
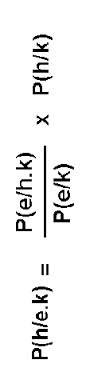 *addition of note [2].
*addition of note [2].
A long-running research program in philosophy is to seek a quantitative measure
C(h,x)
to capture intuitive ideas about “confirmation” and about “confirmational relevance”. The components of C(h,x) are allowed to be any statements, no reference to a probability model or to joint distributions are required. Then h is “confirmed” or supported by x if P(h|x) > P(h), disconfirmed (or undermined) if P(h|x) < P(h), (else x is confirmationally irrelevant to h). This is the generally accepted view of philosophers of confirmation (or Bayesian formal epistemologists) up to the present. There is generally a background “k” included, but to avoid a blinding mass of symbols I omit it. (We are rarely told how to get the probabilities anyway; but I’m going to leave that to one side, as it will not really matter here.)
A test of any purported philosophical confirmation theory is whether it elucidates or is even in sync with intuitive methodological principles about evidence or testing. One of the first problems that arises stems from asking…
Is Probability a good measure of confirmation?
A natural move then would be to identify the degree of confirmation of h by x with probability P(h|x), (which philosophers sometimes write as P(h,x)). Statement x affords hypothesis h higher confirmation than it does h’ iff P(h|x) > P(h’|x).
Some puzzles immediately arise. Hypothesis h can be confirmed by x, while h’ disconfirmed by x, and yet P(h|x) < P(h’|x). In other words, we can have P(h|x) > P(h) and P(h’|x) < P(h’) and yet P(h|x) < P(h’|x).
Popper (The Logic of Scientific Discovery, 1959, 390) gives this example, (I quote from him, only changing symbols slightly):
Consider the next toss with a homogeneous die.
h: 6 will turn up
h’: 6 will not turn up
x: an even number will turn up.
P(h) = 1/6, p(h’) = 5/6 P(x) = ½
The probability of h is raised by information x, while h’ is undermined by x. (It’s probability goes from 5/6 to 4/6.) If we identify probability with degree of confirmation, x confirms h and disconfirms h’ (i.e., P(h|x) >P(h) and P(h’|x) < P(h’)). Yet because P(h|x) < P(h’|x), h is less well confirmed given x than is h’. (This happens because P(h) is sufficiently low.) So P(h|x) cannot just be identified with the degree of confirmation that x affords h.
Note, these are not real statistical hypotheses but statements of events.
Obviously there needs to be a way to distinguish between some absolute confirmation for h, and a relative measure of how much it has increased due to x. From the start, Rudolf Carnap noted that “the verb ‘to confirm’ is ambiguous” but thought it had “the connotation of ‘making firmer’ even more often than that of ‘making firm’.” (Carnap, Logical Foundations of Probability (2nd), xviii ). x can increase the firmness of h, but C(h,x) < C(~h,x) (h is more firm, given x, than is ~h). Like Carnap, it’s the ‘making firmer’ that is generally assumed in Bayesian confirmation theory.
But there are many different measures of making firmer (Popper, Carnap, Fitelson). Referring to Popper’s example, we can report the ratio R: P(h|x)/P(h) = 2.
(In this case h’ = ~h).
Or we use the likelihood ratio LR: P(x|h)/P(x|~h) = (1/.4) = 2.5.
Many other ways of measuring the increase in confirmation x affords h could do as well. But what shall we say about the numbers like 2, 2.5? Do they mean the same thing in different contexts? What happens if we get beyond toy examples to scientific hypotheses where ~h would allude to all possible theories not yet thought of. What’s P(x|~h) where ~h is “the catchall” hypothesis asserting “something else”? (see, for example, Mayo 1997)
Perhaps this point won’t prevent confirmation logics from accomplishing the role of capturing and justifying intuitions about confirmation. So let’s consider the value of confirmation theories to that role. One of the early leaders of philosophical Bayesian confirmation, Peter Achinstein (2001), began to have doubts about the value of the philosopher’s a priori project. He even claims, rather provocatively, that “scientists do not and should not take … philosophical accounts of evidence seriously” (p. 9) because they give us formal syntactical (context –free) measures; whereas, scientists look to empirical grounds for confirmation. Philosophical accounts, moreover, make it too easy to confirm. He rejects confirmation as increased firmness, denying it is either necessary or sufficient for evidence. As far as making it too easy to get confirmation, there is the classic problem: it appears we can get everything to confirm everything, so long as one thing is confirmed. This is a famous argument due to Glymour (1980).
Paradox of irrelevant conjunctions
We now switch to emphasizing that the hypotheses may be statistical hypotheses or substantive theories. Both for this reason and because I think they look better, I move away from Popper and Carnap’s lower case letters for hypotheses.
The problem of irrelevant conjunctions (the “tacking paradox”) is this: If x confirms H, then x also confirms (H & J), even if hypothesis J is just “tacked on” to H. As with most of these chestnuts, there is a long history (e.g., Earman 1992, Rosenkrantz 1977), but consider just a leading contemporary representative, Branden Fitelson. Fitelson has importantly emphasized how many different C functions there are for capturing “makes firm”. Fitelson defines:
J is an irrelevant conjunct to H, with respect to x just in case P(x|H) = P(x|J & H).
For instance, x might be radioastronomic data in support of:
H: the deflection of light effect (due to gravity) is as stipulated in the General Theory of Relativity (GTR), 1.75” at the limb of the sun.
and the irrelevant conjunct:
J: the radioactivity of the Fukushima water being dumped in the Pacific ocean is within acceptable levels.
(1) Bayesian (Confirmation) Conjunction: If x Bayesian confirms H, then x Bayesian-confirms (H & J), where P(x| H & J ) = P(x|H) for any J consistent with H.
The reasoning is as follows:
P(x|H) /P(x) > 1 (x Bayesian confirms H)
P(x|H & J) = P(x|H) (given)
So [P(x|H & J) /P(x)]> 1
Therefore x Bayesian confirms (H & J)
However, it is also plausible to hold :
(2) Entailment condition: If x confirms T, and T entails J, then x confirms J.
In particular, if x confirms (H & J), then x confirms J.
(3) From (1) and (2) , if x confirms H, then x confirms J for any irrelevant J consistent with H.
(Assume neither H nor J have probabilities 0 or 1).
It follows that if x confirms any H, then x confirms any J.
