

1.3
Continue to the third, and last stop of Excursion 1 Tour I of Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars (2018, CUP)–Section 1.3. It would be of interest to ponder if (and how) the current state of play in the stat wars has shifted in just one year. I’ll do so in the comments. Use that space to ask me any questions.
How can a discipline, central to science and to critical thinking, have two methodologies, two logics, two approaches that frequently give substantively different answers to the same problems? … Is complacency in the face of contradiction acceptable for a central discipline of science? (Donald Fraser 2011, p. 329)
We [statisticians] are not blameless … we have not made a concerted professional effort to provide the scientific world with a unified testing methodology. (J. Berger 2003, p. 4)
From the aerial perspective of a hot-air balloon, we may see contemporary statistics as a place of happy multiplicity: the wealth of computational ability allows for the application of countless methods, with little handwringing about foundations. Doesn’t this show we may have reached “the end of statistical foundations”? One might have thought so. Yet, descending close to a marshy wetland, and especially scratching a bit below the surface, reveals unease on all sides. The false dilemma between probabilism and long-run performance lets us get a handle on it. In fact, the Bayesian versus frequentist dispute arises as a dispute between probabilism and performance. This gets to my second reason for why the time is right to jump back into these debates: the “statistics wars” present new twists and turns. Rival tribes are more likely to live closer and in mixed neighborhoods since around the turn of the century. Yet, to the beginning student, it can appear as a jungle.
Statistics Debates: Bayesian versus Frequentist
These days there is less distance between Bayesians and frequentists, especially with the rise of objective [default] Bayesianism, and we may even be heading toward a coalition government. (Efron 2013, p. 145)
A central way to formally capture probabilism is by means of the formula for conditional probability, where Pr(x) > 0:
![]()
Since Pr(H and x) = Pr(x|H)Pr(H) and Pr(x) = Pr(x|H)Pr(H) + Pr(x|~H)Pr(~H), we get:
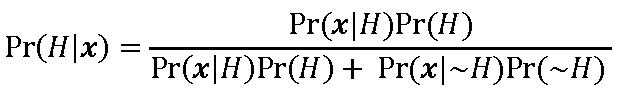
where ~H is the denial of H. It would be cashed out in terms of all rivals to H within a frame of reference. Some call it Bayes’ Rule or inverse probability. Leaving probability uninterpreted for now, if the data are very improbable given H, then our probability in H after seeing x, the posterior probability Pr(H|x), may be lower than the probability in H prior to x, the prior prob- ability Pr(H). Bayes’ Theorem is just a theorem stemming from the definition of conditional probability; it is only when statistical inference is thought to be encompassed by it that it becomes a statistical philosophy. Using Bayes’ Theorem doesn’t make you a Bayesian.
Larry Wasserman, a statistician and master of brevity, boils it down to a contrast of goals. According to him (2012b):
The Goal of Frequentist Inference: Construct procedure with frequentist guarantees [i.e., low error rates].
The Goal of Bayesian Inference: Quantify and manipulate your degrees of beliefs. In other words, Bayesian inference is the Analysis of Beliefs.
At times he suggests we use B(H) for belief and F(H) for frequencies. The distinctions in goals are too crude, but they give a feel for what is often regarded as the Bayesian-frequentist controversy. However, they present us with the false dilemma (performance or probabilism) I’ve said we need to get beyond.
Today’s Bayesian–frequentist debates clearly differ from those of some years ago. In fact, many of the same discussants, who only a decade ago were arguing for the irreconcilability of frequentist P-values and Bayesian measures, are now smoking the peace pipe, calling for ways to unify and marry the two. I want to show you what really drew me back into the Bayesian–frequentist debates sometime around 2000. If you lean over the edge of the gondola, you can hear some Bayesian family feuds starting around then or a bit after. Principles that had long been part of the Bayesian hard core are being questioned or even abandoned by members of the Bayesian family. Suddenly sparks are flying, mostly kept shrouded within Bayesian walls, but nothing can long be kept secret even there. Spontaneous combustion looms. Hard core subjectivists are accusing the increasingly popular “objective (non-subjective)” and “reference” Bayesians of practicing in bad faith; the new frequentist–Bayesian unificationists are taking pains to show they are not subjective; and some are calling the new Bayesian kids on the block “pseudo Bayesian.” Then there are the Bayesians camping somewhere in the middle (or perhaps out in left field) who, though they still use the Bayesian umbrella, are flatly denying the very idea that Bayesian updating fits anything they actually do in statistics. Obeisance to Bayesian reasoning remains, but on some kind of a priori philosophical grounds. Let’s start with the unifications.
