
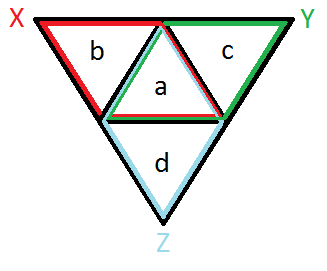
Alexandre’s example, by Corey
Before leaving the “irrelevant conjunct” business of the last post, I am setting out that Popper example for future reference, so we don’t have to wade through 50+ comments, if we want to come back to it. Alexandre converted the example to more familiar set theory language, and Corey made a nice picture. Thanks! I now think I’ve gotten to the bottom of the issue*.
Popper (on probability vs confirmation as a B-boost):
“Consider now the conjecture that there are three statements, h, h’, z, such that (i) h and h’ are independent of z (or undermined by z) while (ii) z supports their conjunction hh’. Obviously we should have to say in such a case that z confirms hh’ to a higher degree than it confirms either h or h’; in symbols,
(4.1) C(h,z) < C(hh’, z) > C(h’, z)
But this would be incompatible with the view that C(h,z) is a probability, i.e., with
(4.2) C(h,z) = P(h|z)
Since for probabilities we have the generally valid formula
(4.3) P(h|z) > P(hh’|z) < P(h’|z)…..” (Popper, LSD, 396-7)
“Take coloured counters, called ‘a’,’b’,…, with four exclusive and equally probable properties, blue, green, red, and yellow.
h: ‘b is blue or green’;
h’: ‘b is blue or red’
z: ‘b is blue or yellow’.
Then all our conditions are satisfied. h and h’ are independent of z. (That z supports hh’ is obvious: z follows from hh’, and its presence raises the probability of hh’ to twice the value it has in the absence of z.” (LSD 398) (The conjunction of h and h’ yields ‘b is blue’.)[i]
Let me provide a simple example in terms of sets, hopefully this can to make your point clear:
Let O = {a,b,c,d} be the universe set endowed with a probability measure P such that:
P({a}) = P({b})=P({c}) = P({d}) = 1/4.
Alexandre’s example, by Corey
Define the subsets X = {a,b}; Y = {a,c} and Z = {a,d}. Hence, we have:
P(X) = P(Y) = P(Z) = 1/2
and
P(X /\ Y) = P(X /\ Z) = P(Y /\ Z) = P({a}) = 1/4,
where the symbol /\ stands for the intersection. Then, the conditional probabilities are
P(X|Z) = P(X /\ Z)/P(Z) = 1/2 = P(X),
P(Y|Z) = P(Y /\ Z)/P(Z) = 1/2 = P(Y)
and
P(X /\ Y |Z) = P(X /\ Y /\ Z)/P(Z) = P({a})/ P(Z) = 1/2.
It means that X and Y are both independent of Z, but (X /\ Y) is not.
Assume that: C(w,q) = P(w|q)/P(w) is our confirmation measure, then
C(X,Z) = 1, that is, Z does not support X
C(Y,Z) = 1, that is, Z does not support Y
C(X /\ Y,X) = 2, that is, Z does support X /\ Y
In Deborah Mayo’s words:
C(X,Z) is less than C(X /\ Y, Z) that is greater than C(Y, Z).
*Once I write it up I’ll share it. I am grateful for insights arising from the last discussion. I will post at least one related point over the weekend.
(Continued discussion should go here I think, the other post is too crowded.)
[i]From Note (2) of previous past:
[2] Can P = C? 9i.e., can “confirmation” defined as a B-boost, equal probability P?)
Spoze there’s a case where z confirms hh’ more than z confirms h’: C(hh’,z) > C(h’,z)
Now h’ = (~hh’ or hh’)
So,
(i) C(hh’,z) > C(~hh’ or hh’,z)
Since ~hh’ and hh’ are mutually exclusive, we have from special addition rule
(ii) P(hh’,z) < P(~hh’ or hh’,z)
So if P = C, (i) and (ii) yield a contradiction.


")


Well, I guess no one has anything new to say, but I had one point of confusion in need of clarification and one query in the last thread that may have been lost in the shuffle. (They’re both in this comment.
Corey: There’s nothing more effective at quieting things down than starting a new post to make space after >50 comments.
Here at the Elbar room (with fairly reliable internet for once), there’s a big celebration of one of Napolean’s battles, to be featured in Napoleanland (not sure if he won or lost, I think lost)–yes they’re going ahead with the theme park. Elba grease is flowing freely–you’ve got to get a life Corey!
