

.
Stephen Senn
Consultant Statistician
Edinburgh, Scotland
Alpha and Omega (or maybe just Beta)
Well actually, not from A to Z but from AZ. That is to say, the trial I shall consider is the placebo- controlled trial of the Oxford University vaccine for COVID-19 currently being run by AstraZeneca (AZ) under protocol AZD1222 – D8110C00001 and which I considered in a previous blog, Heard Immunity. A summary of the design features is given in Table 1. The purpose of this blog is to look a little deeper at features of the trial and the way I am going to do so is with the help of geometric representations of the sample space, that is to say the possible results the trial could produce. However, the reader is warned that I am only an amateur in all this. The true professionals are the statisticians at AZ who, together with their life science colleagues in AZ and Oxford, designed the trial.
Whereas in an October 20 post (on PHASTAR) I considered the sequential nature of the trial, here I am going to ignore that feature and only look at the trial as if it had a single look. Note that the trial employs a two to one randomisation, twice as many subjects being given vaccine as placebo
However, first I shall draw attention to one interesting feature. Like the two other trials that I also previously considered (one by BioNTech and Pfizer and the other by Moderna) the null hypothesis that is being tested is not that the vaccine has no efficacy but that its efficacy does not exceed 30%. Vaccine Efficacy (VE) is defined as
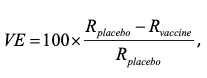
Where Rplacebo & Rvaccine are the ‘true’ rates of infection under placebo and vaccine respectively
Obviously, if the vaccine were completely ineffective, the value of VE would be 0. Presumably the judgement is that a vaccine will be of no practical use unless it has an efficacy of 30%. Perhaps a lower value than this could not really help to control the epidemic. The trial is designed to show that this is the case. In what follows, you can take it as read that the probability of the trial failing because the efficacy is equal to some value that is less than 30% (such as 27%, say) is even greater than if the value is exactly 30%. Therefore, it becomes of interest to consider the way the trial will behave if the value is exactly 30%.
Figuring it out
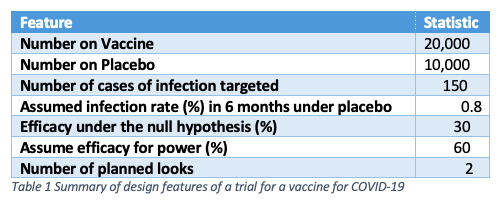
Figure 1 gives a representation of what might happen in terms of cases of infected subjects in both arms of the trial based on its design. It’s a complicated diagram and I shall take some time to explain it. For the moment I invite the reader to ignore the concentric circles and the shading. I shall get to those in due course.
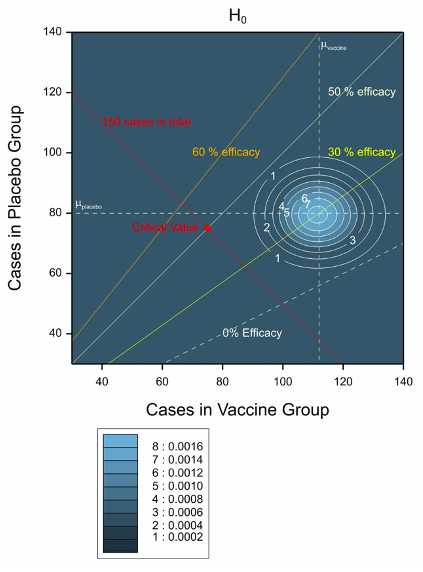 Figure 1 Possible and expected outcomes for the trial plotted in the two dimensional space of vaccine and placebo cases of infection. The contour plot applies when the null hypothesis is true.
Figure 1 Possible and expected outcomes for the trial plotted in the two dimensional space of vaccine and placebo cases of infection. The contour plot applies when the null hypothesis is true.The X axis gives the number of cases in the vaccine group and the Y axis the number of cases under Placebo. It is important to bear in mind that twice as many subjects are being treated with vaccine as with placebo. The line of equality of infection rates is given by the dashed white diagonal line towards the bottom right hand side of the pot and labelled ‘0% efficacy’. This joins (for example) the points (80,40) and (140, 70) corresponding to twice as many cases under vaccine as placebo and reflecting the 2:1 allocation ratio. Other diagonal lines correspond to 30%, 50% and 60% VE respectively.
