

.
Stephen Senn
Consultant Statistician
Edinburgh, Scotland
Sepsis sceptic
During an exchange on Twitter, Lawrence Lynn drew my attention to a paper by Laffey and Kavanagh[1]. This makes an interesting, useful and very depressing assessment of the situation as regards clinical trials in critical care. The authors make various claims that RCTs in this field are not useful as currently conducted. I don’t agree with the authors’ logic here although, perhaps, surprisingly, I consider that their conclusion might be true. I propose to discuss this here.
Disclaimer
My ‘knowledge’ of critical care is non-existent. The closest I have come to being involved is membership of various data-safety monitoring boards for sepsis. This is not at all the same as having been involved in planning trials in sepsis let alone critical care more widely.
Your starter for 10
In my opinion, which the reader should check for themselves, the argument of Laffey and Kavanagh has the following steps.
- The proportion of positive trials in critical care is low. (One out of 20 large trials that concluded recently was positive.)
- Given that such large trials are preceded by extensive testing, the number of effective treatments being tested in these large trials ought to be at least 50%.
- “On a statistical basis, it is unlikely that most negative RCTs represent fair conclusions.” (p657).
- Some may say that this low success rate is due to patients numbers being too few.
- “But if the intervention is not matched to the patients being studied (eg, the biological target is absent) then the limitation is biological—not statistical—and insistence on greater numbers (or more stringent p-values) will have no effect.” (p657)
- The entry criteria for most trials rely on consensus definitions, which have high sensitivity, which is what you want for screening but do not have specificity, which is what you need for recruiting for clinical trials.
- Hence clinical trials include many patients the treatment could not reasonably be expected to help.
- This may cause a trial to be a ‘false negative’.
- Trials in which patients are screened based on mechanism will be more promising.
- Designers of RCTs and clinical trials groups should ensure that proposed RCTs in critical care identify subgroups of patients that match the specific intervention being tested.
Sum mistake
I can agree with a number of these points but some of them are vary debatable. For example no evidence is given for 3. Instead a confusing argument, based on the ‘one successful trial in 20’ statistic is produced as follows.
For example, if each hypothesis tested had the same a priori probability that was as low as a coin toss, we would expect 50% of RCTs to be positive. The likelihood that 19 out of 20 consecutive such coin tosses would be negative is less than 1 in half a million (1 ÷ 219). (P657)
This is wrong on several counts. First a minor point is that the probability should not be calculated this way. The probability they calculate applies to the case where 19 trials were run, all of which were failures. For 19 out of 20, we have to allow for the fact that there are 20 possible different selections of one trial from 20 and that we perhaps ought to include the more extreme case of 20 out of 20 anyway. The calculation should thus be (20+1) x ½19 x ½ = 21/220 ≈ 10/219. This probability is thus about 10 times higher than the one they calculated and therefore about 1 in 50,000. Still, even so, this is a low probability.
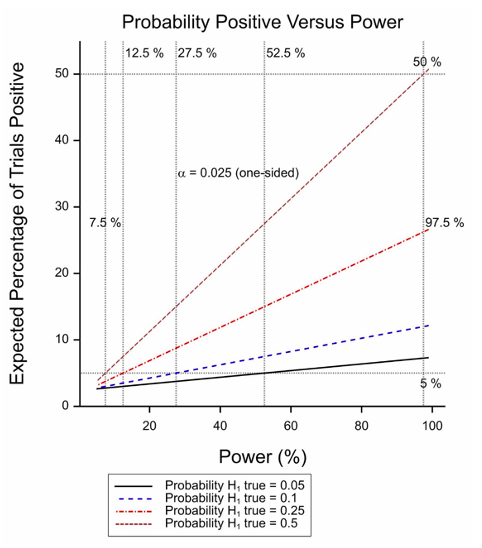
Figure 1 Expected percentage of positive trials as a function of power for various probabilities of the treatment being effective.