Branden Fitelson’s solution
Fitelson (2002), and Fitelson and Hawthorne (2004) offer this “solution”: He will allow that x confirms (H & J), but deny the entailment condition. So, in particular, x confirms the conjunction although x does not confirm the irrelevant conjunct. Moreover, Fitelson shows, even though (H & J) is confirmed by x, (H & J) gets less of a confirmation (firmness) boost than does H—so long as one doesn’t measure the confirmation boost using R: P(h|x)/P(x). If one does use R, then (H & J) is just as well confirmed as is H, which is disturbing.
But even if we use the LR as our firmness boost, I would agree with Glymour that the solution scarcely solves the real problem. Paraphrasing him, we would not be assured by an account that tells us deflection of light data (x) confirms both GTR (H) and the radioactivity of the Fukushima water is within acceptable levels (J), while assuring us that x does not confirm the Fukishima water having acceptable levels of radiation (31).
The tacking paradox is to be expected if confirmation is taken as a variation on probabilistic affirming the consequent. Hypothetico-deductivists had the same problem, which is why Popper said we need to supplement each of the measures of confirmation boost with the condition of “severity”. However, he was unable to characterize severity adequately, and ultimately denied it could be formalized. He left it as an intuitive requirement that before applying any C-function, the confirming evidence must be the result of “a sincere (and ingenious) attempt to falsify the hypothesis” in question. I try to supply a more adequate account of severity (e.g., Mayo 1996, 2/3/12 post (no-pain philosophy III)).
How would the tacking method fare on the severity account? We’re not given the details we’d want for an error statistical appraisal, but let’s do the best with their stipulations. From our necessary condition, we have that (H and J) cannot warrant taking x as evidence for (H and J) if x counts as a highly insevere test of (H and J). The “test process” with tacking is something like this: having confirmed H, tack on any consistent but irrelevant J to obtain (H & J).(Sentence was amended on 10/21/13)
A scrutiny of well-testedness may proceed by denying either condition for severity. To follow the confirmation theorists, let’s grant the fit requirement (since H fits or entails x). This does not constitute having done anything to detect the falsity of H& J. The conjunction has been subjected to a radically non-risky test. (See also 1/2/13 post, esp. 5.3.4 Tacking Paradox Scotched.)
What they call confirmation we call mere “fit”
In fact, all their measures of confirmation C, be it the ratio measure R: P(H|x)/P(H) or the (so-called[1]) likelihood ratio LR: P(H|x)/P(~H|x), or one of the others, count merely as “fit” or “accordance” measures to the error statistician. There is no problem allowing each to be relevant for different problems and different dimensions of evidence. What we need to add in each case are the associated error probabilities:
P([H & J] is Bayesian confirmed; ~(J&H)) = maximal, so x is “bad evidence, no test” (BENT) for the conjunction.
We read “;” as “under the assumption that”.
In fact, all their measures of confirmation C are mere “fit” measures, be it the ratio measure R: P(H|x)/P(H) or the LR or other.
The following was added on 10-21-13: The above probability stems from taking the “fit measure” as a statistic, and assessing error probabilities by taking account the test process, as in error statistics. The result is
SEV[(H & J), tacking test, x] is minimal
I have still further problems with these inductive logic paradigms: an adequate philosophical account should answer questions and explicate principles about the methodology of scientific inference. Yet the Bayesian inductivist starts out assuming the intuition or principle, the task then being the homework problem of assigning priors and likelihoods that mesh with the principles. This often demands beating a Bayesian analysis into line, while still not getting at its genuine rationale. “The idea of putting probabilities over hypotheses delivered to philosophy a godsend, and an entire package of superficiality.” (Glymour 2010, 334). Perhaps philosophers are moving away from analytic reconstructions. Enough tears have been shed. But does an analogous problem crop up in Bayesian logic more generally?
I may update this post, and if I do I will alter the number following the title.
Oct. 20, 2013: I am updating this to reflect corrections pointed out by James Hawthorne, for which I’m very grateful. I will call this draft (ii).
Oct. 21, 2013 (updated in blue). I think another sentence might have accidentally got moved around.
Oct. 23, 2013. Given some issues that cropped up in the discussion (and the fact that certain symbols didn’t always come out right in the comments, I’m placing the point below in Note [2]):
[1] I say “so-called” because there’s no requirement of a proper statistical model here.
[2] Can P = C?
Spoze there’s a case where z confirms hh’ more than z confirms h’: C(hh’,z) > C(h’,z)
Now h’ = (~hh’ or hh’)
So,
(i) C(hh’,z) > C(~hh’ or hh’,z)
Since ~hh’ and hh’ are mutually exclusive, we have from special addition rule
(ii) P(hh’,z) < P(~hh’ or hh’,z)
So if P = C, (i) and (ii) yield a contradiction.
REFERENCES
Achinstein, P. (2001). The Book of Evidence. Oxford: Oxford University Press.
Carnap, R. (1962). Logical Foundations of Probability. Chicago: University of Chicago Press.
Earman, J. (1992). Bayes or Bust? A Critical Examination of Bayesian Confirmation Theory Cambridge MA: MIT Press.
Fitelson, B. (2002). Putting the Irrelevance Back Into the Problem of Irrelevant Conjunction. Philosophy of Science 69(4), 611–622.
Fitelson, B. & Hawthorne, J. (2004). Re-Solving Irrelevant Conjunction with Probabilistic Independence, Philosophy of Science, 71: 505–514.
Glymour, C. (1980) . Theory and Evidence. Princeton: Princeton University Press
_____. (2010). Explanation and Truth. In D. G. Mayo & A. Spanos (Eds.), Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability, and the Objectivity and Rationality of Science, 305–314. Cambridge: Cambridge University Press.
Mayo, D. (1996). Error and the Growth of Experimental Knowledge. Chicago: University of Chicago Press.
_____. (1997). “Duhem’s Problem, The Bayesian Way, and Error Statistics, or ‘What’s Belief got To Do With It?‘” and “Response to Howson and Laudan,” Philosophy of Science 64(1): 222-244 and 323-333.
_____. (2010). Explanation and Testing Exchanges with Clark Glymour. In D. G. Mayo & A. Spanos (Eds.), Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability, and the Objectivity and Rationality of Science, 305–314. Cambridge: Cambridge University Press.
Popper, K. (1959). The Logic of Scientific Discovery. New York: Basic Books.
Rosenkranz, R. (1977). Inference, Method and Decision: Towards a Bayesian Philosophy of Science. Dordrecht, The Netherlands: D. Reidel.