The trial is deigned to stop once 150 cases of infection have occurred. This boundary is represented by the diagonal solid red line descending from the upper left (30 cases in the vaccine group and 120 cases in the placebo group) towards the bottom right (120 cases in the vaccine group and 30 cases in the placebo group). Thus, we know in advance, that the combination of results we shall see must lie on this line.
Note that the diagram is slightly misleading, since where the space concerned refers to number of cases, it is neither continuous in X nor continuous in Y. The only possible values are those given by the whole numbers, W, that is to say the integers plus zero. However, the same is not true for expected numbers and this is a common difference between parameters and random variables in statistics. For example, if we have a Poisson random variable with a given mean, the only possible values of the random variable are the whole numbers 0,1,2… but the mean can be any positive real number.
Ripples in the pond
Figure 2 is the same diagram as Figure 1 as regards every feature except that which I invited the reader to ignore. The concentric circles are contour plots that represent features of the trial that are suitable for planning. In order to decide how many subjects to recruit, the scientists at AZ and Oxford had to decide what infection rate was likely. They chose an infection rate of 0.8% per 6 months under placebo. This in turn implies that of 10,000 subjects treated with placebo, we might expect 80 to get COVID. On the other hand, a vaccine efficacy of 30% would imply an infection rate of 0.56% since
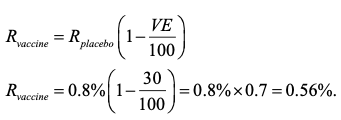
For 20,000 subjects treated with vaccine we would expect (0.56/100)20,000 = 112 of them to be infected with COVID and if the vaccine efficacy were 60%, the value assumed for the power calculation, then the expected infection rate would be 0.32% and we would expect 64 of the subjects to be infected.
Since the infection rates are small, a Poisson distribution is a possible simple model for the probability of seeing certain combinations of infections. This is what the contour plots illustrate. For both cases, the expected number of cases under placebo is assumed to be 80 and this is illustrated by a dashed horizontal white line. However, the lower infection rate under H1 has the effect of shifting the contour plots to the left. Thus, in Figure 1 the dashed vertical line indicating the expected numbers in the vaccine arm is at 112 and in Figure 2 it is at 64. Nothing else changes between the figures.
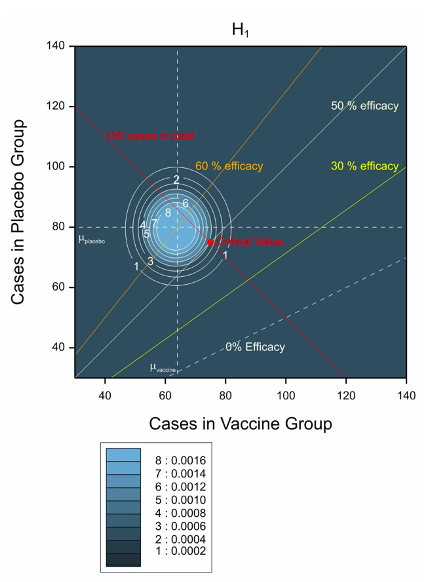
Figure 2 Possible and expected outcomes for the trial plotted in the two dimensional space of vaccine and placebo cases of infection. The contour plot applies when the value under the alternative hypothesis assumed for power calculations is true.
Test bed
How should we carry out a significance test? One way of doing so is to condition on the total number of infected cases. The issue of whether to condition or not is a notorious controversy ins statistics, Here the total of 150 is fixed but I think that there is a good argument for doing so whether or not it is fixed. Such conditioning in this case leads to a binomial distribution describing the number of cases of infection observed out of the 150 that are in the vaccine group. Ignoring any covariates, therefore, a simple analysis, is to compare the proportion of cases we see to the proportion we would expect to see under the null hypothesis. This proportion is given by 112/(112+80)=0.583. (Note a subtle but important point here. The total number of cases expected is 192 but we know the trial will stop at 150. That is irrelevant. It is the expected proportion that matters here.)
