

.
Such articles have continued apace since this blogpost from 2013. During that time, meta-research, replication studies, statistical forensics and fraudbusting have become popular academic fields in their own right. Since I regard the ‘programme’ (to use a Lakatosian term) as essentially a part of the philosophy and methodology of science, I’m all in favor of it—I employed the term “metastatistics” eons ago–but, as a philosopher, I claim there’s a pressing need for meta-meta-research, i.e., a conceptual, logical, and methodological scrutiny of presuppositions and gaps in meta-level work itself. There was an issue I raised in the section “But what about the statistics?” below that hasn’t been addressed. I question the way size and power (from statistical hypothesis testing) are employed in a “diagnostics and screening” computation that underlies most “most findings are false” articles. (This is (2) in my new “Let PBP” series, and follows upon my last post, comments in burgandy are added, 12/5/15.)
In this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures. Science writers are under similar pressures, and to this end they have found a way to deliver up at least one fire-breathing, front page article a month. How? By writing minor variations on an article about how in this time of government cut-backs and sequester, scientists are under increased pressure to dream up ever new strategies to publish attention-getting articles with eye-catching, but inadequately scrutinized, conjectures. (I’m prepared to admit that meta-research consciousness raising, like “self help books,” warrant frequent revisiting. Lessons are forgotten, and there are always new users of statistics.)
Thus every month or so we see retreads on why most scientific claims are unreliable, biased, wrong, and not even wrong. Maybe that’s the reason the authors of a recent article in The Economist (“Trouble at the Lab“) remain anonymous. (I realize that is their general policy.)
I don’t disagree with everything in the article; on the contrary, part of their strategy is to include such well known problems as publication bias, nonreplicable priming studies in psychology, hunting and fishing for significance, and failed statistical assumptions. But the “big news”—the one that sells—is that “to an alarming degree” science (as a whole) is not reliable and not self-correcting. The main evidence is that there are the factory-like (thumbs up/thumbs down) applications of statistics in exploratory, hypotheses generating contexts wherein the goal is merely screening through reams of associations to identify a smaller batch for further analysis. But do even those screening efforts claim to have evidence of a genuine relationship when a given H is spewed out of their industrial complexes? Do they go straight to press after one statistically significant result? I don’t know, maybe some do. (Shame on them!) What I do know is that the generalizations we are seeing in these “gotcha” articles are (often) as guilty of sensationalizing without substance as the bad statistics they purport to be impugning. As they see it, scientists, upon finding a single statistically significant result at the 5% level, declare an effect real or a hypothesis true, and then move on to the next hypothesis. No real follow-up scrutiny, no building on discrepancies found, no triangulation, self-scrutiny, etc.
But even so, the argument which purports to follow from “statistical logic”, but which actually is a jumble of “up-down” significance testing, Bayesian calculations, and computations that might at best hold for crude screening exercises (e.g., for associations between genes and disease) commits blunders about statistical power, and founders. Never mind that if the highest rate of true outputs was wanted, scientists would dabble in trivialities….Never mind that I guarantee if you asked Nobel prize winning scientists the rate of correct attempts vs blind alleys they went through before their Prize winning results, they’d say far more than 50% errors, (Perrin and Brownian motion, Prusiner and Prions, experimental general relativity, just to name some I know.)
But what about the statistics?
It is assumed that we know that, in any (?) field of science, 90% of hypotheses that scientists consider are false. [A] Who knows how, we just do. Further, this will serve as a Bayesian prior probability to be multiplied by rejection rates in non-Bayesian hypothesis testing.
Ok so (1) 90% of the hypotheses that scientists consider are false. Let γ be “the power” of the test. Then the probability of a false discovery, assuming we reject H0 at the α level is given by the computation I’m pasting from an older article on Normal Deviate’s blog.
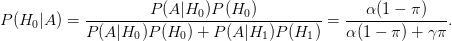
Again, γ is “the power” and A = “the event of rejecting H0 at the α level”. They use α = .05.