")


I am reminded that this discussion (of conjunctions) arose in the context of Bayesian statistics in the comments to the following post:
There is an article by V. Crupi, and K. Tentori [2010] that describe a greater paradox wherein Bayesian disconfirmations are conveniently ameliorated by tacking.
Click to access crupi_tentori2010.pdf
Visitor: Their paper is very illuminating, and I highly recommend people read it, but I don’t see how it helps with the current problem, as the same problem arises on their preferred confirmation measure.
There are many problems associated with these confirmation theories that are worth discussing, and I’m trying to keep the discussion manageable: one cluster is from the error statistical perspective (e.g., severity violations), the second, from the Bayesian perspective. I focus just on the latter for now.
So here are a couple of general puzzles: Bayesian inductive accounts originate with the idea that probability logic is the logic for inductive inference. Give me the posterior probability of H given x and I’ve got my assessment of support, confirmation, degree of belief or the like. That’s what we really want to know. But the philosophical confirmation logics immediately toss off the posterior probability, and turn to defining a large number of different C-functions that yield numbers like 2, 2.2, -1 and these aren’t posterior probabilities or degrees of belief. That’s my first point.
My second point is that, in dealing with this problem, confirmation accounts are eager or at least willing to toss off the entailment condition (2). Yet we also hear from Bayesians, e.g., Mark Schervish: that
A measure of support for hypotheses is coherent if, whenever H implies H’, the measure of support for H’ is at least as large as the measure of support for H. (1996, 204)
Click to access schervish-pvalues.pdf
Yet (H & J) entails J.
“Paraphrasing [Glymour (31)], we would not be assured by an account that tells us deflection of light data (x) confirms both GTR (H) and the radioactivity of the Fukushima water is within acceptable levels (J), while assuring us that x does not confirm the Fukishima water having acceptable levels of radiation.
Well, “it’s the ‘making firmer’ that is generally assumed in Bayesian confirmation theory,” so let’s swap it in. Also, those claims are so boring – they don’t involve *me* at all! Let’s swap them out too:
‘we would (not?) be assured by an account that tells us *this very comment you are reading now* (x) makes the claim “certainly Corey is a witty fellow, but he really ought to trim his fingernails” (H&J) firmer, while assuring us that x does not make the claim “Corey really ought to trim his fingernails” (J) firmer.’
I think we agree that x is irrelevant to J, and I do hope you’ll think x makes H&J firmer, albeit entirely through its confirmation of H.
Corey: I’m not sure how to understand your remarks.
“Well, “it’s the ‘making firmer’ that is generally assumed in Bayesian confirmation theory,” so let’s swap it in.”
So does this mean you reject the ‘making firmer” concept? Will you just use the posterior to measure confirmation? But in the next part you are back to defending making firmer.
“Also, those claims are so boring – they don’t involve *me* at all! Let’s swap them out too”.
Sorry if you consider GTR and the radioactivity of the Fukushima water so boring to you personally. Corey’s wit and fingernails are ever so much more important to science. Wrt that example, two points: (1) the existence of examples where we might agree to there being evidence for the conjunction does not address the most egregious cases permitted, and (2) this isn’t one such example since the comment I’m reading x seems to supply evidence for neither conjunct. But if I replaced the first conjunct with “Corey writes comments on blogs” or something like that, I’d still deny that the conjunction was probed by x, since nothing has been done to check into his nails.
Aside from these points, if we were talking about a severity assessment, the manner in which the conjunction with the irrelevant conjunct was chosen/created for testing would also be relevant.
By “swapping in”, I mean that I’m replacing the term “confirms [CLAIM]” with “makes [CLAIM] firmer”. The object is to avoid giving the impression that I’m talking about “confirm” in the sense of “makes (completely) firm”.
“Corey’s wit and fingernails are ever so much more important –”
Exactly!
“– to science.”
Oh fine, be like that. 😉
“…the comment I’m reading x seems to supply evidence for neither conjunct.”
Oh, burn!
“But if I replaced the first conjunct with “Corey writes comments on blogs” or something like that, I’d still deny that the conjunction was probed by x, since nothing has been done to check into his nails.”
Sure, x alone cannot provide enough information for a severe test of H&J. But supposing you were uncertain of the truth of either conjunct to start with, would you deny that the conjunction has been *made firmer* by the observation of x? After all, one of the ways it can be in error has been ruled out.
Corey: “Making firmer” is something the confirmation inductivist defines. Whether their definitions capture actual notions of evidence adequately is the question I am asking. So it doesn’t help to say, in effect, according to their (or your) definition it does. That said, I wouldn’t rule out that the notion of evidence I am after differs from theirs. At the very least it opens the door to their recognizing the need for a distinct account of evidence.
On my account, it’s bad evidence no test (BENT)—not a little bit of evidence. (Think of how much worse this procedure is than merely using x to search for subgroups in support of one’s hypotheses, cherry-picking or the like.)
““Making firmer” is something the confirmation inductivist defines.”
That’s not what I’m doing here. I’m claiming that this “purported philosophical confirmation theory” is “in sync with intuitive methodological principles about evidence or testing,” to wit, the intuitive principle that “if evidence x rules out one way a claim could have been in error, then that claim is made firmer”. Albeit x may be BENT according to a severe standard of evidence, do you really deny this intuitive principle? Really really?
“That said, I wouldn’t rule out that the notion of evidence I am after differs from theirs.”
I affirm this. That’s what your “highly probed vs. highly probable” slogan is all about, no?
Rather than rule out error, such a procedure invites them.
I’m taking this procedure as described, start with x that renders H (GTR) “firmer”*, conjoin J (Fukushima radiation) and declare x is evidence for (H and J).(could also do for (H &~J)
*I don’t consider this a sufficient condition for evidence either.
But never mind my account for now, I take it you concur with entailment as in Schervish, as this came up once, way back. If so, then if x is an ‘evidence boost for H’, x is an evidence boost for any J.
I would think that Bayesian statisticians would block the original irrelevant conjunction formally.
Mayo: Right now I’m with Fitelson. I have to go back and check on *exactly* what Schervish asserted.
Corey: I gave the relevant quote and it is standard inductive logic, that if H entails H’, then if x confirms H, then x confirms H’ (he specifies degrees).
I’ve looked over both Fitelson and Schervish, and I conclude that Fitelson is correct to reject the entailment condition. And Schervish… is correct to require it.
“But — but — but — !”