By trial and error or by some other means we can now discover that the probability of 75 or fewer cases given vaccine out of 150 in total when the probability is 0.583 is 0.024.The AZ protocol requires a two-sided P-value less than or equal to 4.9%, which is to say 0.0245 one sided, assuming the usual doubling rule, so this is just low enough. On the other hand, the probability of 76 or fewer cases under vaccine is 0.035 and thus too high. This establishes the point X=75, Y=75 as a critical value of the test. This is shown by the small red circle labelled ‘critical value’ on both figures. It just so happens that this lies along the 50% efficacy line. Thus observed 50% efficacy will be (just) enough to reject the hypothesis that the true efficacy is 30% or lower.
Reading the tea-leaves
There are many other interesting features of this trial I could discuss, in particular what alternative analyses might be tried (the protocol refers to a ‘modified Poisson regression approach’ due to Zou, 2004) but I shall just consider one other issue here. That is that in theory when the trial stops might give some indication as to vaccine efficacy, a point that might be of interest to avid third party trial-watchers. If you look at Figure 3, which combines Figure 1 and Figure 2, you will note that the expected number of cases under H0, if the values used for planning are correct, is at least (when vaccine efficacy is 30%) 80+112=192. For zero efficacy the figure is 80+160=240. However, the trial will stop once 150 cases of infection have been observed. Thus, under H0, the trial is expected to stop before all 30,000 subjects have had six months of follow-up.
On the other hand, for an efficacy of 60% given in Figure 3 the value is 80+64 =144 and so slightly less then the figure required. Thus, under H1, the trial might not be big enough. Taken together, these figures imply that other things being equal, the earlier the trial stops the more likely the result is to be negative and the longer it continues, the more likely it is to be positive.
Of course, this raises the issue as to whether one can judge what is early and what is late. To make some guesses as to background rates of infection is inevitable when planning a trial. One would be foolish to rely on them when interpreting it.
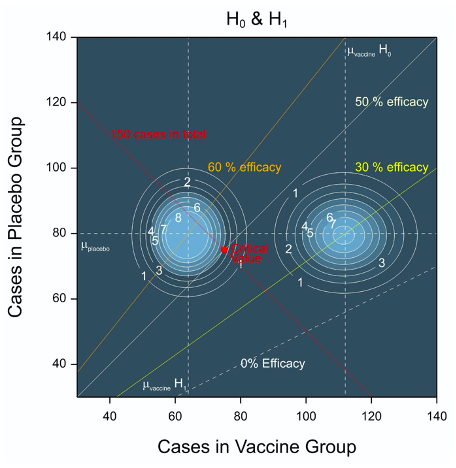
Figure 3 Combination of Figures 1 and 2 showing contour plots for the joint density for the number of cases when the vaccine efficacy is 30% (H0) and the value under H1 of 60% used for planning.
Reference
Zou G. A modified poisson regression approach to prospective studies with binary data. Am J Epidemiol. 2004;159(7):702-6.
POSTSCRIPT: Needlepoint
Pressing news
Extract of a press-release from Pfizer, 9 November 2020:
“I am happy to share with you that Pfizer and our collaborator, BioNTech, announced positive efficacy results from our Phase 3, late-stage study of our potential COVID-19 vaccine. The vaccine candidate was found to be more than 90% effective in preventing COVID-19 in participants without evidence of prior SARS-CoV-2 infection in the first interim efficacy analysis.” Albert Bourla (Chairman and CEO, Pfizer.)
Naturally, this had Twitter agog and calculations were soon produced to try and reconstruct the basis on which the claim was being made: how many cases of COVID-19 infection under vaccine had there been seen in order to be able to make this claim? In the end these amateur calculations don’t matter. It’s what Pfizer calculates and what the regulators decide about the calculation that matters. I note by the by that a fair proportion of Twitter seemed to think that journal publication and peer review is essential. I don’t share this point of view, which I tend to think of as “quaint”. It’s the regulator’s view I am interested in but we shall have to wait for that.
Nevertheless, calculation can be fun and if I don’t think so, I am in the wrong profession. So here goes. However, first I should acknowledge that Jen Rogers’s interesting blog on the subject has been very useful in preparing this note.