Oh, boy. Someone got into the Manischewitz, I see.
Corey: That undrinkable wine is for Passover (but you spelled it correctly). Here it’s all Napolean and Mt. Etna excitement.
Do you know if it’s possible to have the numbers associated with comments show up? Normal Deviate seems to have his numbered.
“That undrinkable wine is for Passover (but you spelled it correctly).”
Indeed; only the real shikkers resort to Manischewitz…
(Actually I once met a shopkeeper in Barbados — an emigrant from India — whose tipple of choice was Manischewitz.)
On comment-numbering: it must be possible, but I don’t know how to get it to happen. It might have something to do with the theme of the blog.
To me, the problem with the above example is that it classifies the student’s readiness as binary rather than continuous. I’d rather just do inference on the student’s readiness than frame in terms of discrete hypotheses. Arguably, one of the biggest problems of the hypothesis testing framework is the way it has encouraged so many statisticians and users of statistics (Bayesian and non-Bayesian alike) to frame their problems in terms of discrete hypotheses. I think it’s much better in this sort of setting to have a continuous model. Then if at the end you want to make a discrete decision, you can do so.
Andrew: Thanks! i totally agree, but every single one of the examples of this nature–sometimes put forward and demonstrating the “unsoundness” of error statistics–depends on this “on-off” construal. For instance, the most common example (in both Howson articles in the references) are diseases, where purely false positive/false negatives are allowed. It is taken as the consequence of ignoring “base rates”. You can check my replies to them, both short. Of course, there’s nothing preventing the frequentist from their computations, the problem is mixing two distinct appraisals in the same problem.
I know you meant your comment to go in the most current post, not this one.
Corey, Deborah and others,
My opinion:
There is not a unique way of defining “support”, “confirmation”, “endorsement”, “certification”, “information” and so on. Each definition has its own particularities and interpretations. In some cases, the entailment condition is appropriated, in other cases it is not. As any other problem: in the core, it is a language problem.
Typically, people believe in the rational process of thinking but forget the underling values behind the resulting arguments. Behind each conjunction like “therefore” there is a vast field of unspoken values being regarded as unquestionable truths (which are not unquestionable at all). Unfortunately, this dogmatic rational behaviour is quite actual and seems to dominate the modern scientists/statisticians/mathematicians. Maybe a little bit of Nietzsche’s thoughts would be a good medicine for them.
Why not have many different measures of support, each one with its own interpretation and application?
Since any measure is a projection from the qualitative to a quantitative space, a unique measure will always be deficient in at least one aspect of the problem. Even for deriving the general rules of the inferential processes — should they respect the probability rules, possibility ones or other different rules? –, different types of desiderata should be employed and from them many types of inferential rules derived. The entailment condition for deriving those rules may be appropriated when we desire some sort of interpretations, but it is not always the case.
In my paper (1), I proposed an alternative measure of evidence that satisfies the entailment condition. I suggested this measure as an additional summary, but not as a replacement of the p-value. In the paper’s words: “Based on its [the s-value] properties, we strongly recommend this measure as an additional summary of significance tests”
We have to keep in mind the following: when there is a rational justification that some thing *can* be done, it does not mean that this thing *should* be done. Professor Lindley forgot this when he wrote:
*/The only satisfactory description of uncertainty is probability.
By this I mean that every uncertainty statement must be in the form of a probability; that several uncertainties must be combined using the rules of probability; and that the calculus of probabilities is adequate to handle all situations involving uncertainty…probability is the only sensible description of uncertainty and is adequate for all problems involving uncertainty. All other methods are inadequate…anything that can be done with fuzzy logic, belief functions, upper and lower probabilities, or any other alternative to probability can better be done with probability (Lindley 1987)./*
Of course that probability is NOT the unique sensible description of uncertainty. It can be used to describe uncertainty, but it is not the unique sensible way of doing this. It is quite discouraging having to deal with so dogmatic views in our statistical community.
By studying the Cox axioms (revised by Paris) one can easily see that some assumptions are not always valid for all types of uncertainties. Any other justifications of probability (Dutch book arguments, Scoring rules and so on) aways regarded (ex)implicitly a linear restriction in the problem that is intrinsically related to the sum rule.
(1) A classical measure of evidence for general null hypotheses: http://www.sciencedirect.com/science/article/pii/S0165011413001255
Pingback: Notes (from Feb 6) on the irrelevant conjunction problem for Bayesian epistemologists (i) | Rejected Posts of D. Mayo