = 3(σ/ √n),an alternative H’ against which the test has .84 power–so this is a useful benchmark and close enough to their .8 power.
Consider then H0: µ ≤ 0 and H’: 3(σ/ √n). H0 and H’ do not exhaust the hypothesis space, so how could they have the “priors” (of .9 and .1) they assign?
It’s odd, as well, to consider that the alternative to which we assign .1 prior is to be determined by the test to be run. I’m prepared to grant there is some context where there are just two point hypotheses; but their example involves associations, and one would have thought degrees were the norm.
I’ll come back to this when I have time later (I’ll call this draft (i)) [1]—I put it here as a place holder for a new kind of howler we’ve been seeing for the past decade. I’m having a party here at Thebes tonight…so I have to turn to that…Since I do believe in error correction, please let me know where I have gone wrong.
[1] I made a few corrections after the party, so it’s now draft (ii).
[2] See larger version of this great cartoon (that did not come from their article.)
[3] To respond to a query on power (in a comment): Power: For the Normal testing example with T+: H0: µ ≤ µ0 against H1: µ > µ0.
Test T+: Infer a (positive) discrepancy from µ0 iff {x > x*) where x* corresponds to a difference statistically significant at the α level (I’m being sloppy in using x rather than a proper test stat d(x), but no matter).
Z =(x*- µ1 ) √n (1/σ)
I let x* = µ0+ 2(σ/ √n)
So, with µ0= 0, and µ1= 3(σ/ √n),
Z = [2(σ/ √n)- 3(σ/ √n) ] (√n /σ) = -1
P(Z > -1) = .84
For more, search power on this blog.
[4] Another one!, and a guy Johnson rediscovering the wheel: alternatives! http://www.nature.com/news/weak-statistical-standards-implicated-in-scientific-irreproducibility-1.14131


")


I’m guessing that these numbers aren’t offered as definitive, but as plausible guesses for the purpose of illustration. Off I go to check…
The authors don’t disclaim the numbers they offer, but do say, “Consider…” Sloppy writing if they just meant to offer the calculation for the purpose of illustration, and misleading if they meant something more definitive.
I had the whole staff in our lab read these articles to be aware of them. What I find disappointing is that the authors appear to have never heard of validation studies and the like. Forensic and clinical labs are required to validate tests before using them at the bench. Of course validation typically involves replication and measurement of error rates. The articles could unnecessarily give an impression of applied science as reckless, which would not be accurate. I think perhaps it is journalism that is losing its edge.
John: Thanks for your comment. Do you mean you had the staff read them in the past or just these new ones coming to light? I know there are important criticisms out there,I’m not denying it. Even the best of them, however, commits a variety of slippery slides (e.g., between error probabilities of tests and likelihoods,between the probability or evidence that this result is false and some kind of false positive rates in screening). I’d like to see more critiques of the number crunching in some of the better and more elaborate science alarmist articles–this isn’s one of them.
I had the staff read the articles from the Economist. I wanted them to be aware of the criticisms, as for example those of peer review. We use peer review as a cornerstone of our quality assurance system in the lab. But, our peer review is far superior to what was said about the journals, though no review process is perfect. I also noted that the critique of significance tests seemed off-base compared to what I see in practice.
John: Why do you suppose your field manages to retain a quality assurance that many other areas fall down on–assuming it does?
I suppose forensics always has the possibility of court challenge looming over it, which motivates a robust commitment to quality– we find and correct any problem before an outside entity does. But, I think the same is true for clinical labs. We all tend to design QA to satisfy the same international standard , ISO 17025. The standard requires numerous QA processes, including method validation. I would presume pharm labs would have similar motivations to discover their problems before others do and you get the black eye.
Just to add a little more, the articles give the impression that scientists really do not check each others’ work. This is just not true, and especially not true in applications formal tests. Any accredited forensic lab will have a multidimensional quality assurance program that addresses individual test results and the abilities of the people performing the tests. Peer review includes re-examination of the test specimens in most cases…
The article will probably scare people unnecessarily.
John: How would you explain the kind of situation that Stan Young describes and other people describe. It’s one thing for social psychology to border on the pseudoscientific, but he’s talking about biology and cancer research. I would have thought there was sufficient incentive in medicine, at least the drug companies I follow.
But what really bothers me, and yet is hard to pinpoint is the tendency to exploit caricatures of significance tests in order to create a scapegoat and erect a “manufactured alibi” to free violators from responsibility, at times at least (as with the Harkonen case). “There’s no bright line” and “scientists disagree” about statistical methods.