So, let’s see…
(1) is equated to 90% of null hypotheses in significance testing are true!
So P(H0) = .9, and P(not-H0) = .1.
A false hypothesis means the null of a significance test is true. What is a true hypothesis? It would seem to be the denial of H0, i.e., not-H0. Then the existence of any discrepancy from the null would be a case in which the alternative hypothesis is true. Yet their example considers
P(x reaches cut-off to reject H0|not-H0) = .8.
They call this a power of .8. But the power is only defined relative to detecting a specific alternative or discrepancy from the null, in a given test. You can’t just speak about the power of a test (not that it stops the front page article from doing just this). But to try and make sense of this, they appear to mean
“a hypothesis is true” = there is truly some discrepancy from H0 = not-H0 is true.
But we know the power against (i.e., for detecting) parameter values very close to H0 is scarcely more than .05 (the power at H0 being .05)!
So it can’t be that what they mean by a true hypothesis is “not-H0 is true”.
Let’s try to use their power of .8 to figure out, then, what a true hypothesis is supposed to be.
Let x* be the .05 cut-off for the test in question (1 or 2-sided, we’re not told, I assume 1-sided).
P(test rejects H0 at the .05 level| H’) = .8.
So all we have to do to find H’ is consider an alternative against which this test has .8 power.
But H0 together with H’ do not exhaust the space of parameters. So you can’t have this true/false dichotomy referring to them. Let’s try a different interpretation.
Let “a hypothesis is true” mean that H’ is true (where the test has .8 power against H’). Then
“a hypothesis is false” = the true parameter value is closer to H0 than is H’.
But then the .05 probability of erroneous rejections is no longer .05, but would be much larger—very close to the power .8. So I fail to see how this argument can hold up.
Suppose, for example, we are applying a Normal test T+ of H0: µ ≤ 0 against H1: µ > 0, and x* is the ~.025 cut-off: 0 + 2(σ/√n), where for simplicity let σ be known (and assume iid is not itself problematic). Then
x* + 1(σ/√n)
brings us to µ = 3(σ/√n), an alternative H‘ against which the test has .84 power—so this is a useful benchmark and close enough to their .8 power.
To have some numbers, let σ = 2, and n =100 so σ/√n = .2. Then the cut-off for rejection is x* = .4.
Consider then H0: µ ≤ 0 and H‘:µ > 3(σ/√n).
So the alternative is H‘:µ > .6. But H0 and H‘ do not exhaust the hypothesis space, so how could they have the “priors” (of .9 and .1) they assign?
It’s odd, as well, to consider that the alternative to which we assign .1 prior is to be determined by the test to be run. I’m prepared to grant there is some context where there are just two point hypotheses; but their example involves associations, and one would have thought degrees were the norm.
I’ll come back to this when I have time later …—I put it here as a place holder for a new kind of howler we’ve been seeing for the past decade. …Since I do believe in error correction, please let me know where I have gone wrong.
This is the second (2) in a series on “Let PBP”. The first was my last post.
Notes from 12/5/15 begin with [A]. So far just one.
[A] While the “hypotheses” here generally refer to substantive research or causal claims, their denials are apparently statistical null hypotheses of 0 effect. Moving from rejecting one of these nil hypotheses to the research claim is already a howler not countenanced by proper significance testing. This is what the fallacious animal, NHST, is claimed to permit. So I use this acronym only for the fallacious entity.
Original notes:
[1] I made a few corrections (i.e., the original post was draft (iii) which has nothing to do with the numbering I’m now using for “LetPBP” posts).
[2] See larger version of this great cartoon (that did not come from their article.)
[3] To respond to a query on power (in a comment): Power: For the Normal testing example with T+: H0: µ ≤ µ0 against H1: µ > µ0. (Please see the comments from the original post.)
Test T+: Infer a (positive) discrepancy from µ0 iff {x > x*) where x* corresponds to a difference statistically significant at the α level (I’m being sloppy in using x rather than a proper test stat d(x), but no matter).
