

.
Stephen Senn
Consultant Statistician
Edinburgh
Losing Control
Match points
The idea of local control is fundamental to the design and analysis of experiments and contributes greatly to a design’s efficiency. In clinical trials such control is often accompanied by randomisation and the way that the randomisation is carried out has a close relationship to how the analysis should proceed. For example, if a parallel group trial is carried out in different centres, but randomisation is ‘blocked’ by centre then, logically, centre should be in the model (Senn, S. J. & Lewis, R. J., 2019). On the other hand if all the patients in a given centre are allocated the same treatment at random, as in a so-called cluster randomised trial, then the fundamental unit of inference becomes the centre and patients are regarded as repeated measures on it. In other words, the way in which the allocation has been carried out effects the degree of matching that has been achieved and this, in turn, is related to the analysis that should be employed. A previous blog of mine, To Infinity and Beyond, discusses the point.
Balancing acts
In all of this, balance, or rather the degree of it, plays a fundamental part, if not the one that many commentators assume. Balance of prognostic factors is often taken as being necessary to avoid bias. In fact, it is not necessary. For example, supposed we wished to eliminate the effect of differences between centres in a clinical trial but had not, in fact, blocked by centre. We would then just by chance, have some centres in which numbers of patients on treatment and control differed. The simple difference of the two means for the trial as a whole would then have some influence from the centres, which might be regarded as biasing. However, these effects can be eliminated by the simple stratagem of analysing the data in two stages. In the first stage we compare the means under treatment and control within each centre. In the second stage we combine these differences across the centre weighting them according to the amount of information provided. In fact, including centre as a factor in a linear model to analyse the effect of treatment achieves the same result as this two-stage approach.
This raises the issue, ‘what is the value of balance?’. The answer is that other things being equal, balanced allocations are more efficient in that they lead to lower variances. This follows from the fact that the variance of a contrast based on two means is
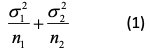
where σ21, σ22 are the variances in the two groups being compared and n1, n2 the two sample sizes. In an experimental context, it is often reasonable to proceed as if σ21 = σ22 so that writing σ2 for each variance, we have an expression for the variance of the contrast of.
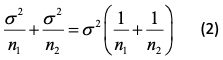
Now consider the successive ratios 1, 1/2, 1/3,…1/n. Each term is smaller than the preceding term. However, the amount by which a term is smaller is less than the amount by which the preceding term was smaller than the term that preceded it. For example, 1/3-1/4 = 1/12 but 1/2-1/3 = 1/6. In general we have 1/n – 1/n+1 = 1/n(n+1), which clearly reduces with increasing n. It thus follows that if an extra observation can be added to construct such a contrast, it will have the greater effect on reducing that contrast if it can be added to the group that has the fewest observations. This in turn implies, other things being equal, that balanced contrasts are more efficient.
Exploiting the ex-external
However, it is often the case in a randomised clinical trial of a new treatment that a potential control treatment has been much studied in the past. Thus, many more observations, albeit of a historical nature, are available for the control treatment than the experimental one. This in turn suggests that if the argument that balanced datasets are better is used, we should now allocate more patients, and perhaps even all that are available, to the experimental arm. In fact, things are not so simple.
First, it should be noted, that if blinding of patients and treating physicians to the treatment being given is considered important, this cannot be convincingly implemented unless randomisation is employed (Senn, S. J., 1994). I have discussed the way that this may have to proceed in a previous blog, Placebos: it’s not only the patients that are fooled but in fact, in what follows, I am going to assume that blinding is unimportant and consider other problems with using historical controls.
When historical controls are used there are two common strategies. The first is to regard the historical controls as providing an external standard which may be regarded as having negligible error and to use it, therefore, as an unquestionably valid reference. If significance tests are used, a one-sample test is applied to compare the experimental mean to the historical standard. The second is to treat historical controls as if they were concurrent controls and to carry out the statistical analysis that would be relevant were this the case. Both of these are inadequate. Once I have considered them, I shall turn to a third approach that might be acceptable.
A standard error
If an experimental group is compared to a historical standard, as if that standard were currently appropriate and established without error, an implicit analogy is being made to a parallel group trial with a control group arm of infinite size. This can be seen by looking at formula (2). Suppose that we let the first group be the control group and the second one the experimental group. As n1 → ∞, then formula (2) will approach σ2/n2 , which is, in fact the formula we intend to use.