No, look: Fitelson is discussing B-boosts, i.e., “confims” in the sense of “confirms more” (I would say “makes firmer”). See e.g., Fitelson 2004, bottom of page 4, where he notes that ‘the brute comparison of the relative sizes of posterior probabilities is an intuitively unappealing way to cash out the “confirms more” relation.’ When considering how degree of support changes pre-data to post-data, as Fitelson does, the entailment condition is inappropriate.
Schervish (1996) is discussing degrees of support of various claims *strictly post-data*. His language is equivocal in places, but the mathematical and numerical examples he chooses make this clear. It’s even more clear in Lavine and Schervish (1999), where L&S makes similar points regarding Bayes factors; they even entitle section 3 of that paper “Bayes factors are measures of change in support”. When considering how well supported various claims are on a fixed state of information, the entailment condition is appropriate.
The distinction here is analogous to the distinction between stock and flows. Schervish is assessing measures of support as measures of credence stock; Fitelson is assessing measures of confirmation as measures of credence flow.
Mark J. Schervish, 1996. P-values: what they are and what they are not. The American Statistician, 50(3), pp 203-6.
Michael Levine and Mark J. Schervish, 1999. Bayes factors: what they are and what they are not. The American Statistician, 53(2), pp 119-22.
I should clarify that when I wrote, “When considering how well supported various claims are on a fixed state of information, the entailment condition is appropriate,” I meant the entailment condition as Schervish (1996) gives it.
Corey: In fact, it seems one might have the converse of entailment for B-boosts. If H entails H’, then a b-boost of H’ would plausibly B-boost H. What do you think?
“If H’ entails H, then a b-boost of H would plausibly B-boost H’.” (I switched the primed H and unprimed H.)
Without more antecedent assumptions, one can’t conclude anything about the effect on the plausibility of H’ of information that B-boosts H. Here’s an example: let H’ and H” be mutually exclusive and let H be their disjunction (hence H’ entails H). Information that B-boosts H can B-boost H’ without effect on H”, or B-boost H” without effect on H’, or even B-discredit H’ but B-boost H” enough to B-boost H overall.
Corey: I didn’t address your allegation that “one of the ways it [the conjunction] can be in error has been ruled out.” I hope you don’t mean to say z ensures H, because all we have is a B-boost, and it can be minuscule even if H entails z (never mind that outside of cards and counters, we’d almost never know what P(H) and P(J) are.)
Imagine something like…
z: these are patients
H: this drug cures these patients
Mayo: In my specific example, one of the ways H&J (= “Corey comments on blogs and ought to trim his fingernails”) can be in error has been ruled out. I want to start with (deductive) process of elimination and move Sorites-paradox-style into consideration of B-boosts. This is the slow, painstaking way into Cox-Jaynes-style reasoning.
1) Am I right that in your current version you should switch from C to P a bit later, namely after the first paragraph? (This is just about notation, not content.)
2) I wonder whether interval probabilities can play a role here, which decompose the 1-dimensional strength of belief/confirmation modeled by probability into two dimensions, namely a) to what extent x points at either h or h’ (interval midpoint) and b) how strong x is as information regarding this distinction (either way; interval width).
I haven’t thought it through properly but I guess that in your example, although x as evidence for H also points at H&J rather than at its negation, it may be strong and therefore reducing the probability interval width just for H but may not do this for H&J.
Christian: I’m not sure what you’re getting at. Perhaps explain it more fully. Thanks much.
1) I thought that there is a typo in the beginning because you introduce C, not P, and the you switch from C to P before you start talking about probabilities.
2) I was just curious whether interval probabilities (see for example Walley, Peter (1991). Statistical Reasoning with Imprecise Probabilities. London: Chapman and Hall) were taken into account by philosophers in this discussion. With interval probabilities, though, you wouldn’t have a single number to measure confirmation, but rather two, either the lower and upper bound of the interval, or, equivalently, a) midpoint and b) width of the interval, pointing at whether a) the evidence rather confirms some H or not-H, and whether b) the evidence is strong or not. I can’t really explain this much better in a blog comment. If you don’t know what to say, I’d rather interpret this so that interval probabilities have not featured in this debate as far as you know, which is an answer to my question. Correct me if I’m wrong.
Christian: First, i accept that some smoother transition at the beginning is needed; this is kind of an extraction from a longer discussion, but still, I think you’re right. Thanks.
On interval probabilities, the only or main name that comes to mind is Kyburg, who was a friend (who died in 2007). I get the gist of your point, and I’m guessing that philosophers who work in this paradigm will/would likely find themselves creating the kind of context of inquiry or model or set-up that enable statistical inference to avoid a certain amount of chaos (where statements, properties, variables, whatever you like can be plugged in anywhere, without a frame of reference). Of course the a priori generality will go by the board.
I should note that, in the Schervish example, we (error statisticians) actually don’t have a violation of entailment (in the case of statistical hypothesis testing that he raises) because the statistical hypothesis WITHIN one type of test does not deductively entail the statistical hypothesis within an entirely different type of test. There are other qualifications that I’d want to spell out (for error statistical “logic”) but our current discussion is about Bayesian confirmation.
Mayo: I’m not sure what you mean by an “entirely different type of test”. Schervish considered the UMPU test for a specific interval H and the same UMPU test for an interval H’ entailed by H. I’d like you to spell out the qualifications because my own idea of what they are amounts to “only use one-sided hypotheses” and I feel sure this isn’t all there is to it.
Very interesting post. As this was mentioned in the discussion, let me just add a quick follow-up on tacking and Bayesian DISconfirmation. Katya Tentori and I did point out something that seemed to have escaped notice in the earlier literature. That is, if e disconfirms h (on the standard Bayesian definition of decrease of firmness), then e will disconfirm h&x less severely, with x an irrelevant conjunct. This is the case for many popular measures, including the simple difference P(h|e) – P(h), and the likelihood ratio (not the ratio P(h|e)/P(h), though). In principle, one could find this interesting as a further shortcoming of Bayesian analysis. Our line of argument was very different, though: we reconstructed what we took as the rationale of Hawthorne and Fitelson’s solution (for the positive confirmation case), we argued that our little result clashes with that rationale, and went on to suggest a further Bayesian refinement (based on a different confirmation measure in a non-adhoc way). (See: http://www.vincenzocrupi.com/website/wp-content/uploads/2013/02/CrupiTentori2010_conjunction.pdf.)