I find it hard to believe that the problem is that pervasive as portrayed. One thing about scientific experts, they are all deeply critical of the details of their rivals’ ideas. Maybe journalists hear the endless criticisms and get the impression nothing is done well. Plus, in the biological sciences, the inability to exactly replicate is really not that surprising. There are so many variables…
I worked in industry, drug discovery, and there was constant oversight. The next phase of discovery was generally more expensive than the current stage. Also, we all knew that the final product was a drug that had to work or only few people would buy it. Our product was a drug. On the other hand, in a university, the final product is usually a paper. Peer review provides only minimal oversight. If you don’t have to provide your data set, things can get out of hand.
Stan: I’d really like to get to the bottom of contrasting reports. What you say about drug companies, Stan, is also my outsider’s experience (as someone who has traded in biotech/medical stocks)—at least in the last decade. As soon as anything is reported at the FDA (and people may know you can watch FDA drug panels on line, at least in my experience) there’s an immediate move on the stock. But then we hear this investigation by Begley and others into crass mistakes relating to designer cancer drugs—drugs that I believe were already being given to some people (Senn reported on it, also Stan Young). Stan also reported about the lack of randomization in microarrays setting the field back 10 years. https://errorstatistics.com/2013/06/19/stanley-young-better-p-values-through-randomization-in-microarrays/I am intrigued by John Byrd’s suggestion of rivalry*—even if it’s responsible for a small part. Clearly, Ioannides was attempting to report honestly, even though his own methodology has been criticized by others (the Greenland and Goodman link is one), rightly I think. Then, of course there are the recent social psychology scams which get thrown into the hopper.
We know there are some special features of today’s science –or should I say marketing– (data mining/sequester & cut-backs/drive to use on-line data to sell us everything and anything), but that should self-correct at some point in science at least.
*There’s also rivalry between favored statistical methodologies….
I got .36 for P(null| A). How do you get the power?
Your calculation of power is much easier! Fiddling with it in their false positive probability produces very odd results.
The argument in the article was put fort by Ioannidis in 2005 and has been made before I am sure. The most effective criticism at the time was that simple replication of a claim would largely get rid of the problem.
The new point is that empirical evidence, Prinz et al. and Begley/Ellis, in EXPERIMENTAL BIOLOGY where one would think the original lab would replicate its findings before publication, has very poor replication rates, 10-25% of claims. These claims can not be replicated – even by the original investigators! Stop and think of that.
People are casting about for What is the problem?
Edward Glaeser, Harvard, 2006, thinks it is not really technical. He is much more elegant with the term “researcher initiative” which is a kind way of saying researcher cheating. Now if the researcher will not provide their data sets (most do not), then it is difficult to out the cheaters (or just plain mistakes). Why would you attempt to correct things, because you are using the same unreliable methods. Massive collusion?
Science has a serious problem. Mass media is catching on.
Why should the taxpayer fund such an unreliable enterprise?
Glaeser, E. L. 2006. Researcher incentives and empirical methods. http://www.economics.harvard.edu/pub/
hier/2006/HIER2122.pdf
Stan Young mentioned Begley whose work in outing some gross errors in cancer research came up before on this blog. Here are Begley’s Six Rules for Reproducibility:
1) Were studies blinded?
2) Were all results shown?
3) Were experiments repeated?
4) Were positive and negative controls shown?
5) Were reagents validated?
6) Were the statistical tests appropriate?
http://lifescivc.com/2012/09/scientific-reproducibility-begleys-six-rules/
An earlier post by Stan Young on this blog that is directly relevant is here:
https://errorstatistics.com/2013/03/11/s-stanley-young-scientific-integrity-and-transparency/
Stan: Thanks. To allege bias, failed assumptions or even cheating,is to show the claimed error probabilities of tests don’t hold in the least. Researchers must show what they have done to scrutinize their data, models and inferences, else, as I see it it’s poor science. If they haven’t done that much, we can stop right there. But I want to distinguish those critiques from articles like this. “Mass media is catching on” true, they’re catching on how to write attention-getting articles with computations they saw somewhere. And aren’t the journals involved in pressuring authors to kick out the fuzzy qualifications and ambiguous data, and just tell a simple, dramatic story? (This was found in numerous interviews in the social psychology investigations after Stapel.) I’m curious how your own effort to reform journals is going.
(The Glaeser link is half there).