Figure 1 shows the variance that this approach uses as a horizontal red line and the variance that would apply to a parallel group trial. The experimental group size has been set at 100 and the control group sample size to vary from 100 to 2000. The within group variance has been set to σ2 = 1. It can be seen that this approach of the historical standard underestimates considerably the variance that will apply. In fact even the formula given by blue line will underestimate the variance as we shall explain below.
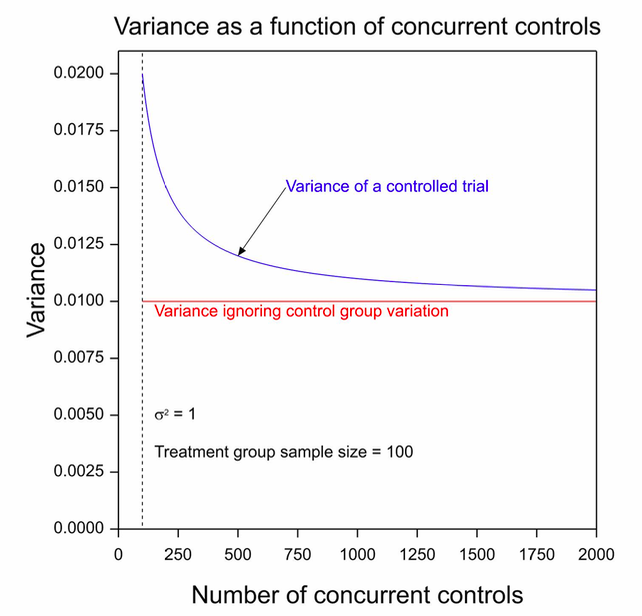
Figure 1. The variance of the contrast for a two-group parallel clinical trial for which the number of patients on the experimental arm is 100 as a function of the number on the control group arm.
It thus follows that assessing the effect from a single arm given an experimental treatment by comparison to a value from historical controls but using a formula for the standard error of σ/√n2, where σ is the within-treated group standard deviation and n2 is the number of patients, will underestimate the uncertainty in this comparison.
Parallel lies
A common alternative is to treat the historical data as if they came concurrently from a parallel group trial. This overlooks many matters, not least of which is that in many cases the data will have come from completely different centres and, whether or not they came from different centres, they came from different studies. That being so, the nearest analogue of a randomised trial is not a parallel group trial but a cluster randomised trial with study as a unit of clustering. The general set up is illustrated in Figure 2. This shows a comparison of data taken from seven historical studies of a control treatment (C) and one new study of an experimental treatment (E).
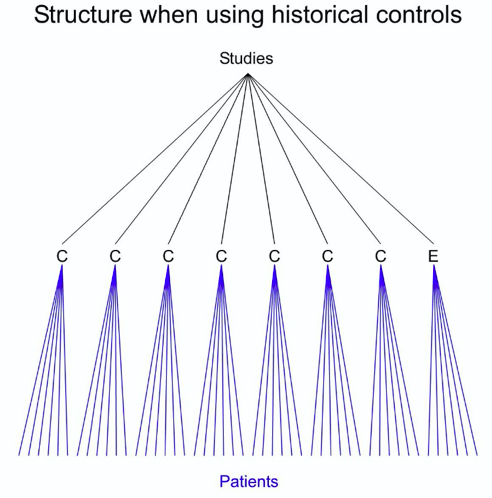
Figure 2. A data set consisting of information on historical controls (C) in seven studies and information on an experimental treatment in a new study.
This means that there is a between-study variance that has to be added to the within-study variances.
Cluster muster
The consequence is that the control variance is not just a function of the number of patients but also of the number of studies. Suppose there are k such studies, then even if each of these studies has a huge number of patients, the variance of the control mean cannot be less than ϒ2/k, where ϒ2 is the between-study variance. However, there is worse to come. The study of the new experimental treatment also has a between-study contribution but since there is only one such study its variance is ϒ2/1 = ϒ2. The result is that a lower bound for the variance of the contrast using historical data is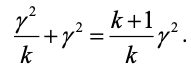
It turns out that the variance of the treatment contrast decreases disappointingly according to the number of clusters you can muster. Of course, in practice, things are worse, since all of this is making the optimistic assumption that historical studies are exchangeable with the current one (Collignon, O. et al., 2019; Schmidli, H. et al., 2014).