The back of the envelope
To do the calculation properly, this is what one would have to know
|
Need to know |
Discussion |
|
Disposition of Subjects |
Randomisation was one to one but strictly speaking we want to know the exact achieved proportions. BusinessWire describe a total of “43,538 participants to date, 38,955 of whom have received a second dose of the vaccine candidate as of November 8, 2020”. |
|
Number of cases of infection |
According to BusinessWire 94 were seen. |
|
Method of analysis |
Pfizer claims in the protocol a Bayesian analysis will be used. I shall not attempt this but use a very simple frequentist one conditioning on totals infected. |
|
Aim of claim |
Is the point estimate the basis of the claim or is the lower bound of some confidence interval the basis? |
|
Level of confidence to be used |
Pfizer planned to look five times but it seems that the first look was abandoned. The reported look is the 2nd but at a number of cases that is slightly greater (94) than the number originally planned for the 3rd (92). I shall assume that the confidence level for look three of an O’Brien-Fleming boundary is appropriate. |
|
Missingness |
A simple analysis would assume no missing data or at least that any missing data are missing completely at random. |
|
Other matters |
Two doses are required. Were there any cases arising between the two doses and if so, what was done with them? |
If I condition on the total number of infected cases, and assume equal numbers of subjects on each arm, then by varying the number of cases in the vaccine group and subtracting them from the total of 94 to get those on the control group arm, I can calculate the vaccine efficacy. This has been done in the figure below.
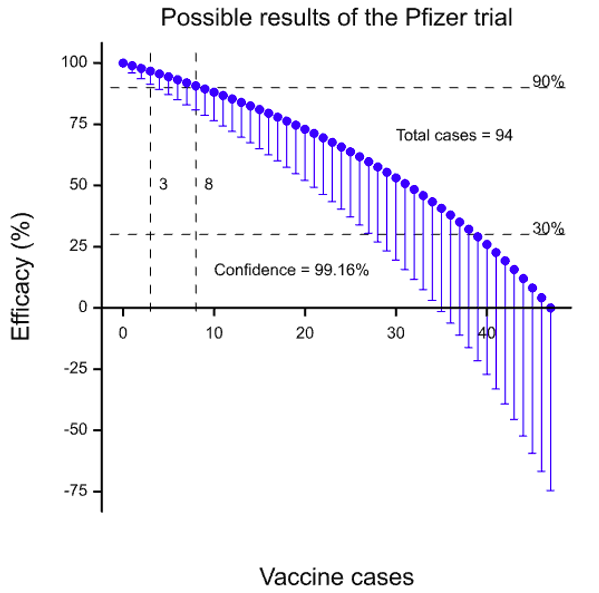
The solid blue circles are the estimate of the vaccine efficacy. The ‘whiskers’ below indicate a confidence limit of 99.16% which (I think) is the level appropriate for the third look in an O’Brien-Fleming scheme for an overall type I error rate of 5%. Horizontal lines have been drawn at 30% efficacy (the value used in the protocol for the null hypothesis) and 90% efficacy (the claimed effect in the press release). Three cases on the vaccine arm would give a vaccine efficacy at about 91.3% for the lower confidence interval whereas four gives a value of 89.2%. Eight cases would give a point estimate of 90.7%. So depending on what exactly the claim of “more than 90% effective” might mean (and a whole host of other assumptions) we could argue that between three and eight cases of infection were seen.
Safety second
Of course safety is often described as being first in terms of priorities but it usually takes longer to see the results that are necessary to judge it than to see those for efficacy. According to BusinessWire “Pfizer and BioNTech are continuing to accumulate safety data and currently estimate that a median of two months of safety data following the second (and final) dose of the vaccine candidate – the amount of safety data specified by the FDA in its guidance for potential Emergency Use Authorization – will be available by the third week of November.”
The world awaits the results with interest.
A Dec. 2, 2020 update by Senn
https://www.linkedin.com/pulse/needlework-guesswork-stephen-senn/
Reference
- C. O’Brien and T. R. Fleming (1979) A multiple testing procedure for clinical trials. Biometrics, 549-556.