Vincenzo: Thanks so much for your comment! (Your joint paper was linked also by another commentator). I see your result as what follows from replacing h with its denial (in Fitelson), but I want to come back to it (i.e., to disconfirmation). For now, I just want to be clear on your position regarding the case discussed here (with positive confirmation). I take it you are OK with the treatment of that case, rejecting entailment, but using your measure for the specific B-boost? Or not?
Deborah: (I hope I’m getting your questions right) Yes, I think that so-called Special Consequence Condition (i.e., that E must confirm H* if E confirms H and H entails H*) should not be retained as a general constraint. To my mind, there are simple compelling counterexamples. As for Hawthorne & Fitelson’s general strategy to handle the confirmation case, yes, I find it worthwhile (although alternatives exist) and improved by our analysis.
Isn’t your light/water example a counter-example to your (2)?
Here’s another. H= ‘coin 1 is double-headed’, J=’coin 2 is double-headed’. x is a toss of coin 1, yielding a ‘Head’. x confirms/supports both H and H&J, H&J entails J, but x does not confirm/support J.
Or have I missed something?
David: I would deny that x is good evidence for H (i.e., I’d deny heads on coin 1 is evidence it’s a two sided- coin*). And I certainly would deny x is evidence that both coins are two-sided! Why not declare x evidence about all coins and more?
*Remember I’m an error statistician and thus anti-crude likelihoodist. The probability of finding a hypothesis H that perfectly fits data, while H is false, is high if not maximal.
Statisticians and others: I should note that the use of “irrelevant” as it arises in this philosophical puzzle has been defined in many different ways even within this literature. I am hoping a statistician comments on this, and offers a notion from statistics. For one thing, the conception used here assumes that evidential relevance is a matter of probabilistic relevance (in the sense of a B-boost*) whereas there are many pieces of information that are quite relevant evidentially that do not result in a B-boost. (They might alter things like precision, variability, error probabilities). Examples are very welcome.
*I recommend we use something other than mere “evidence” or “confirmation” as it may confuse other discussions on this blog. “Bayes boost” might work, though I’m not sure what to call “B-lowering”.
I’m not saying you can’t have examples where the conjunction (of events) gets a higher B-boost than the conjuncts. Here’s one from Popper with minor changes in letters (though I still dislike his letters):
“Consider now the conjecture that there are three statements, h, h’, z, such that
(i) h and h’ are independent of z (or undermined by z) while
(ii) z supports their conjunction hh’.
Obviously we should have to say in such a case that z confirms hh’ to a higher degree than it confirms either h or h’; in symbols,
[This one won’t come out right,it has a mind of its own. It’s supposed to be:]
(4.1) C(h,z) is less than C(hh’, z) is greater than C(h’, z)
But this would be incompatible with the view that C(h,z) is a probability, i.e., with
(4.2) C(h,z) = P(h|z)
Since for probabilities we have the generally valid formula
(4.3) P(h|z) > P(hh’|z) < P(h’|z)…..” (LSD, 396-7)
“Take coloured counters, called ‘a’,’b’,…, with four exclusive and equally probable properties, blue, green, red, and yellow.
h: ‘b is blue or green’;
h’: ‘b is blue or red’
z: ‘b is blue or yellow’.
Then all our conditions are satisfied. h and h’ are independent of z. (That z supports hh’ is obvious: z follows from hh’, and its presence raises the probability of hh’ to twice the value it has in the absence of z. (LSD 398)
(The conjunction of h and h’ yields ‘b is blue’.)
Dear Deborah,
Let me provide a simple example in terms of sets, hopefully this can to make your point clear:
Let O = {a,b,c,d} be the universe set endowed with a probability measure P such that:
P({a}) = P({b})=P({c}) = P({d}) = 1/4.
Define the subsets X = {a,b}; Y = {a,c} and Z = {a,d}. Hence, we have:
P(X) = P(Y) = P(Z) = 1/2
and
P(X /\ Y) = P(X /\ Z) = P(Y /\ Z) = P({a}) = 1/4,
where the symbol /\ stands for the intersection. Then, the conditional probabilities are
P(X|Z) = P(X /\ Z)/P(Z) = 1/2 = P(X),
P(Y|Z) = P(Y /\ Z)/P(Z) = 1/2 = P(Y)
and
P(X /\ Y |Z) = P(X /\ Y /\ Z)/P(Z) = P({a})/ P(Z) = 1/2.
It means that X and Y are both independent of Z, but (X /\ Y) is not.
Assume that: C(w,q) = P(w|q)/P(w) is our confirmation measure, then
C(X,Z) = 1, that is, Z does not support X
C(Y,Z) = 1, that is, Z does not support Y
C(X /\ Y,X) = 2, that is, Z does support X /\ Y
In Deborah Mayo's words:
C(X,Z) is lesser than C(X /\ Y, Z) that is greater than C(Y, Z).
Alexandre: Thank you for this. It’s clearer than Popper’s rendering. Philosophers (me included) tend to dabble in truth functional logic rather than set theory, so Popper’s disjunctions are actually more familiar to philosophers, by and large, than sets. This is an aside, but it’s amazing how much this fact tended to obstruct communication with statisticians when it came to my rendering of Birnbaum’s argument for the SLP. Birnbaum mostly uses logic, and Mike Evans converts it (or tries to) into set theory.
Anyway, I’m grateful to have your rendering of the example. Actually, any example where it is purported to have evidence for the conjunction but not a conjunct can work: the only value in Popper’s example is (a) you get numbers, and (b) both conjuncts are individually “irrelevant”.
Alexandre:
I corrected the symbols/typos in your post. What value do you get using LR: P(z|h)/P(z|~h)? Let me know of troubles posting, there shouldn’t be any.
Corrections:
1. “…this can to make your point clear” should be “…this can help to make your point clear”
2. “Assume that: C(w,q) = P(w|q)/P(q)” should be “Assume that: C(w,q) = P(w|q)/P(w)”
3. “C(X /\ Y,X) = 2” should be “C(X /\ Y,Z) = 2”
The symbol “<–" does not mean anything important.
Here’s a little Venn diagram I whipped up for your setup.
Corey: Nice. But can we get it to do anything more? I might put it on a separate post, as this one is getting crowded…
“But can we get it to do anything more?”
What sort of “more” do you have in mind?
Corey: I meant, can we manipulate the figure to get the computations to pop out, e.g., the B-boost measure they call the LR.
You don’t need to manipulate it. Likelihood ratios are just ratios of conditional probabilities, and those can be read off the Venn diagram easily. For example, Pr(~Z|X&Y) = the relative area of ~Z in {a} = 0, which is why Z confirms X&Y.