Optimists may ask, however, whether this is not all a fuss about nothing. The theory indicates that this might be a problem but is there anything in practice to indicate it is. Unfortunately, yes. The TARGET study provides a good example of the sort of difficulties encountered in practice (Senn, S., 2008). This was a study comparing Lumiracoxib, Ibuprofen and Naproxen in osteoarthritis. For practical reasons, centres were either enrolled in a sub-study comparing Lumiracoxib to Ibuprofen or one comparing Lumiracoxib to Naproxen. There were considerable differences between sub-studies in terms of baseline characteristics but not within sub-studies and there were even differences at outcome for lumiracoxib depending on which sub-study patients were enrolled in. This was not a problem for the way the trial was analysed, it was foreseen from the outset, but it provides a warning that differences between studies may be important.
Another example is provided by Collignon, O. et al. (2019). Looking at historical data on acute myeloid leukaemia (AML), they identified 19 studies of a proposed control treatment Azacitidine. However, the variation from study to study was such that the 1279 subjects treated in these studies would only provide, in the best of cases, as much information as 50 patients studied concurrently.
COVID Control
How have we done in the age of COVID? Not always very well. To give an example, a trial that received much coverage was one of hydroxychloroquine in the treatment of patients suffering from corona virus infection (Gautret, P. et al., 2020). The trial was in 20 patients and “Untreated patients from another center and cases refusing the protocol were included as negative controls.” The senior author Didier Raoult later complained of the ‘invasion of methodologists’ and blamed them and the pharmaceutical industry for a ‘moral dictatorship’ that physicians should resist and compared modellers to astrologers (Nau, J.-Y., 2020).
However, the statistical analysis section of the paper has the following to say
Statistical differences were evaluated by Pearson’s chi-square or Fisher’s exact tests as categorical variables, as appropriate. Means of quantitative data were compared using Student’s t-test.
Now, Karl Pearson, RA Fisher and Student were all methodologists. So, Gautret, P. et al. (2020) do not appear to be eschewing the work of methodologists, far from it. They are merely choosing to use this work inappropriately. But nature is a hard task-mistress and if outcome varies considerably amongst those infected with COVID-19, and we know it does, and if patients vary from centre to centre, and we know they do, then variation from centre to centre cannot be ignored and trials in which patients have not been randomised concurrently cannot be analysed as if they were. Fisher’s exact test, Pearson’s chi-square and Student’s t will underestimate the variation.
The moral dictatorship of methodology
Methodologists are, indeed, moral dictators. If you do not design your investigations carefully you are on the horns of a dilemma. Either, you carry out simplistic analyses that are simply wrong or you are condemned to using complex and often unconvincing modelling. Far from banishing the methodologists, you are holding the door wide open to let them in.
Acknowledgement
This is based on work that was funded by grant 602552 for the IDEAL project under the European Union FP7 programme and support from the programme is gratefully acknowledged.
References
Collignon, O., Schritz, A., Senn, S. J., & Spezia, R. (2019). Clustered allocation as a way of understanding historical controls: Components of variation and regulatory considerations. Statistical Methods in Medical Research, 962280219880213
Gautret, P., Lagier, J. C., Parola, P., Hoang, V. T., Meddeb, L., Mailhe, M., . . . Raoult, D. (2020). Hydroxychloroquine and azithromycin as a treatment of COVID-19: results of an open-label non-randomized clinical trial. Int J Antimicrob Agents, 105949
Nau, J.-Y. (2020). Hydroxychloroquine : le Pr Didier Raoult dénonce la «dictature morale» des méthodologistes. Retrieved from https://jeanyvesnau.com/2020/03/28/hydroxychloroquine-le-pr-didier-raoult-denonce-la-dictature-morale-des-methodologistes/
Schmidli, H., Gsteiger, S., Roychoudhury, S., O’Hagan, A., Spiegelhalter, D., & Neuenschwander, B. (2014). Robust meta‐analytic‐predictive priors in clinical trials with historical control information. Biometrics, 70(4), 1023-1032
Senn, S. J. (2008). Lessons from TGN1412 and TARGET: implications for observational studies and meta-analysis. Pharmaceutical Statistics, 7, 294-301
Senn, S. J. (1994). Fisher’s game with the devil. Statistics in Medicine, 13(3), 217-230
Senn, S. J., & Lewis, R. J. (2019). Treatment Effects in Multicenter Randomized Clinical Trials. JAMA


")


Stephen:
I’m extremely grateful for this guest post from you. Gelman has a blogpost today asking whether we would be, or would have been, better off without randomized controlled trials–a question that might be answerable if we could do a controlled trial. His view is that statistical significance tests (which he used to endorse) are so bad that the net value of controlled trials might be negative. But if he agrees, as he claims to, that RCTs have value, then he is endorsing the counterfactual reasoning they enable in learning about effects of interventions. Non randomized methods for causal inquiry succeed where they by mimicking the counterfactual knowledge gained by randomization (in all of its variants). I think he is mainly being provocative.