")


Stephen:
I’m so grateful for the guest post that provides so much clarity and illumination to the recent Covid-19 vaccine trials! We’re very lucky to have this. I’m glad to see that this illustrates a one-sided null hypothesis other than zero, with the doubling of the P-value for selection. That is how Cox and Hinkley (1974) recommend tests be done whenever one plans to report the direction observed. Thank you so much for venturing (in your POSTSCRIPT) to unravel the mystery behind the recent Pfizer vaccine numbers. This is a wonderful help! Aris Spanos and I were recently pondering the VERY question you raise as to what exactly the 90% refers to (observed value, CI bound, efficacy?), and with your discussion of the possibilities, it’s immensely clearer. (Did they also test for 30% efficacy? Or is that unknown?) I will study this more carefully.
This is a very interesting article. I don’t recall ever seeing graphs with the contour plots like you’ve created for this, and I’ll definitely be taking more time to study them so I can better understand.
The graph of the possible results of the Pfizer trial is excellent. It’s a clever way of communicating the results in a simple manner. Well, perhaps it does not seem all that clever to an expert such as yourself, but I think it is.
on p. 98 they describe the hypotheses
Click to access C4591001_Clinical_Protocol_Nov2020.pdf
Thank you Stephen Senn for another clearheaded discussion of medical tests.
From the Pfizer study protocol
“VE=100 × (1 –IRR) will be estimated with confirmed COVID-19 illness according to the CDC-defined symptoms after 7 days after the last dose. The 2-sided 95% CI for VE will be derived using the Clopper-Pearson method as described by Agresti. [Ref 9] ” (p. 100)
I took a more rudimentary approach to teasing out the distribution of the 94 COVID-19 cases across the two treatment arms:
R: 1-7/(94-7)
[1] 0.9195402
R: 1-8/(94-8)
[1] 0.9069767
R: 1-9/(94-9)
[1] 0.8941176
which suggests 8 cases in the vaccinated group versus 86 in the control group, allowing Pfizer to claim a vaccine efficacy rate “over 90%”. Given Senn’s elegant analysis, or the rudimentary one outlined above, readily available, I wonder why the interim analysis group was so coy about discussing the COVID-19 case distribution.
If I could choose between group A where 8 out of 20,000 people contract COVID-19 versus group B where 86 out of 20,000 people contract COVID-19, I will eagerly choose group A if I am allowed, no doubt the group that received the vaccine, though I really should present a severity assessment to back up my enthusiasm.
Being very wary of business-wire corporate announcements, I will wait for independent and regulatory agency assessments of the trial findings. A New York Times article states
“Pfizer, which developed the vaccine with the German drugmaker BioNTech, released only sparse details from its clinical trial, based on the first formal review of the data by an outside panel of experts.”
which suggests that an independent group has reviewed the data. Encouraging news indeed.
The study protocol suggests that “The assessment for the primary analysis will be based on posterior probability using a Bayesian model.” I look forward to seeing this Bayesian analysis. Everything I see so far appears to be frequentist analysis thankfully, where error rates can be readily assessed. Given the claim that a Bayesian model will be the primary assessment model, how does one generate the power analysis they describe? I see nothing Bayesian about a Clopper-Pearson method analysis, first described in 1934, well before the appearance of Bayesian analyses available today. I find it fascinating that some analysts go on and on touting Bayesian models but then present a bunch of error-rate checkable frequentist model findings.
The business wire report states about 39,000 individuals have been vaccinated with a median follow-up of 2 months.
With a 1.3% per year incidence rate we’d expect to see about 43 cases in two months from 39000/2 placebo control individuals, yet the report suggests about 86 cases, double that assumed at the study outset.
One of the study criteria is
“Participants who, in the judgment of the investigator, are at risk for acquiring COVID-19.”
Given the higher apparent observed incidence rate suggested by the press release the investigators have identified participants at more than sufficient risk of acquiring COVID-19, which will allow a more rapid assessment for this vaccine.
Steven: It’s my understanding that Bayesian trials are still required to show control of type I error probabilities & satisfy other error statistical criteria. The uninformative prior is mentioned on p. 111 of the report in my earlier comment.

On p. 99, they note.