The second problem, however, is more serious and is that the calculation takes no account of the power involved. In fact, if half of all null hypotheses are false and the threshold for significance is 2.5% (one sided). Only trials with 97.5% power have a 50% chance of being positive (or an assurance of 50% to use the technical term proposed by O’Hagan, Stevens and Campbell[2]). The situation is illustrated in Figure 1 for various probabilities of the treatment being effective. A combination of a low probability and a moderate power will yield few significant trials.
The third problem, however is that the argument given in 2 and 7 is weak and inconsistent. It supposes that research in early stages of development can succeed in identifying treatments that we can be reasonably confident are effective for some patients but have no idea who they are.
Quite apart from anything else, the problem with this line of arguments is that the ‘responders’ have to be a small proportion of those included for the power to drop to the sort of level that could explain these results.
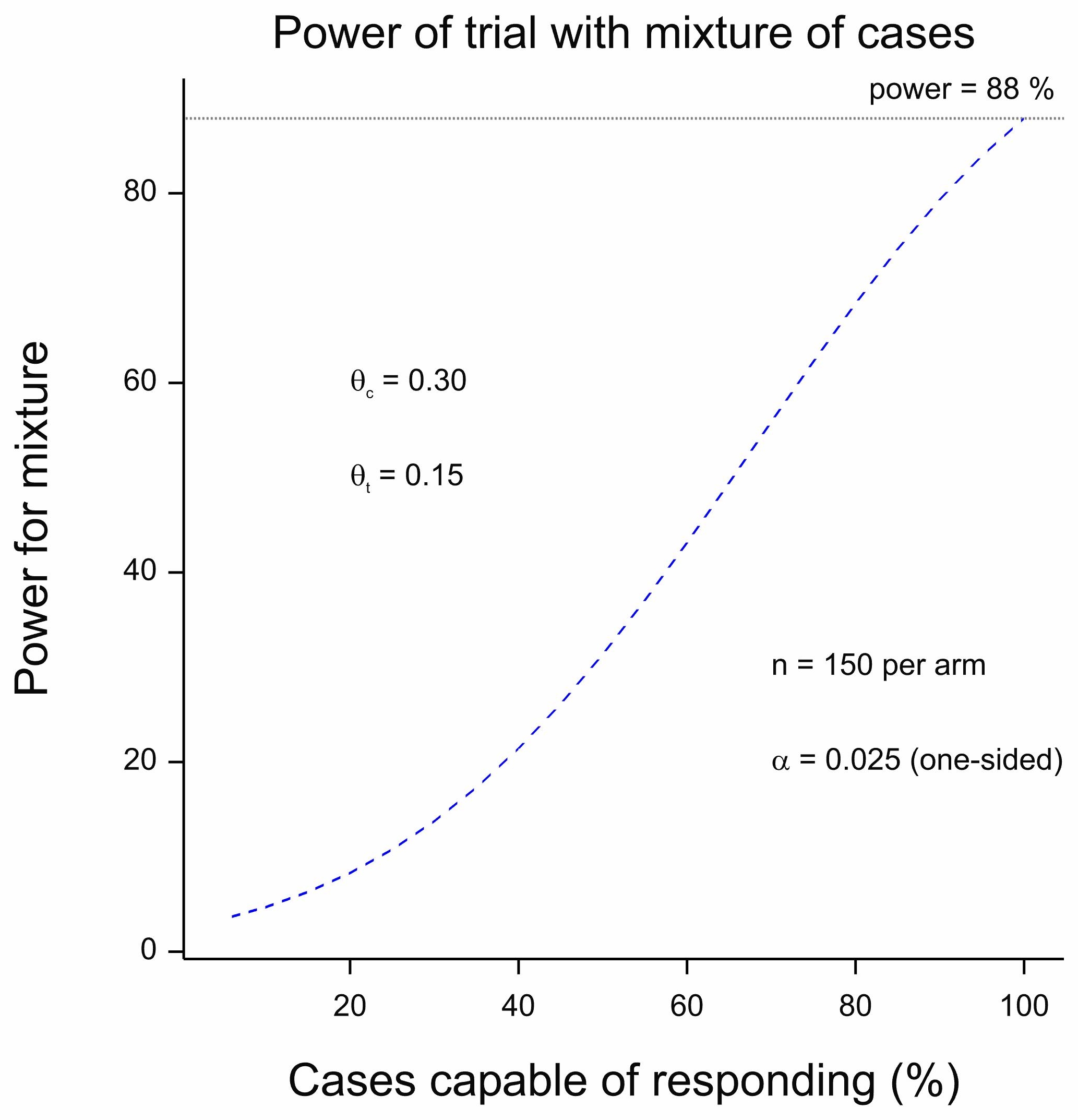
Figure 2 Power for a trial as a function of the proportion of cases capable of responding.