It must be fascinating for you, with the knowledge you have, to watch the methodology in today’s covid-19 research. It would be great to know what you think of some of the other covid-19 appraisals coming down the pike, and the manner in which controlled trials are being relied upon. I’ll send some examples when I have them.
I’ll have to think some more about your last paragraph and methodologists being moral dictators.
Thank you Stephen Senn for your fine review of proper analysis of blocked designs that include fixed and random (repeated measures) factors, and the consequences of balanced and unbalanced designs with respect to variance.
These issues do matter, despite Raoult’s complaints and Gelman’s provocations.
As to Gelman, the less said the better.
As to Raoult’s comparison of modelers to astrologers, all I can say is “Project much?” The howlings of so many unqualified or misguided coronavirus commenters reflects more upon their own fears and failings, not exactly helpful in the midst of a pandemic. Viruses of course care little about the egos of the unqualified who merely seek the limelight, and those of us who fall for such rhetoric also risk falling prey to the little ball of RNA.
By now the evidence is clear that the effects of this virus are not the same as influenza, and it isn’t going away in the summer heat as another seeker of the limelight opined just weeks ago. A resurgence of infections in The Sun Belt of America in the middle of the summer has yet to convince the sycophantic followers of said limelight seeker that scientists and modelers have much better advice and guidance, as Senn has provided here.
Anyone evaluating the next un-peer-reviewed offerings on biorXiv would do well to keep Senn’s points in mind while doing so.
Raoult is a brilliant and unorthodox virologist who has been put off by incompetent formalistic statisticians who live by unthinkingly imposing dogmas. There are a lot of very arrogant powerful persons in the higher regions of French academia and they are not necessarily actually expert in the fields in which they operate. Continental (European) statistics has suffered greatly by the dominance of formalistic mathematicians without real statistical intuition or statistical training. I’ve seen that in Germany and in France. Times are fortunately changing. Generations are succeeding generations. (And of course, the Southern European temperament is something else again).
Someone once said that the Danish statistical school formed the mathematical conscience which UK statistics badly needed. BTW I’ve been in the business for 45 years and my background is England –> Netherlands and Scandinavia.
Second try to post this. WordPress is misbehaving today.
The Gautret et al. paper and data set deserves a professional statistical follow-up and I’m preparing one right now, at least, making the attempt. All French medical professionals are on holiday for all of July, so writing and publication are delayed. Of course, the paper had some obligatory p-values, otherwise, it could not have been published. The lead author Philippe Gautret does not like statisticians or statistics much, and the final author, Didier Raoult (director of the institute) even less. They do have some good reasons for this, as well, of course, as some bad reasons. The p-values were obtained by the epidemiologist on their team, a rather young (PhD student) medical doctor – epidemiologist from Vietnam. His age and his oriental deference to his seniors means that his opinion bears no weight among them. At least he agreed with me that the analysis should at least have followed the “intention to treat” principle. However, the medical doctors (professors in various medical disciplines) are insistent that those patients who drop out of the study for whatever reason have to be dropped from the analysis. They are only interested in the ones who managed to complete their course of treatment. The ones who got so sick that they had to be transferred to ICU did not “complete the prescribed course of treatment” so are not interesting.
I’m afraid, it seems that good statisticians in Marseilles (both junior and senior) are more interested in proving theorems which can be published in the Annals of Statistics, than in solving urgent real-life statistical problems. I know some good people there. Tried to get them interested. No interest.
This data set is a jewel. It’s an observational study, with n << p. The sample size n is 42.
I have a similar data set from a Dutch GP from the catholic South of the country (where our epidemic started, thanks to returning winter sports lovers and “Carnival”) which is almost a randomised trial. He treated the more or less first ca. 20 patients with Covid-19 in the Netherlands as they turned up at his practice in the “standard” way (as it was back then). They all got very sick and many died. He treated the next 15 with HCQ. Almost all got better. The authorities banned HCQ. He could not give the next five patients HCQ. They got very sick, and many died.
This data set is a jewel. It’s an observational study, with n << p. The sample size n is 40.