Z =(x*- µ1 ) √n (1/σ)
I let x* = µ0+ 2(σ/√n)
So, with µ0= 0, and µ1= 3(σ/√n),
Z = [2(σ/√n) – 3(σ/√n)] (√n /σ) = -1
P(Z > -1) = .84
For (quite a lot) more on power, search power on this blog.


")


It’s interesting to consider how things have changed, and also remained the same, in the past 2-3 years regarding meta-statistical research, and in articles written both for poplar and academic consumption. I always have a sneaking suspicion that once protests of mainstream research (or nearly anything else) become mainstream themselves, that certain assumptions built into the programme remain hard-wired.
This is one of the most constructive, and provocative, things you have written. Thanks for doing so. It must be maddening to watch the evolution of what constitutes an infinite regress: Articles about the articles that have been written about other articles, etc. etc. etc. . . . . . . . .
James: Thanks so much for your comment. I’d like to hear more about your perspective and interest in this issue. I don’t recall you as a previous commenter.
I infrequently comment but always read your blog. Plus, I have read and re-read your fine textbook Error and the Growth of Experimental Knowledge. I only wish you had written it 25 years ago !
James: Well, it is getting onto 20 years, ugh. (How would it have changed your perspective earlier on?) If you e-mail me an address, I’ll send you ERROR AND INFERENCE (2010). This is a set of exchanges (my responses to critics) based initially on a conference, ERROR06, and edited by Mayo and Spanos.
On your earlier comment regarding articles on articles, frankly, I wish the contemporary authors would recognize the earlier articles. The exposes take on the tone of someone boldly blurting out a novel truth for the very first time, and high praise is lavished on the science writer as an edgy debunker.
For a sarcastic take on a “3-step recipe” for writing such exposes, see near the end of “Saturday night brainstorming and taskforces” https://errorstatistics.com/2015/01/31/2015-saturday-night-brainstorming-and-task-forces-1st-draft/
There are also sloppy statements about type 1 and 2 errors in that article. “A type I error is the mistake of thinking something is true when it is not (also known as a “false positive”). A type II error is thinking something is not true when in fact it is (a “false negative”).”
Is the “something is true” the effect is real, or the null is not true? Also “thinking something is not true” is not “the null hypothesis is true”. I haven’t worked through the rest.
e. berk:
It’s kind of scary to hear such vague language, even in a popular article. The statements of type 1 and 2 errors are indeed equivocal, and run together the denial of the null (assertions of discrepancies from the null) with the research claim. I hadn’t looked back at the article itself in awhile, aside from the statistical part I discuss. People who haven’t read it can find it at:
http://www.economist.com/news/briefing/21588057-scientists-think-science-self-correcting-alarming-degree-it-not-trouble
Another worrisome claim is this:
“By and large, scientists want surprising results, and so they test hypotheses that are normally pretty unlikely and often very unlikely.”
What? This is confusing the desire to test H’s predictions that would be improbable were H false, with H itself being unlikely,yet another equivocal term.
Remarks by an editor of Science near the end of the article are quite rightheaded: “In testimony before Congress on March 5th Bruce Alberts, then the editor of Science, outlined what needs to be done to bolster the credibility of the scientific enterprise. …. Budding scientists must be taught technical skills, including statistics, and must be imbued with skepticism towards their own results and those of others. …Funding agencies should encourage replications and lower the barriers to reporting serious efforts which failed to reproduce a published result.”
There are two guest posts on this article (“Trouble in the Lab”) by statisticians who also write on matters of replication. Even though their focus isn’t the point I’m on about (which is the main reason I’m reblogging this) they’re really interesting and lots of good discussion ensued. The first was by Staley Young, https://errorstatistics.com/2013/11/16/s-stanley-young-more-trouble-with-trouble-in-the-lab-s-stanley-young-guest-post/
the second by Tom Kepler:
https://errorstatistics.com/2013/11/13/t-kepler-trouble-with-trouble-at-the-lab-guest-post/
Sending this post to Sander Greenland, he surprised me by forwarding a paper by him and Goodman with some similar points: https://errorstatistics.files.wordpress.com/2014/09/goodman-greenland-on-ioannidis-jhu-bepress-2007.pdf
There are a number of commentaries spurred by a recent _front page article_ there a reviewed here https://www.sciencenews.org/blog/context/make-science-better-watch-out-statistical-flaws
including Goodman, David Cox and Andrew and I.