There’s some discussion on the Bayesian prior by an individual writing a post for Gelman’s blog here https://statmodeling.stat.columbia.edu/2020/11/13/pfizer-beta-prior-vaccine-effect/.
Looking over the report, and then also reading the referenced blog post on the prior, I cannot believe anyone serious believes that Bayesian analyses make it easier for people to understand the results. Thankfully, they also include frequency statistical interpretations in the report.
Now comes Moderna with a 30,000-ish trial interim peek showing 95 COVID-19 infections two weeks after the second injection, 5 in the vaccine arm, for a VE of “94.5%”
R: 1-5/(95-5)
[1] 0.9444444
but whose nitpicking about rounding up a tad. The ClinicalTrials.gov NCT04470427 page says the recruitment status is ‘Active, not recruiting’ which is explained as “The study is ongoing, and participants are receiving an intervention or being examined, but potential participants are not currently being recruited or enrolled.” The Moderna website says “Enrollment Complete 30,000 participants enrolled in the COVE Phase 3 Study as of Thursday, October 22, 2020. 25,654 participants have received their second vaccination.” so this study has about 15,000 fewer trial subjects than the Pfizer study at this first peek. Of course we need to know how many of those 25,654 participants have more than two weeks of follow-up after their second injection.
Moderna’s vaccine seems more stable under higher temperatures than the Pfizer vaccine.
Pfizer counts COVID-19 cases one week after the second shot, Moderna two weeks. I certainly do want to know how many COVID-19 infections happened before these cutoff periods. Survival analysis starting from date of enrolment with COVID-19 onset as the event of interest would be most illuminating in all this.
I would be most interested to see Stephen Senn’s efficacy graphic for the Moderna trial. With a lower number of cases, variability must be larger than seen in the Pfizer trial.
Steven: Thank you so much for weighing in on this brand new case. I hope we can illuminate all of this on Thursday, even though it will be much more general on randomization (I’m not sure).
Pfizer’s interim analysis done in Nov 2020 shows that there were 4 confirmed COVID-19 cases in the vaccine group and 90 confirmed COVID-19 cases in the placebo group. The results of the Bayesian inference are :
“VE of BNT162b2 was 95.5% with a 99.99% posterior probability for the true VE being >30% conditioning on available data, to overwhelmingly meet the prespecified interim analysis success criterion (>99.5%). The 95% credible interval for the VE was 88.8% to 98.4%, indicating that given these observed data there was a 95% probability that the true VE lies in this interval”.
Reference: https://www.fda.gov/media/144246/download#page=54
KSLam: How do you interpret that posterior probability?
I tend to interpret the posterior probability with respect to the null hypothesis. Bayes’ rule allows us to calculate this posterior probability of the null hypothesis be it true or false. Pfizer clearly shows us the above statement in the context of Bayesian approach.
Please read “The posterior probability of a null hypothesis given a statistically significant result”.
Click to access 1901.06889.pdf
The question is how to interpret that probability. Is it an agent’s degree of belief? A frequency? An assessment of the methods reliability? Or is it just a posterior computed from an undefined “default” prior?
The Bayesian treats probability as beliefs, not frequencies.
Pfizer used beta prior, beta(0.700102, 1). In Beta-Binomial distribution, the expected P (probability for events in vaccine group out of the total events) is 0.700102/(0.700102+1) = 0.4118 which is same as θ stated in Pfizer’s study protocol i.e “The prior is centered at θ = 0.4118 (VE=30%)”. You can use the formula (1-VE)/(2-VE) to work out θ i.e (1-0.3)/(2-0.3) =0.4118.
The parameter θ is given a prior distribution i.e 0.4118 which represents Pfizer’s subjective belief before any data is observed by doing the interim analysis. After observing the clinical cases i.e 4 COVID-19 cases in the vaccine group and 90 COVID-19 cases in the placebo group, the belief is updated to compute the posterior probability i.e P[VE >30%|data]).
The likelihood for P is binomial, so the posterior for P is also beta (0.700102+cases in vaccinated group, 1+cases in placebo group) due to conjugacy. Using the Excel function i.e BETA.DIST to compute the posterior probability.