Mayo: “Statisticians and others: I should note that the use of “irrelevant” as it arises in this philosophical puzzle has been defined in many different ways even within this literature. I am hoping a statistician comments on this, and offers a notion from statistics.”
I certainly can’t speak for all statisticians, but I don’t think we’d use “irrelevant” as well defined technical term at all, at least not outside the graphical models/causality community (somebody else would need to explain whether it features there).
I think that your reasoning here is genuinely philosophical because a typical statistician would probably not worry much about “general measures of confirmation” but rather use probability in applications and then interpret it as frequentist or Bayesian probabilities and nothing more than that. They would think of this “tacking on J”-operation, “why would anybody want to do such a thing?” and go on with their business. Unless perhaps if they are philosophically interested Jaynesians.
Christian: But surely requirements of statistical distributions prevent certain operations like this.
Anyway, what would the philosophically interested Jaynesians do? I’m keen to know.
Because Jaynes starts from Cox’s theorem axiomatising a general plausibility measurement instead of giving probability one of the more traditional meanings associated with relative frequencies or betting.
But really, I’m not a Jaynesian, so it’s better than they themselves (Corey?) tell you whether I’m right about this.
Christian: Sure. So do you suppose x would increase the plausibility of (H&J) whenever x increases the plausibility of H (for J the claim about radiation levels in Fukushima water, H, GTR, as above)? I don’t mind leaving this for interested Jaynesians to reply. Or not.
Yeah, better let somebody else reply. I have no problems with your arguments here, I guess. But that may be because I haven’t yet thought much about how I’d want plausibility measurements to look like. I’m happier with interpretations of probability that make closer reference to what’s observable, such as relative frequencies or betting rates. One of the reasons why I’m not a Jaynesian.
Dr. Mayo,
I don’t see the problem. That Popper example isn’t the slightest bit puzzeling and I don’t see how anyone who equates confirmation with probability can be led astray when
P(H&J|x) &le P(J|x).
No matter what relationship H has to J, and no matter what x does to H&J, you’ll never be fooled into believing x confirms J more than it actually does.
If x is irrelevant to J, then P(J|x)=P(J). That’s perfectly compatible with P(H&J) &le P(H&J|x). There’s no contradiction here.
Anon: And I’d never be fooled into regarding x as evidence for “both H and J”, whenever J is the arbitrary “irrelevant” conjunct called into service.
I gave that example because (a) it was in my blog notes and (b) I noticed no one gave an example yet that successfully illustrated this (in this blog I mean).
I don’t think it’s puzzling either. Popper of course was showing, 50 years ago, that probability isn’t a good measure of confirmation, yet many people seem to think it is, and swear that the posterior is all we need. Are you in favor of it? But, in any event, the current issue concerns B-boosts.
Some of your symbols aren’t showing up right (“&le”), I wasn’t able to get my quote from Popper to show up properly in my last comments.
Dr. Mayo,
There’s two ways a person can react to these examples. They can use them as an excuse to instantly reject probabilities as a measure of confirmation or they can assume our naive notions of “confirmation” are at fault and use these examples to develop a deeper understanding of “confirmation” (probabilities).
When I do the later, I can see both that my prior notions of “confirmation” were too elementary, and that none of this will cause problems for anyone equating probability with confirmation. The inequality:
P(H&J|x) less than or equal to P(J|x)
guarantees that your “conjunction fallacy” will never cause a problem in practice.
I think one of your previous commentators was right when he pointed out that eliminating one way in which H&J can be wrong DOES partially confirm H&J even if it only refers to H. To see this what if we tried to confirm H&J in a two set process. First we eliminate ~H and then we eliminate ~J.
What’s wrong with say after the first step has been completed: “after eliminating ~H we can say we’ve partially confirmed H&J”. None that I can see and that’s what P(H&J|x) does.
Anon: I didn’t mean to appear too quick, but you see I have a very different idea of good/bad evidence, warranted/unwarranted inference, severe/insevere test, and on this notion it’s not only no comfort, but really forfeiting a crucial requirement, to allow that there’s evidence for the tacked on conjunction*. The procedure, in general (and I’ve only heard of “in generals”) has maximally high probability of claiming to have evidence for a claim when that claim is false (or when specifiable flaws are present). I regard this kind of unreliable method as affording bad evidence no test for the claims involved.
Without exaggerating, people go to jail and lose their licenses for lesser offenses like hunting with a shotgun, cherry picking, data-dependent selection effects, and the like (see recent Harkonen post). The poor probativeness can be demonstrated.
One other thing Anon: ask yourself when it would be appropriate to say “x is evidence for both H and J”. I think there are 2 situations….
Finally, on the much simpler issue of identifying confirmation with probability, there are axioms of probability that go by the board if one makes this identification–essentially all of them. So I assume you don’t mean to suggest that is viable while allowing this point to stand, I assume what you mean is it’s still OK to use one of the C functions for B-boost.
*I even have trouble with many of the initial supposedly “relevant” conjuncts, which, if you read the comments, you’ll see.
Thanks for commenting.
Dr. Mayo,
I do think confirmation can be equated with probability and don’t see any contradiction with the axioms of probability.
According to the axioms of probability P(J|e)=P(J) is perfectly compatible with “P(H&J|x) is greater than P(H&J)”, which contradicts your “entailment condition”. That condition isn’t derived however; it’s merely introduced as being intuitively plausible.
Your reaction to this is to reject the identification of “confirmation” with probabilities. My reaction is to reject the “entailment condition” because on closer examination it’s not intuitively plausible.
Anon: No, that’s not the contradiction of axioms. Fine by me for a Bayesian inductive logic to reject the idea that if H entails H’ and x confirms H, then x confirms H’ (to any degree at all)*. It is rather (from my post) “Hypothesis h can be confirmed by x, while h’ disconfirmed by x, and yet P(h|x) < P(h’|x).”
Or go back to the Popper comment with the example of the colored counters (4.1-4.3 makes it blatant). I’m pretty sure that what you mean is that you can retain one of the C measures of B-boosts, and bite all the bullets—but you can’t bite contradictions. And I never claimed Fitelson’s account embraces contradictions, but he does not equate probability P with confirmation C. He uses C-functions that give B-boost values like 2, 2.5, whatever. Someone like Achinstein keeps P (requiring it to be high for confirmation, and denies B-boosts are either necessary or sufficient for evidence). I, of course, am not doing inductive logic. Sorry no time to say more on this tonight.