I prefer ours – form the online review “A commentary in Biostatistics coauthored by Gelman and Keith O’Rourke congratulated Jager and Leek for their “boldness in advancing their approach” but concluded that “what Jager and Leek are trying to do is hopeless.”
“We admire the authors’ energy and creativity, but we find their claims unbelievable … and based on unreasonable assumptions.”
Keith
Phan: Thanks so much for linking to it here. Of course, I’m familiar with it, and linked to Goodman and Greenland, but this is the Jager/Leek critique of Ioannidis, which itself was highly criticized (was it not?) Despite the problems with Jager and Leek, I do recall reading articles denying Ioannidis’ numbers are manifested in reality. In fact, his computations–in his own discussion– require quite a bit of “bias” (P-hacking and selection effects that raise the type 1 error probability) to get the untoward results for which he is famous. David Colquhoun runs a simulation akin to Berger and Sellke, Ioannidis, Berger and others, and regards it as iron clad.
Here’s a link:
http://rsos.royalsocietypublishing.org/content/1/3/140216
I’d be interested to know what you think.
I am going to just agree with Anoneuoid – you can’t make chicken salad from chicken s*** but what you can do is focus efforts on getting some real chicken.
An old attempt of mine was reviewed by Andrew a few years ago http://andrewgelman.com/2012/02/12/meta-analysis-game-theory-and-incentives-to-do-replicable-research/
Its an old problem but that is currently getting a lot of money and academic opportunities thrown at it.
The title of your blog post is very appropriate – what lead to the funding and creation of non-replicatable research is now again leading to methodological research that’s not much critically informed than chicken little.
Keith
I am going to just agree with Anoneuoid – you can’t make chicken salad from chicken feathers but what you can do is focus efforts on getting some real chicken.
An old attempt of mine was reviewed by Andrew a few years ago http://andrewgelman.com/2012/02/12/meta-analysis-game-theory-and-incentives-to-do-replicable-research/
Its an old problem but that is currently getting a lot of money and academic opportunities thrown at it.
The title of your blog post is very appropriate – what lead to the funding and creation of non-replicatable research is now again leading to methodological research that’s not much critically informed than chicken little.
Keith
Keith: Yes, you’re exactly gettingmy main drift. In fact, if we take seriously the hypotheses often put forward to explain nonreplicable research––namely, the great rewards dangled in front of ambitious researches, coupled with the flexibility to massage interpretations of results in many fields––then it would follow the same motivations operate in meta-research. (In my first blog on the replicability problem in psych, I even joked that “non-significance is the new significance”.) I would like to propose the formation of a group of meta-meta-researchers!
I am beginning to think it is just too early in the medical research reform effort even to discuss the statistical aspects. People are realizing these papers are not even reproducible in principle, what good are stats using data of ambiguous origin that can never be verified? The cancer reproducibility project has already dropped 25% of the replications because it became too expensive to get the required data/protocols/materials:
“Amassing all the information needed to replicate an experiment and even figure out how many animals to use proved “more complex and time-consuming than we ever imagined,” Iorns says. Principal investigators had to dig up notebooks and raw data files and track down long-gone postdocs and graduate students, and the project became mired in working out material transfer agreements with universities to share plasmids, cell lines, and mice.”
http://www.sciencemag.org/content/348/6242/1411
“The team scrutinized the 23 replication studies that had made the least progress and chose to stop pursuing 10 that involved animal experiments and another three for which contact with the original authors had been minimal.”
http://www.nature.com/news/cancer-reproducibility-project-scales-back-ambitions-1.18938
So first things first, require detailed methods sections and sharing of raw data. Next, have a system in place that leads to routine replication attempts. Last, figure out what should be done about that stats problem.