I already posted a number of analyses of the basic 2×2 tables on my RPubs site. In particular, the conventional Fisher's exact test gives the impression of an incredibly strong result, but a decent Bayesian analysis gives a much more "responsible" conclusion. I also tried out JASP, the University of Amsterdam's alternative to SPSS. I think that their approach to model selection and then estimation is unsound, in fact, from a stringent Bayesian point of view, inconsistent. At the very least, the user's guide and the automatically supplied annotations on the generated statistical report are misleading. This will cause just as much chaos and disasters among the medical and psychologist users in the future, as SPSS did in the past.
On another topic, I recently did a lot of editing of Wikipedia's web page on p-values. I had made some changes more than a year ago but they had been reverted, no doubt by a well-
meaning researcher in psychology or medicine. I think it is really important that relevant scientific communities keep a close eye on central wikipedia articles! I hope some readers of this blog will feel so inclined.
Thanks, Richard. I shall, of course, be very interested to learn what you find in your re-analysis of the Gautret et al data in due course. However, I want to underline one point in my post.
We can imagine an allocation process in which concurrently and in a number of centres, patients have been carelessly and in a rather biased way, allocated to treatment and control, the result being that imbalanced important prognostic factors will produce an obviously biased answer unless some remedial action is taken. (My personal philosophy is that it is the prognostic aspect of this that is more important than any imbalance but I shall not pursue this here. See https://errorstatistics.com/2020/04/20/s-senn-randomisation-is-not-about-balance-nor-about-homogeneity-but-about-randomness-guest-post/ for a discussion). It is generally agreed that the usual cure to this involves either Propensity Score stratification (which I don’t like) or analysis of covariance (which I prefer).
It has been an all too frequent habit, to treat historical data, or data from patients in other centres, as if they were somehow like the case described above. They are not. A more appropriate, if still imperfect, model to start with, is that of cluster randomisation rather then a parallell group trial. My argument is that one should start by regarding such data as coming from a deficient cluster randomised trial and not a deficient parallel group trial. John Nelder’s approach to this is extremely revealing. It shows that if one treats such data as coming from a parallel group trial and corrects for covariates accordingly, one is implicitly making an assumption that the appropriate slopes are within-centre slopes only and that the appropriate variances are within-centre variances only.
Note, that I am not saying that such an assumption could not be made. I am saying that I would like to see it explicitly stated, so that it is not overlooked. This is essentially the point I made about the treatments of Lord’s Paradox in The Book of Why.in a previous blog on this site.https://errorstatistics.com/2018/11/11/stephen-senn-rothamsted-statistics-meets-lords-paradox-guest-post/
Yesterday I corrected Wikipedia’s description of p-values and today my correction had already been reverted by an enthusiastic anonymous editor. Please, friends of p-values, take a look and join in the good fight! https://en.wikipedia.org/wiki/P-value . It will help to add authoritative sources as references, and to contribute to the “talk” pages.
RCTs are getting a boost in this JAMA article
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2768843?utm_source=twitter&utm_medium=social_jamajno&utm_term=3535207300&utm_campaign=article_alert&linkId=95554318
Raoult may well be a brilliant and unorthodox virologist who has been put off by incompetent formalistic statisticians who live by unthinkingly imposing dogmas, but he should find some competent statisticians to help him design decent studies, rather than touting findings from a small sample from which he excluded inconvenient cases to enhance the outcome he desired.
Subsequent randomized trials have repeatedly shown no benefit for hydroxychloroquine.
This is a textbook example of what the JAMA article referenced by Mayo demonstrates, that observational studies miss the mark more often than not when compared to corresponding randomized clinical trials.
——————————————————————————–
New England Journal of Medicine: Boulware et al. (doi:10.1056/NEJMoa2016638)
A Randomized Trial of Hydroxychloroquine as Postexposure Prophylaxis for Covid-19.
After high-risk or moderate-risk exposure to Covid-19, hydroxychloroquine did not prevent illness compatible with Covid-19 or confirmed infection when used as postexposure prophylaxis within 4 days after exposure.
——————————————————————————–
Annals of Internal Medicine: Skipper et al. (doi:10.7326/M20-4207)
Hydroxychloroquine in Nonhospitalized Adults With Early COVID-19, A Randomized Trial
Hydroxychloroquine did not substantially reduce symptom severity or prevalence over time in nonhospitalized persons with early COVID-19.