A related post questioning whether some journals should really be “casting stones” is Senn’s “Casting Stones”
https://errorstatistics.com/2013/03/07/stephen-senn-casting-stones/
Sander Greenland sends me a link to Psychology Today with a short intro that reviews these very same computations. The author thinks the P(null) shouldn’t be .9 but rather, 0, so he appeals to prior ignorance and, hey presto!, decides the incidence of true nulls is 5% Then the dominant risk becomes the Type II error, rather than the type I. But these numbers are as illicit as the ones in the Econ article. It’s rather funny that while criticizing frequentists for caring about error rates, these critics (many of them) are swept away by an abiding concern for (a Frankenstein version of) posterior error rates.
http://www.psychologytoday.com/blog/one-among-many/201211/errors-two-kinds
Economist staff reporters are not allowed to sign articles. Nearly all Economist articles are unsigned. Some years ago the Economist published an unsigned areticle on Bayes in which the probability that the sun will rise tomorrow was confused with the probability that it will always rise. It was, however, the philosopher Broad who showed in 1918 (see http://projecteuclid.org/DPubS/Repository/1.0/Disseminate?view=body&id=pdfview_1&handle=euclid.ss/1263478378 ) that the latter can never be made probable if you start with an uninformative prior. I wrote a letter to the journal pointing this out but it was never published.
Stephen: Yes I realize they don’t sign, but was needling them anyway. They did allow comments. So, what does the Sennsible one think of all this?
An article in Aug, 2013 is a lot like this one: Science’s Significant Stats Problem
http://nautil.us/issue/4/the-unlikely/sciences-significant-stats-problem
Says the author: “But with only a 5 percent chance of observing the data if there’s no effect, there’s a 95 percent chance of an effect—you can be 95 percent confident that your result is real. The problem is, that reasoning is 100 percent incorrect.” It sure is incorrect, but where in the world did you get it from?
The next 2 lines are worse…
Here are the next two lines of the mashup:
http://nautil.us/issue/4/the-unlikely/sciences-significant-stats-problem
“For one thing, the 5 percent chance of a fluke is calculatedby assuming there is no effect. If there actually is an effect,the calculation is no longer valid. Besides that, such a conclusion exemplifies a logical fallacy called “transposing the conditional.””
You just know these people are reporting various lines they’ve gotten from others without a clue of understanding. Which is it? Are they transposing or computing the prob(a p-value as small or smaller than .05;Ho)? The first accusation, I am now going to call “Jaynes conditionality fallacy”: The claim that a conditional–be it statistical or other–stops holding if the conditional assumption is false or rejected.
I have now found it in too many places to suppose it is a slip, as the Jaynesians were purporting. It also reveals a startling willingness not to think through what one is saying/repeating.
Another day, another wrong definition of statistical significance. This one from Hilda Bastion at Scientific American, in an article from yesterday. She says,
“Testing for statistical significance only estimates the probability of getting a similar result in another data set, given the same circumstances”.
http://blogs.scientificamerican.com/absolutely-maybe/2013/11/11/statistical-significance-and-its-part-in-science-downfalls/
Do any of these articles get the basics down correctly?
Very good question. I haven’t seen any on the order of popular articles; even among statisticians with an axe to grind, it’s rare. Those posting on this blog are exceptions…
That’s too bad, and should make more statisticians want to change the way people are educated about statistics as a discipline.
Nicole: I get the feeling that some of them want to jump on the bandwagon, either for a kind of “political correctness” or along the lines of what I called the “Dale Carnegie (salesman) Fallacy” https://errorstatistics.com/2013/06/22/what-do-these-share-in-common-mms-limbo-stick-ovulation-dale-carnegie-sat-night-potpourri/
There is a HUGE problem with reliability in preclinical academic research.
There are a large number of important confounds (interacting with each other, no less) that will never be balanced even using proper randomization and large samples (which often is not used) and are never repeated exactly the same in followup studies.
Researchers sample to a forgone conclusion, stopping when they run out of money or calculate p<0,05.
Researchers try out as many different types of analysis as possible to get that holy p<0,05, including dropping "outliers".
Researchers test out many different approaches (for example blaming results they don't like on "crappy antibodies", used for detecting proteins) before getting a few results in a row that looks like they could get significance if they just increase the sample size, then only report these results.
The assumptions of the statistical tests are nearly always false, nothing is normally distributed and there are always subgroups.
Few experiments really go as planned, many things are adjusted ad hoc.