Anoneuoid: Thanks so much for the two links which I’d missed. I recommend them to readers. The cancer studies are quite a contrast from the psych ones which only involve putting the study on a round of experiments from which students choose (as is required for their studies). Still, the psych expers have problems cancer studies likely do not: the replicators’ attitudes toward the thesis tends to come through. Oddly, at least the one I read in detail, replicators informed the students it was a replication attempt but asked them not to tell other students who might sign up over the next year!
Anyway, this is beside the point of the issue I raise now. Your, entirely sensible, point is that we don’t really know what the replication rates are in reality,or would be if experiments were described in better detail. The point of the “most findings are false” computation (in my post) is to claim that they can prove analytically that using certain methods will result in over 50% false positives. They don’t even have to look at empirical data. On the basis of such a computation, many argue against the methodology altogether. The reason we cannot wait to correct these conclusions on which denunciations of certain methods are based, is that leading outfits are not waiting (not just science writers but journal editors and even the American Statistical Association). They’re keen to ban or shun the methods right now. I’m not saying this particular computation is the only one used in claiming to show what’s wrong with statistical tests. There are others, and they suffer from their own shortcomings–or so I argue.
“The point of the “most findings are false” computation (in my post) is to claim that they can prove analytically that using certain methods will result in over 50% false positives.”
Yes, I do not understand why so many seem convinced by these arguments. However, you can see the same thing in the psychology effort to replace replications with prediction markets. I speculate that people want any excuse to avoid actually funding/doing the replication. I say just double check results before hanging your hat (theorizing) on them, it is that simple.
Anoneuoid: I never thought the psych people were trying to “replace” replications with predictions markets, even though I find the predictions markets in replications extremely crude and think they do further damage to the scientific credentials of psych (or other) research being bet on.
“Apart from rigorous replication of published studies, which is often perceived as unattractive and therefore rarely done, there are no formal mechanisms to identify irreproducible findings. Thus, it is typically left to the judgment of individual researchers to assess the credibility of published results. Prediction markets are a promising tool to fill this gap, because they can aggregate private information on reproducibility, and can generate and disseminate a consensus among market participants.”
http://www.pnas.org/content/early/2015/11/04/1516179112.abstract
Anoneuoid: Oh my gawd! You’re right. And to see Nosek in on this. Of course it only shows what we all know: the toy experiments, far-fetched artificial scenarios & proxy variables, in many psych experiments are incapable of grounding the proposed inferences. So rather than be self-critical of those flawed studies, and stop doing them, this is put forward as a new, cool way to obtain evidence (without showing what’s wrong with the initial study). Why Nosek would sign on to this is beyond me.
But imagine trying this for cancer research–the two other links you sent. I guarantee that the flawed cases wouldn’t be at all obvious. Though maybe people who work in the particular area or who know the researchers could predict. Who needs evidence and data when you can just ask people to bet?
> Though maybe people who work in the particular area or who know the researchers could predict.
I think knowing the researchers would help but I did an informal survey of clinical researchers with many years of experience on this and they thought it would be very hard.
This was one response –
Hmmm
I agree hard to tell from the publication and yes, you can fool all of the people most of the time
The thing I use, is whether the result makes sense or is plausible
Sometimes I see effect sizes that are way too large in the context of the baseline problem and nature of the intervention
That is the main way I “ smell a rat”
But most of the time that is not true
Keith
Phan: I worry that this whole way of looking at the issue encourages trivial research, or unchallenging efforts. For example, Ioannidis recommends focusing on a priori plausible hypotheses––but I see this as the way to guarantee small increases in learning. Instead, researchers should include ample efforts of how they have bent over backwards to subject their studies to probes of plausible gaps and errors. They should hold off publishing until they’ve stringently probed several ways they could be wrong, and yet have found the results hold up.
Click to access pmed-goodman-greenland.pdf