——————————————————————————–
RECOVERY Trial, Oxford:
A total of 1542 patients were randomised to hydroxychloroquine and compared with 3132 patients randomised to usual care alone. There was no significant difference in the primary endpoint of 28-day mortality (25.7% hydroxychloroquine vs. 23.5% usual care; hazard ratio 1.11 [95% confidence interval 0.98-1.26]; p=0.10). There was also no evidence of beneficial effects on hospital stay duration or other outcomes. These data convincingly rule out any meaningful mortality benefit of hydroxychloroquine in patients hospitalised with COVID-19. Full results will be made available as soon as possible.
(Hydroxychloroquine was dropped early in the RECOVERY trial, and a recent report (DOI: 10.1056/NEJMoa2021436) discusses some positive findings for dexamethasone.)
——————————————————————————–
New England Journal of Medicine: Cavalcanti et al. (doi:10.1056/NEJMoa2019014)
Among patients hospitalized with mild-to-moderate Covid-19, the use of hydroxychloroquine, alone or with azithromycin, did not improve clinical status at 15 days as compared with standard care.
——————————————————————————–
MedRxiv: Horby et al. (doi:10.1101/2020.07.15.20151852v1)
Effect of Hydroxychloroquine in Hospitalized Patients with COVID-19: Preliminary results from a multi-centre, randomized, controlled trial.
(which was not certified by peer review)
Conclusions: In patients hospitalized with COVID-19, hydroxychloroquine was not associated with reductions in 28-day mortality but was associated with an increased length of hospital stay and increased risk of progressing to invasive mechanical ventilation or death.
Steven McKinney, I would just say that I think that the court is still out on this one. Take a look at https://www.math.leidenuniv.nl/~gill/Presentation.pdf and at https://www.youtube.com/watch?v=5hA73hpgR18
Both my slides and the video presentation got better: https://www.youtube.com/watch?v=AVmWvuc3Uew The point is, we already knew you shouldn’t give HCQ to seriously ill Covid-19 patients in intensive care. But we still don’t know whether or not it has prophylactic value. A number of good studies shows that it possibly does. I haven’t seen any study which shows the contrary. The study which is usually used to blow up the treatment, is pretty worthless, and in fact suggests, if anything, that the treatment helps. That Didier Raoult and his colleagues need to work with some good statisticians is obvious. I hope I am teaching them that there is value in good statistics.
Richard:
If it hadn’t become politicized, they may be able to have found out.
I think people should focus on the mechanism of action. As an anti-inflammatory that people with rheumatoid arthritis take, its mode of action would be similar to other anti-inflammatories, and possibly beneficial at the stage of covid where anti-inflammatories do some good. However, I read a genuine expert on this (I’d have to dig up the article) explain that it is simply not strong enough for what’s needed for most covid cases.
How might it work as a preventative?
Endlessly pouring over these small samples of convenience is not going to bring any sufficient degree of precision to statistics needed to answer the hydroxychloroquine efficacy question.
Why are there 16 controls in the Gautret/Raoult study? From the Gautret et al. paper
“Patients who were proposed a treatment with hydroxychloroquine were recruited and managed in the Marseille centre. Controls without hydroxychloroquine treatment were recruited in Marseille, Nice, Avignon and Briancon centers, all located in Southern France.”
How were 26 patients available at Marseille, and across Marseille, Nice, Avignon and Briancon centers, only 16 controls were available? This strains credulity, and such a treatment/control imbalance doesn’t help the analysis precision any.
This study, despite its small p-value, is an observational study of a convenience sample with a very low level of medical evidence.
“We badly need a big RCT with n at least 1000”
The RECOVERY study at Oxford (enrolling over 11,000 patients from 175 NHS hospitals in the UK) concluded:
“A total of 1542 patients were randomised to hydroxychloroquine and compared with 3132 patients randomised to usual care alone. There was no significant difference in the primary endpoint of 28-day mortality (25.7% hydroxychloroquine vs. 23.5% usual care; hazard ratio 1.11 [95% confidence interval 0.98-1.26]; p=0.10). There was also no evidence of beneficial effects on hospital stay duration or other outcomes.”
(The Horby et al. MedRxiv pre-publication print is from the RECOVERY study as well)
Cavalcanti et al. declare that an a-priori power analysis suggested 80% power to detect an odds ratio of 0.57 with a sample size of 210 cases in 3 arms (667 cases enrolled), and concluded “Among patients hospitalized with mild-to-moderate Covid-19, the use of hydroxychloroquine, alone or with azithromycin, did not improve clinical status at 15 days as compared with standard care.” If odds ratios closer to 1.0 need to be detected, then this study won’t contribute there. But it certainly rules out an effect of the size claimed in the Gautret/Raoult effort.