These are all rational scientific behaviors (except the seeking p<0.05 part) that are incompatible with the statistics they are advised to use. However, most do not realize this or will hide that they did it to make the results "look clean".
They think they can do science without having a strong theory capable of prediction because of false interpretations of p-values. It is almost always interpreted as research hypothesis is true implicitly in the publication. This makes them think they do not have to plot all the data, instead averages and SEMs are sufficient. This then impedes strong theory formation in a positive feedback.
Torg: Thanks for your comment. Of course, we all know these things (please search the blog, if interested, especially under comedy). But not all researchers are pseudoscientific, are they? Are most? I certainly agree that theory-free science is a bad way to go. One of my main gripes is the tendency to not hold pseudoscientific users of statistics accountable, the tendency to manufacture alibis, “they couldn’t help it”, “the incentive system made them do it (e.g., hunt, snoop, search, hack)”, “there’s disagreement between frequentists and Bayesians,” “the p-value isn’t a bright line”. We’ve all known about abusing statistics, most of us, for 50+ years, e.g., Morrison and Henkel from the 60s). It used to be the researchers were faulted, now we are treated to whining, “oh it’s so-o-o-o-o hard not to selectively report my results, avoid hiding unfavorable cases, resist the urge to try and try again til my data look good.”
And by the way, legitimate statistics is scarcely limited to Normal distributions, and significance tests are THE prime tools in existence for checking your model assumptions (aside from eyeballing). That’s what they should be used for.
Mayo: The thing is that many of these practices, while incompatible with significance testing, really are good scientific detective work at heart. They have been somewhat mutated to conform to the significance testing paradigm, but it really is good to look at your data a number of ways and search for patterns.
Increasing the sample size really does get you a better picture of the effect, and if you believe you have detected subgroups in the data then it really would be inappropriate to compare “apples to oranges”. It is reasonable to believe it would be wasting everyone’s time to publish a report on data you believe has very low signal/noise ratio.
Perhaps another way of putting it is that, all preclinical research is exploratory, not confirmatory. I don’t think a Bayesian approach could help other than to (possibly) make all the subjective decisions more explicit and encourage thinking about the data generating process.
The issues are rooted in the problem of not having a theoretically predicted result to test. Using mu1=mu2 is not an appropriate substitute because it is always false, Fisher was simply wrong about this. There is no logical basis for attributing the difference to the experimental manipulation. Randomization is not magic, there are too many strong confounds.
In these cases, all the emphasis should be on reproducible and reliable description of the patterns detected, attempting to understand why each discrepancy occurs (the outliers are the interesting part of the data), until someone can come up with a theory to explain all of it.
And yes, I would consider most (>90%) of researcher behavior in this field as pseudoscientific. They simply do not know any better after multiple generations of the hypothesis-significance testing hybrid and publish or perish.
Torg: I’ve a number of comments, here are three.
You say m1 = m2 is always false. Compare this to the P(Ho) = .9 in this blog–used by many of these critics.
Two, Fisher always denied one could claim even knowledge of a real experimental effect (let alone causes) on the basis of an “isolated” case, regardless of the p-value. Causal inference, he insisted, required deliberate elaboration of sufficiently distinct predictions for tests to error correct.
Three, I find it strange that you claim it is the significance testing paradigm that enables exploratory inquiry to be misconstrued as confirmatory: It is the opposite. It is part and parcel of significance testing that one not confuse the “nominal” significance level with the actual level. It is obvious and provable that the probability of finding (through diligent, data-dependent hunting) some nominally significant result or other, due to chance, is much higher than the nominal levels.
In short, significance testing, the error statistical standpoint in general is the only one that provides a clear rationale for NOT treating the explorations–valuable as they are–the same as predesignated hypotheses. Any account that ignores error probabilities (Bayesian statistics*) can’t warrant distinguishing between them.
*There are “non-subjective” Bayesians who might include them, but then, as I see it, they become error statisticians.
Mayo: I think you are not arguing against my points. I am suggesting that all statistical “tests” (bayesian, frequentist, all of it) are inappropriate for research that is not driven by a theory capable of precise prediction. Scientists are better off hiding their data under the mattress until they think of a theory than performing these tests. Of course describing it in detail and sharing it with others is better.
Significance testing is appropriate for confirmatory studies. Unfortunately preclinical research is by its nature exploratory. Think about it, no one really wants to cure rats of cancer on average. The misconstruing occurs when significance testing is applied to the exploratory research.