For Figure 2, I used the following. I took some figures from a recent published protocol for “Low-Molecular Weight Heparin dosages in hospitalized patients with severe COVID-19 pneumonia and coagulopathy not requiring invasive mechanical ventilation (COVID-19 HD)”[3]. It is not a particularly close match for the indication discussed here but the COVID theme makes it topical and it serves to make a statistical point. The response is binary (clinical worsening or not) and for power calculations rates of 30% and 15% are compared yielding power in excess of 80% for 150 patients per arm. (I calculate about 88%.) I then supposed that only a percentage of the patients could benefit, the rest having the response probability of the control group. (See chapter 14 of Statistical Issues in Drug Development for a discussion of this approach[4].)
The figure plots the power against the proportion of true responders recruited. When this is 100%, the power reaches 88%. However, even when only one in every two patients is capable of benefitting, the power is 38%. If we now turn to figure 1 we see that if half the treatment works well but in only half the patients (power of 38%), we still expect to see one in five trials being a ‘success’.
Of course, we can always postulate having even larger proportions of non-responders but at what point does it become ludicrous to claim one has a treatment: it works well when it works, only unfortunately there are almost no patients for whom it works?
Naught for your comfort
The sad truth seems to be that the data suggest that effective treatments are not being found in this field. In a sense I agree with the authors’ conclusions. Success will be a matter of finding the right treatments to treat the right patients. I have no quarrel with that. However, my personal hunch is that it will have more to do with finding good drugs than finding the perfect patients. Of course, doing the former may, indeed, require identifying good druggable targets. Nevertheless, when and if the right drugs are found for the right patients, convincing proof will come from a randomised clinical trial. Drug development is easy compared to drug research and I have always worked in the former. Nevertheless, sometimes the unwelcome but true message from development is that research is even harder than supposed.
References
- Laffey, J.G. and B.P. Kavanagh, Negative trials in critical care: why most research is probably wrong. Lancet Respir Med, 2018. 6(9): p. 659-660.
- O’Hagan, A., J.W. Stevens, and M.J. Campbell, Assurance in clinical trial design. Pharmaceutical Statistics, 2005. 4(3): p. 187-201.
- Marietta, M., et al., Randomised controlled trial comparing efficacy and safety of high versus low Low-Molecular Weight Heparin dosages in hospitalized patients with severe COVID-19 pneumonia and coagulopathy not requiring invasive mechanical ventilation (COVID-19 HD): a structured summary of a study protocol. Trials, 2020. 21(1): p. 574.
- Senn, S.J., Statistical Issues in Drug Development. Statistics in Practice. 2007, Hoboken: Wiley. 498.


")


Stephen: Thank you so much for this extremely interesting guest post. I wish I understood both their argument and your reply more clearly. I sense their point is essentially that given what’s known about how some of these interventions appear to help patients, we should be seeing a higher percentage of positive trials than we do; and you seem to be saying no, not really, if the computations are done correctly. Please put me straight if this is all wrong. And their argument for their position appears to be that false negatives in critical care result because the trials include many patients the treatment could not reasonably be expected to help, leading to high false negatives. A better way, they say, would be “Trials in which patients are screened based on mechanism …Designers of RCTs and clinical trials groups should ensure that proposed RCTs in critical care identify subgroups of patients that match the specific intervention being tested.” Knowing what you have said about randomisation, though, if there’s fairly good grounds for the operative ‘mechanism”, shouldn’t that already enter into the randomisation (following what you’ve said about relevant factors required to be in the model before randomizing)?