Boulware et al. assessed early administration of hydorxychloroquine. “Trial enrollment began on March 17, 2020, with an eligibility threshold to enroll within 3 days after exposure; the objective was to intervene before the median incubation period of 5 to 6 days.” 821 asymptomatic adult participants who were randomly assigned to the hydroxychloroquine group (414 participants) or the placebo group (407 participants). They found “In this randomized, double-blind, placebo-controlled trial, we investigated the efficacy of hydroxychloroquine as Covid-19 postexposure prophylaxis. In this trial, high doses of hydroxychloroquine did not prevent illness compatible with Covid-19 when initiated within 4 days after a high-risk or moderate-risk exposure.”
Skipper et al. assessed 423 cases (Of 491 patients randomly assigned to a group, 423 contributed primary end point data.) The 68 cases who provided no data present a problem for this study, so their conclusion that “Hydroxychloroquine did not substantially reduce symptom severity or prevalence over time in nonhospitalized persons with early COVID-19” can’t be classed with high level evidence findings.
The Risch paper shown on p27 of the Gill presentation linked above is an opinion piece that states “Conflict of Interest: Dr. Risch acknowledges past advisory consulting work with two of the more than 50 manufacturers of hydroxychloroquine, azithromycin and doxycycline.” and reviews many studies, mostly observational.
If hydroxycholorquine was doing anything as remarkable as claimed in the Gautret/Raoult paper (odds ratio near 10), it should have shown up readily in these larger studies.
Steven, I agree with most of what you write, and I even say a lot of what you say in my presentation. Your characterisation of the Risch paper is very unfair. Perhaps you have a conflict of interest, yourself? My present opinion is that we still don’t know and that there are as many positive indications as negative. Not for an amazing odds ratio of 10, but certainly for something modest but medically significant like 2. A large enough RCT is presently underway in the US. We have a second wave, so plenty more cases in the pipeline. In fact, we have a probably permanent endemic now. So in a few months we may know more.
PS actually the first morals which I draw from these two n = 40 studies is that a standard modern Bayesian analysis gives us much, much more reasonable indication of what they tell us (namely:almost nothing) than the standard p-values with which the Gautret et al paper is liberally sprinkled.
Many disciplined studies of hydroxychloroquine now available.
Repeated re-analysis of small, cobbled patchwork data sets no longer necessary.
The findings are repeatedly clear: Hydroxychloroquine is not useful in the treatment of COVID-19.
Disciplined studies – that’s how we learn the truth.
Brazilian trial 1, 2020:
JAMA Network Open. 2021;4(4):e216468. doi:10.1001/jamanetworkopen.2021.6468
“The TOGETHER Trial is a randomized clinical trial to investigate the efficacy of repurposed treatments for SARS-CoV-2 infection among high-risk adult outpatients.”
ClinicalTrials.govIdentifier:NCT04403100
Findings: This randomized clinical trial found no clinical benefit to support the use of either hydroxychloroquine or lopinavir-ritonavir in an outpatient population.
Brazilian trial 2, 2021:
Scientific Reports (2021) 11:9023 | https://doi.org/10.1038/s41598-021-88509-9
“A multicenter, open-label, RCT was conducted in six hospitals in Curitiba, Brazil, by the Center of Study and Research on Intensive Care Medicine (CEPETI).”
ClinicalTrials.gov, NCT04420247
Findings: In conclusion, the addition of Clq/HClq to standard care in patients admitted to the hospital with severe COVID-19 resulted in clinical worsening and higher incidences of IMV and renal dysfunction, even though there was no difference in mortality. According to these findings, the use of Clq/HClq in patients with more severe forms of COVID-19 pneumonia is strongly contraindicated
Canadian trial, 2020:
CMAJ Open 2021. DOI:10.9778/cmajo.20210069
“This investigator-initiated, randomized, double-blind, placebo controlled trial was conducted in Alberta, with enrolment beginning Apr. 15, 2020.”
ClinicalTrials.gov, no. NCT04329611
Findings: There was no evidence that hydroxychloroquine reduced symptom duration or prevented severe outcomes among outpatients with proven COVID-19, but the early termination of our study meant that it was underpowered.