*Whether incoherency results is another matter.
Dr. Mayo,
OK consider the Popper example instead. You react to that Popper example by rejecting the equating of confirmation with probabilities. I look at that example and think “confirmation can have properties I hadn’t realized at first, upon closer examination those properties are reasonable after all”.
In other words, you view it as a counter to “confirmation=probabilities”, while I merely see it as an opportunity to deepen my understanding of “confirmation” and don’t see it as a contradiction at all.
Anon: Can evidence refute or confirm a hypothesis in your thinking? Is there a point where evidence goes beyond deepening your understanding of confirmation as an exercise?
john byrd,
Of course, but I have a great deal of previous evidence that probabilities can be equated with confirmation, so if an anomaly comes up I’m going to first check to see if my intuition about “confirmation” was wrong before I abandon “confirmation=probabilities”. They didn’t abandon Newtonian Mechanics the first time they found an anomaly in the orbits of the outer planets. They first checked to see if the anomaly could be explained by undiscovered planets.
I understand that anyone with a bias against Bayes is liable to do the opposite.
But the key, as I tried (poorly) to explain above is that at no point will I assign P(J|x) close to 1 when x is indication strong confirmation for ~J. Since the axioms of probabilities seem to have very strong consistency properties I don’t think this is ever going to happen. The only way you can get an anomaly is to introduce a new concept like the “entailment condition” which can’t be derived from the axioms of probability.
Unfortunately, I have no reason to believe the “entailment condition” should be universally true. The same with Popper’s example. There is no reason to think Popper’s example is any kind of contradiction other than it’s slightly surprising at first. In every case, as soon as I look at them deeper, I find myself saying “yeah, confirmation should sometimes work this way, so it makes sense, and I thank the axioms of probability for having educated me better”
Anon: Is there some protocol or principle that compels you to check the P(~J|x)? I do not think many (most) Bayesians do this sort of checking as standard practice, do they?
john byrd,
Or how about putting it like this?
The entailment condition will often be true because we typically deal in practice with H, J which are both affected by x. Because of that we develop an intuition that the entailment condition is true.
On closer examination, we can see that it isn’t derivable from the axioms of probability and shouldn’t be true in general. My previous intuition wasn’t poor, it was incomplete; and by respecting probabilities I was able to improve my intuitive understanding.
Also john byrd,
While it’s not possible for both P(J|x) and P(~J|x) to be large at the same time, it is easy to find examples where both J and ~J pass tests with high Severity using the same data x.
Am I to understand that those people who view the “entailment condition” and Popper’s example as decisively refuting “confirmation=probability” do consider Severity as a better notion of “confirmation”?
Anon: I would like to see such an example.
On the contradiction from P = C.
For people commenting on this, I don’t think you are staring closely enough at 4.1-4.3, and it might be because the less than/greater than signs wouldn’t come out right in the comments and I had to put it in words. So I’m adding a Note [2] to my post, calling it draft (iv).
I’ll try to paste it here too. Let hh’ abbreviate (h and h’).
I use a different tack:
Consider a case where z confirms hh’ more than z confirms h’: C(hh’,z) > C(h’,z)
Now h’ = (~hh’ or hh’)
So,
(i) C(hh’,z) > C(~hh’ or hh’,z)
Since ~hh’ and hh’ are mutually exclusive, we have from special addition rule
(ii) P(hh’,z) < (or =) P(~hh’ or hh’,z)
So if P = C, (i) and (ii) yield a contradiction
Ok, but what if confirmation is defined this way:
x partially confirms H if P(H|x) is greater than P(H).
That’s the way everyone thinks and uses probabilities. Where is the contradiction?
Also Dr. Mayo,
Since P(hh’|z) is always less than or equal to P(h’|z) you could never have
“Consider a case where z confirms hh’ more than z confirms h’: C(hh’,z) greater than C(h’,z)”
if you identify P=C.
Anon: You don’t seem to get that it is the supposition of the Bayesian confirmationist that we can have confirmation for the conjunction but not for its conjunct. I’m granting it, and showing one therefore cannot have C = P. I don’t think this is controversial—or at least, I didn’t think so..
Please go back to the Popper “colored counter” example, or the conjunction H&J in the post.
My response to the your “contradiction” is to believe even stronger in P=C and merely require that
“Consider a case where z confirms hh’ more than z confirms h’: C(hh’,z) greater than C(h’,z)”
can’t happen. Upon reflection it makes sense to me that it shouldn’t happen. It makes sense to me that the presence of an extra h should always lower the confirmation (unless h is for sure true in which case it will have no effect). I’ll never be lead astray or be fooled into thinking z confirms something when it doesn’t.
Dr. Mayo,
What I was very clumsily trying to say her is that this perfectly illustrates my point from before.
One reaction to your derivation is to say P=C is a contradiction. Another legitimate reaction is to retain the identification P=C and see if there is a problem with assumptions like:
“Consider a case where z confirms hh’ more than z confirms h’: C(hh’,z) greater than C(h’,z)”
After looking at this it seems perfectly reasonable to say that z can’t confirm two things more than it confirms one (which is what probabilities would imply).
That was my point. There’s always two ways to react to these examples. One is to reject P=C and the other is to keep P=C and think harder about what “confirm” should mean.
Dear Anon,
Let us assume that the confirmation can be defined by the following two components: P(H|x) and P(H).
As you said: If P(H|x) > P(H) then ¨x partially confirms H¨.
Let P(H)>0 and define
C(H,x) = P(H|x)/P(H),
if C(H,x)>1 then ¨x partially confirms H¨ in your words.
Now, I can ask you: Do you think that C acts as a probability?
I can show that C does not act like a probability.
Let H and H’ be two incompatible propositions with positive probabilities. If C satisfy the probability rules, we would expect that
(@) C(H \/ H’, x) = C(H,x) + C(H’,x)
Let’s see if (@) is true?
By definition:
C(H \/ H’, x) = P(H \/ H’|x)/P(H \/ H’).
As P is a probability measure, we have
P(H \/ H’) = P(H) + P(H’)
and
P(H \/ H’ |x) = P(H|x) + P(H’|x).
Then, pluggin the above results, we obtain:
C(H \/ H’, x) = P(H|x)/ [P(H) + P(H’)] + P(H’|x) / [P(H) + P(H’)]
Define d = P(H) / [P(H) + P(H’)], then
(#) C(H \/ H’, x) = d*C(H,x) + (1-d)*C(H’,x)
As P(H) and P(H’) are both greater than zero, the equations (#) and (@) do not match.