In figure 1, I don’t see how one gets 97.5% for the expected percentage positive with the prob(H1) = .25 and maximal power, when it’s only around .5 when prob(H1) = .5. (But this might be due to misreading this, due to extreme-fuzzy-headedness on my part.)
Nice blog. Continuing with the critical care theme, the UK Recovery trial did unearth dexamethasone and more recently Tocilizumab, so its success rate hasn’t been too bad. It killed off definitively some notable others Iike HCQ This is a very large platform trial, albeit open-label for practical reasons. But perhaps a more coordinated and systematic approach across institutions is the way forward in critical care. We need to see more patients viewing clinical trials as a treatment option and embed an experimental framework within healthcare more generally. Notably within the national vaccine roll out programs.
Thanks, Deborah. The message is rather that if we don’t have many positive reults in a field a natural explanation is that few treatments are effective or perhaps that many treatments are barely effective. So I take the cynical view that the solution is finding better treatments (which I freely admit is really hard) rather than assuming that the explanation of the high failure rate is that treatments are being examined badly (either by using inappropriate statistical methods or wrong entry criteria or some other fault of design).
My apologies regarding the confusion over calculations. The graphs were rather confusingly labelled. The 97.5% label applies to the vertical dashed line on the RHS. At that value of the power, if the proportion of effective treatments is 0.5 (this being the case for the steepest of the four lines), then the probablity of a positive result is the probability of a type I error plus the probability of a true positive. So we have (0.5 x 0.025) + (0.5 x 0.975) = 0.5(0.025+0.975)=0.5 x 1= 0.5. Hence the steepest line iinteresects the horizontal 50% line and the vertical 97.5% line where they intersct each other.
Stephen:
I see now that I went too fast in looking at the figure and mistook 97.5% for the expected percentage positive, which made no sense, so I assumed it was mislabeled. I see it now, even though I never like to treat power or alpha as conditional probabilities. I understand your message to locate the problem in there being too few effective treatments, but I thought you would also propose a more appropriate randomisation. Thanks again for your excellent guest post.
The point of view expressed in the Laffey and Kavanagh article seems to me to be blaming bad workmanship on the tool rather than on the way the tool was used. It is part of a mindset that more readily affects certain subsets of the medical profession such as surgeons and intensivists. These specialities attract people who are interventionist – they like to DO things. If these specialists spend their careers performing medical interventions, often without good evidential support, then it is not surprising that they are unreasonably optimistic about how beneficial their interventions are – a version of Festinger’s cognitive dissonance. Over the years I have heard many intensivists say that a particular intensive care therapy does not need to be trialled because they KNOW that it works. A salutary example comes in the form of the story of the Swan-Ganz catheter. This was a large catheter with a balloon and several pressure transducers that could be inserted into the right side of the heart allowing the measurement of a large number of physiologic variables such as the cardiac output and venous resistance. It was used extensively in ICU in the 80s and at one time, more than 50% of all ICU patients in the US had one inserted. The problem was that there was no good evidence that these measurements that these improved the outcome for patients. Most intensivists however were sure that they worked as evidenced by their widespread use. Eventually, and somewhat controversially (“We know it works, a trial would be unethical”), an RCT was performed which showed that rather than being beneficial, insertion of a Swan-Ganz catheter worsened patient outcomes and these days they are no longer used.
The same pattern has been repeated over and over again in the last 30 years. The most recent example is the use of vitamin C in sepsis which was touted as a miracle cure and widely used based on weak observational evidence and then debunked based on several RCTs.
I don’t mean to demean these doctors who clearly save many lives but I do wish they had a bit more skepticism concerning novel therapies.