Canadian and UAE meta analysis, 2021:
PLOS ONE | https://doi.org/10.1371/journal.pone.0244778
“We electronically searched EMBASE, MEDLINE, the Cochrane COVID-19 Register of Controlled Trials, Epistemonikos COVID-19, clinicaltrials.gov, and the World Health Organization International Clinical Trials Registry Platform up to September 28th, 2020 for randomized controlled trials (RCTs). We calculated pooled relative risks (RRs) for dichotomous outcomes with the corresponding 95% confidence intervals (CIs) using a random-effect model. We identified four RCTs (n = 4921) that met our eligibility criteria.”
Findings: Although pharmacologic prophylaxis is an attractive preventive strategy against COVID-19, the current body of evidence failed to show clinical benefit for prophylactic hydroxychloroquine and showed a higher risk of adverse events when compared to placebo or no prophylaxis.
USA, UK, Nigeria meta analysis, 2021:
Am J Cardiovasc Dis 2021;11(1):93-107
“We systematically searched the PubMed, Embase, MEDLINE, Cochrane CENTRAL, CINAHL, Scopus, Joanna Briggs Institute Database, ClinicalTrials.gov, and Chinese Clinical Trial Registry (ChiCTR) for all articles published between 01 January 2020 to 15 September 2020 on CQ/HCQ and COVID-19 using a predefined search protocol; without any language restrictions.”
“Eleven RCTs, presented in Table 1, include six peer-reviewed published studies and five preprints comprising a total of 7,184 patients (Mean age = 57.6 years, SD = 18.5 years, 39.6% women) across nine countries.”
Findings: Evidence from currently published RCTs do not demonstrate any added benefit for the use of CQ or HCQ in the treatment of COVID-19 patients. Unless future clinicals trials prove otherwise, our findings suggest that research efforts should be directed towards other potential treatment options to control this and future coronavirus outbreaks.
Qatar RCT, 2020:
EClinicalMedicine 29-30 (2020) 100645
“Q-PROTECT employed a prospective, placebo-controlled design with blinded randomization to three parallel arms: placebo, oral HC (600 mg daily for one week), or oral HC plus oral AZ (500 mg day one, 250 mg daily on days two through five).”
ClinicalTrials.gov (NCT04349592)
Findings: HC+/-AZ does not facilitate virologic cure in patients with mild or asymptomatic Covid-19. HC, with or without AZ, is highly unlikely to result in meaningful benefit in patients with mild or asymptomatic Covid-19.
USA RCT 2020:
JAMA. 2020;324(21):2165-2176. doi:10.1001/jama.2020.22240
“This was a multicenter, blinded, placebo-controlled randomized trial conducted at 34 hospitals in the US.”
ClinicalTrials.gov: NCT04332991
Findings: Among adults hospitalized with respiratory illness from COVID-19, treatment with hydroxychloroquine, compared with placebo, did not significantly improve clinical status at day 14. These findings do not support the use of hydroxychloroquine for treatment of COVID-19 among hospitalized adults.
USA, Canada RCT 2020:
N Engl J Med 2020;383:517-25. DOI: 10.1056/NEJMoa2016638
“We conducted a randomized, double-blind, placebo-controlled trial across the United States and parts of Canada testing hydroxychloroquine as postexposure pro- phylaxis.”
ClinicalTrials.gov number, NCT04308668
Findings: After high-risk or moderate-risk exposure to Covid-19, hydroxychloroquine did not prevent illness compatible with Covid-19 or confirmed infection when used as postexposure prophylaxis within 4 days after exposure.
The latest on Didier Raoult:
French scientist who promoted one of Trump’s favorite coronavirus cures set to be replaced
By
Rick Noack
September 17, 2021 at 2:13 p.m. EDT
MARSEILLE, France — A French microbiologist who became a controversial figure in the science world — and gained a popular cult following — for promoting dubious cures for covid-19 is set to be replaced in his high-profile position.
Officials have partially blamed Raoult’s videos for a vaccination divide that has led to a surge in new hospitalizations and deaths in Marseille, even though France’s overall number of new cases has been dropping.
At a publicly run vaccination center set up to tackle the imbalance in one of the city’s northern districts, only a few people had shown up to get a shot when Jouve [the head of the local hospital network’s medical commission} arrived that day.
“A 10-minute talk by Didier Raoult on YouTube,” he said, means “entire days of door-to-door discussions or educational work that has to be done in the northern districts to convince people to come and get vaccinated.”
https://www.washingtonpost.com/world/europe/didier-raoult-hydroxychloroquine/2021/09/17/a56c5bd4-1574-11ec-a019-cb193b28aa73_story.html
Read a newspaper and published journal articles for decent information on important topics such as a global pandemic. Youtubers are not well vetted, if vetted at all.