Here, we derive the rule the governs the measure C. As you can see, the rule is not the usual additivity.
Best,
Alexandre.
PS: I don’t revise the text, probably it has some typos.
Alexandre,
In no way was I trying to say P(H|x)/P(H) or P(H|x)-P(H) or anything equivalent was a probability.
Anon,
you said:
“Ok, but what if confirmation is defined this way:
x partially confirms H if P(H|x) is greater than P(H).
That’s the way everyone thinks and uses probabilities. Where is the contradiction?”
In your sentence: “x partially confirms H if P(H|x) is greater than P(H)” you are precisely trying to identify confirmation with P(H|x)/P(H) > 1 or P(H|x) – P(H)>0.
That is, you are implicitly stating that C(H,x) = P(H|x)/P(H) or C(H,x) = P(H|x) – P(H).
What ever is the case above, C cannot be a probability measure.
What is wrong here?
Alexandre,
You have just showed that x “confirms” H V H’ just as it confirms each one separately. That is
C(H \/ H’, x) = d*C(H,x) + (1-d)*C(H’,x)
where d is the weight of prior evidence of H and 1-d the wheight of prior evidence on H’.
So assume that x has nothing to do with H’
Then we have that
C(H \/ H’, x) = d*C(H,x)
That is, x “confirms” H V H’ just to the extent that it confirms H, and just to the extent that H is weighted in the compound hypothesis.
And this is how it is supposed to be. That does not mean that x supports H’ at all and that does not mean that because x supports H V H’ you are allowed to claim that x supports H’.
Let`s give a very simple example.
Assume that x is a sample of 100 white swans.
H is the hypothesis: 90% of the swans are white.
H` is the hypothesis: Obama will win the election.
x confirms H
x does not confirms H’
x conforms H V H’ just to the extent that it confirms H, because this is a conjunct hypothesis.
There is nothing wrong with the statements above.
Anon: Good. I’m glad we cleared that up. You are now rejecting the idea of confirmation as a probability boost, what I was calling B-boost (and reversing your agreement with Corey). Then you can reject confirming “tacked on” conjuncts, and retain entailment. I think this puts you at odds with (most?) Bayesian epistemologists though.
We are talking past each other which is very unsatisfying. In the end anyone can show P=C is wrong by assuming properties for C which can’t be derived from the axioms of probability theory.
You think this is decisive because you have a strong bias against Bayes. But whenever I examine those assumed properties for C in all the examples you’ve brought up they always appear to the wrong and undesirable (even if they seem plausible at first).
Anon: And there I thought we’d actually come to agree (i.e., that anyone adopting “those properties”, which those advancing the standard Bayesian treatment of tacking do) cannot at the same time identify P and C. Very straightforward.
But the important thing that readers should and most do know is this: “I have no dog in this fight” (as the expression goes); since what I’m doing and care about wrt evidence, testing, inductive inference seems far away from any of the Bayesian inductive philosophies on offer (which I also distinguish from Bayesian statistics–see Hennig’s post). The fundamental–minimal– requirement for an adequate account of evidence and inference as I see it is to eschew maximally or highly unreliable methods, e.g., claiming warrant for the (data-dependent) best fitting hypothesis. So I get off at the first conjunct, so to speak. I’m just trying to understand at least 2 very different philosophical inductive logics. Those are the traditions I was raised in , so to speak, and they still interest me.
Just so people know: I did of course send Fitelson a link to my post, and he said he’d have a look when he returns from Europe.
This is a purely semantic problem.
When you say:
“Paraphrasing him, we would not be assured by an account that tells us deflection of light data (x) confirms both GTR (H) and the radioactivity of the Fukushima water is within acceptable levels (J), while assuring us that x does not confirm the Fukishima water having acceptable levels of radiation (31).”
There is a semantic confusion.
See:
(x) does not confirm ~both~ H and J.
(x) confirms only H and does not confirm J
But when we create (H&J) the logic changes:
What happens is that when (x) “confirms” (H&J) this is logically equivalent to “x confirms H or J”.
It is the logical ~or~ not the logical ~and~.
The statement that “x confirms H or J” is logically valid and it is not a puzzle at all.
So the problem here is the conflation of two statements: “x confirms H or J” with “”x confirms both H and J”.
Let me be more precise.
More formally,
If C(H \/ J, x) >1
This implies that (using Alexandre’s notation)
dC(H,x) + (1-d)*C(J,x) > 1
which means that x supports either H or J or both.
In logic this is equivalent to say:
“x confirms H or J”
Which is a fine and logical statement.
Now the funny thing is that p-values would also have the same “problem”:
Assume that Prob( X>x; H) = 0.000001
If x is independent of J
Then
(*) Prob(X>x; H and J) = Prob(X>x; H) = 0.000001
Of course, there is nothing wrong with that.
This would only generate confusion if someone interpreted (*) as evidence against both H and J, which would be just a semantic confusion.
In the case of the p-value, the correct logical interpretation of Prob(X>x; H and J)=0.000001 would be (assuming you did not know which conjunction is irrelevant)
Either:
(i) H is false and J is true
(ii) J is false and H is true
(iii) both J and H are false
(iv) both J and H are true and a very very very unlikely event has occurred
We can easily see that, assuming that you agree with the frequentist reasoning, the only inference you could say is that
“we have good evidence that H ~or~ J is false because our test would not give an extreme result like this if both were true”
Now, if you can easily follow the explanation above, it should come with no difficulty the understanding of the “problem” in the bayesian setting.
If C(H \/ J, x) >1
Either:
(i) (x) supports H more than it decreases J
(ii) (x) supports J more than it decreases H
(iii) (x) supports both H and J
The only inference you are allowed to say is that
“since x increases the posterior probability of the conjunction H and J, then x supports H or J.”
You can`t say that it supports both H and J. This is not a logical implications of C(H VJ, x)>1 just as it is not a logical implication in the p-value case.
Pingback: What Statistics Really Is: Paradox Digression | William M. Briggs
Hi Mayo, not sure if you still read the comments on these old posts. I wrote a summary of my views/preferred ‘solution’ here:
https://omaclaren.wordpress.com/2015/10/06/the-tacking-paradox-model-closure-and-irrelevant-hypotheses/
Thanks again for blogging about this stuff – makes it easier for us more ‘applied’ folk to see what the basic problems in the philosophy of science are and what they might mean for our day-to-day work.