Torg: I think I may be with you until the end, if I’m understanding it. When you say that significance testing, more generally, error statistical inquiry (because data generation and modeling is inseparable from this approach) would only be relevant if we wanted to cure rates of cancer on the average, which “no one really wants”, I assume you mean, what we really want is to understand the mechanisms of given diseases. Yes?
Ha. No, I meant “rats”, it was not a typo. I was attempting to convey the exploratory nature of the research being performed. Even if you can confirm you can cure rats, that is still no guarantee it would work for humans, which is what we really care about.
Oh I see, rats, so now you’ll have to explain why statistical methods are swell for rats but no good for humans. Is this a point about the problem where one must do non-experimental research?
If you are already studying rats when the eventual goal is to cure humans, you are performing exploratory research.
1) You do not actually care about the rats
2) You want to know the mechanism that determines which rats get cured and which don’t (and how fast, etc).
The research is by its very nature exploratory, trying to use confirmatory statistics and experimental design is inappropriate. All attempts to fit this type of research into the significance testing paradigm have resulted in confusion. This is for good reason.
Torg: I do not agree as to a rigid distinction (between “exploratory” work in theory building, and (so-called) “confirmation” of a theory), whether it’s between or within species. First, I might note that my own preference is to use the word “test” whenever talking about evidence, simply because to have evidence–in my philosophy–is to have probed something, and one needs to ascertain which aspects have and have not been well probed.
But more to the point, the hodge podge of low-level statistical probes are ideal “on the way” to theory building. Once we have a real theory, the statistics tends to play far less of a role, as I see it.
So, I’m confused as to where this discussion has landed us, but will have to return to it another time.
Torg:
Meant to note as regards your remark:
“Researchers sample to a forgone conclusion, stopping when they run out of money or calculate p<0,05"
I assume everyone knows this is permissible to a subjective Bayesian who is quite happy not to have to take into account things like "trying and trying again" (e.g., in the form of optional stopping.) this the "simplicity and freedom" Savage (1962) talks about. Error statisticians are forced to report that things like stopping rules alter error probabilities. For more on optional stopping, search this blog.
What I just posted as a comment on retraction watch (which talks about the increase of p-value hacking as of late):
http://retractionwatch.wordpress.com/2013/11/12/just-significant-results-have-been-around-for-decades-in-psychology-but-have-gotten-worse-study/#comment-66536
Some of the most egregious flaws I see in applying statistics to psychology experiments, especially social psychology, could not be remediated by better statistics because of the huge gap between what they’re studying and what they purport to infer. There is nothing in significance tests that licenses the jump from statistical to substantive. And the gap permits all manner of latitude to enter. The researchers need to show they have done even a fairly decent job of self-criticism as they fill those huge gaps with a lot of (often) flabby, just -so stories.
This was a little experiment to see what happens if I try to “embed” a tweet in a comment. It seems to work–but I don’t know just what it does yet.
I love this article title: Criminals in the citadel and deceit all along the watchtower: Irresponsibility, fraud, and complicity in the search for scientific truth. How can it happen that big areas of science fail to replicate 75-90% of the time. I think it is not a question of statistical technology. Virtually any style of statistics will work if applied with honesty and modest understanding. Agriculture embraced statistical methods and food is cheap. Manufacturing embraced statistics and we have lots of cheap and great things. Why there and not in many areas of science and technology? If you make something to sell, it has to work or you are out of business. Simple. In the fantasy world of the university, you just have to publish a paper. Correct? Who cares?
Stan I am new to this site, but it is confusing to me that someone is making a correlation = causation mistake on a blog devoted to statistics.
“Agriculture embraced statistical methods and food is cheap. Manufacturing embraced statistics and we have lots of cheap and great things.”
The more complete story is that RA Fisher worked in the area of agriculture and introduced randomization and design of experiments, the sure way to determine cause and effect. Manufacturing, Deming, embraced DOE, randomization etc. Science within the university is largely a cottage industry. Begley and Ellis point out that experimental biology does not randomize and does not evaluate blind, etc. He contends that there are serious technical (statistical, randomization, blinding, DOE, problems) that are at the heart of their problems. He is correct. In addition, there is no real secret to good statistical practices. As there is little effective oversight or market forces with much of science it should be not great surprise that it is failing.
Stan the technical problems definitely exist and are a major source of error. However, many of the “improper” decisions made by researchers are practical ones, and randomization is not “a sure way to determine cause and effect” . That claim is just absurd. Also, I agree that there should be a movement for separation of science and state.
Stan: This is a wonderful article, thanks for mentioning it. I read it here:
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3353596/
Prathap Tharyan, MD, MRCPsych, is Professor of Psychiatry at the Christian Medical College, Vellore, Tamil Nadu, India.
I agree with him as regards a rather controversial claim:
“Re-defining Research Misconduct is the First Step in Dealing with the Irresponsible Conduct and Reporting of Research”. He thinks even some of the lesser transgressions should only be regarded as differing in degree from out and out fraud.
Now as to your point about the importance of the threat of going out of business to instill the obligation to get it right. I agree with this,and think it’s important, but where do we place some (a minority, I presume) of the cases within drug companies, that have a lot to lose? Perhaps it’s a kind of cost-benefit analysis wherein they risk, some of them, being found out later.
Anyway, I’m extremely interested in your ideas about developing “business models” that would be applicable for science..
Mayo: Sorry if I am being annoying as a sudden new poster, but I have been clicking around and find the perspective of this blog interesting/different so wish to comment. I think the hunt for fraudsters is misguided and can easily become a witch-hunt determined punishing people based on political connections more than anything else (selection bias in who gets hunted hardest).
Fraud in science does not concern me. Why? I trust nothing that has not been independently replicated anyway, which is almost everything in preclinical research the last few decades. Fund direct replications and stop judging researchers by the number of papers published and the fraud becomes of negligible importance.
Torg: Not annoying at all, we exiles are glad for those who drop in seeking a different perspective. So you agree with Stan Young on funding replications together with initial studies. It’s an interesting idea. I don’t know enough about the particular studies you have in mind, but my philosophy of science emphasizes that what’s really wanted are stringent checks of the study, and this might not be provided by “replication” as often understood.
The same mistakes made the first time can remain uncovered the second (and it’s not obvious the researchers would know until afterwards what slings and arrows they might really need to check in a “replication”.) I have sometimes read articles that say they’ve replicated the results, where it looks more like they’ve found a way to interpret the data–once again–in support of a claim. I think there needs to be evidence that the subsequent study is capable of unearthing errors, mistakes, and biases with the first, that there is a fairly high probability that problems with the first would have ramifications for the second. The point is really to build a strong “argument from coincidence” (as we often call them) that there’s essentially no way all the studies could be producing concordant results if we are wrong about a claim of interest. Triangulation may matter more than replication (as generally understood).
Mayo: see if you can get access to this paper:
http://www.ncbi.nlm.nih.gov/pubmed/19517440
They say that the interpretation of western blot data (commonly used to try to measure if experimental manipulation affected protein levels) can be completely different due to different scanner/camera settings. This is the type of thing that persists when there is lack of direct replication for decades. For biology, all results are conditional upon the exact environment. It is only through independent direct replications that we can determine the important factors.
Ignoring this has been a huge mistake (from my reading here, I think you would agree on this), and it IS because of false faith in p-values. Yes, this is due to misuse and misunderstanding, but as I tried to say in my posts earlier this is because scientists are trying to act like scientists and explore data and refuse to believe that the statistical methods everyone is using are not telling them what they want to know. The lack of replication studies is a side effect of these misunderstandings. Read biology/medical literature from before the 1950s and you will see the behavior is much more critical and appropriate to the scientific process.
Also I really like the triangulation analogy.
How about, get the Federal Government out? Too extreme, I guess. How about, funding agencies in the area of medical observational studies, fund one group to build the data set and publicly post it, then another group to do the analysis. That way, at least, two people have to collude. But as the data set is public, they are under pressure to get it right.
It might be cost effective, for now, to double fund any proposed scientific research. Fund a replication grant at the same time. Out possible bad science as soon as possible.
And yes, some people doing clinical trials cheat. I think the number is small if they have the serious oversight of FDA. Ioannidis, 2005, JAMA, gave data that 80% of randomized clinical trials replicated.
Do you mean get the govt out of funding science? I know you’re being provocative there, but I’d really like to know if you think there’s some extra bias introduced.
I think the split data generation/data analysis is intriguing. Will any journals try this? Thanks so much for your comments.
Pingback: T. Kepler: “Trouble with ‘Trouble at the Lab’?” (guest post) | Error Statistics Philosophy
Pingback: Friday links: the history of “Big Data” in ecology, inside an NSF panel, funny Fake Science, and more | Dynamic Ecology