While subjective Bayesianism offers an algorithm for coherently updating prior degrees of belief in possible hypotheses H1, H2, …, Hn, these unifications fall under the umbrella of non-subjective Bayesian paradigms. Here the prior probabilities in hypotheses are not taken to express degrees of belief but are given by various formal assignments, ideally to have minimal impact on the posterior probability. I will call such Bayesian priors default. Advocates of unifications are keen to show that (i) default Bayesian methods have good performance in a long series of repetitions – so probabilism may yield performance; or alternatively, (ii) frequentist quantities are similar to Bayesian ones (at least in certain cases) – so performance may yield probabilist numbers. Why is this not bliss? Why are so many from all sides dissatisfied?
True blue subjective Bayesians are understandably unhappy with non- subjective priors. Rather than quantify prior beliefs, non-subjective priors are viewed as primitives or conventions for obtaining posterior probabilities. Take Jay Kadane (2008):
The growth in use and popularity of Bayesian methods has stunned many of us who were involved in exploring their implications decades ago. The result … is that there are users of these methods who do not understand the philosophical basis of the methods they are using, and hence may misinterpret or badly use the results … No doubt helping people to use Bayesian methods more appropriately is an important task of our time. (p. 457, emphasis added)
I have some sympathy here: Many modern Bayesians aren’t aware of the traditional philosophy behind the methods they’re buying into. Yet there is not just one philosophical basis for a given set of methods. This takes us to one of the most dramatic shifts in contemporary statistical foundations. It had long been assumed that only subjective or personalistic Bayesianism had a shot at providing genuine philosophical foundations, but you’ll notice that groups holding this position, while they still dot the landscape in 2018, have been gradually shrinking. Some Bayesians have come to question whether the wide- spread use of methods under the Bayesian umbrella, however useful, indicates support for subjective Bayesianism as a foundation.
Marriages of Convenience?
The current frequentist–Bayesian unifications are often marriages of convenience; statisticians rationalize them less on philosophical than on practical grounds. For one thing, some are concerned that methodological conflicts are bad for the profession. For another, frequentist tribes, contrary to expectation, have not disappeared. Ensuring that accounts can control their error probabilities remains a desideratum that scientists are unwilling to forgo. Frequentists have an incentive to marry as well. Lacking a suitable epistemic interpretation of error probabilities – significance levels, power, and confidence levels – frequentists are constantly put on the defensive. Jim Berger (2003) proposes a construal of significance tests on which the tribes of Fisher, Jeffreys, and Neyman could agree, yet none of the chiefs of those tribes concur (Mayo 2003b). The success stories are based on agreements on numbers that are not obviously true to any of the three philosophies. Beneath the surface – while it’s not often said in polite company – the most serious disputes live on. I plan to lay them bare.
If it’s assumed an evidential assessment of hypothesis H should take the form of a posterior probability of H – a form of probabilism – then P-values and confidence levels are applicable only through misinterpretation and mistranslation. Resigned to live with P-values, some are keen to show that construing them as posterior probabilities is not so bad (e.g., Greenland and Poole 2013). Others focus on long-run error control, but cede territory wherein probability captures the epistemological ground of statistical inference. Why assume significance levels and confidence levels lack an authentic epistemological function? I say they do [have one]: to secure and evaluate how well probed and how severely tested claims are.
Eclecticism and Ecumenism
If you look carefully between dense forest trees, you can distinguish unification country from lands of eclecticism (Cox 1978) and ecumenism (Box 1983), where tools first constructed by rival tribes are separate, and more or less equal (for different aims). Current-day eclecticisms have a long history – the dabbling in tools from competing statistical tribes has not been thought to pose serious challenges. For example, frequentist methods have long been employed to check or calibrate Bayesian methods (e.g., Box 1983); you might test your statistical model using a simple significance test, say, and then proceed to Bayesian updating. Others suggest scrutinizing a posterior probability or a likelihood ratio from an error probability standpoint. What this boils down to will depend on the notion of probability used. If a procedure frequently gives high probability for claim C even if C is false, severe testers deny convincing evidence has been provided, and never mind about the meaning of probability. One argument is that throwing different methods at a problem is all to the good, that it increases the chances that at least one will get it right. This may be so, provided one understands how to interpret competing answers. Using multiple methods is valuable when a shortcoming of one is rescued by a strength in another. For example, when randomized studies are used to expose the failure to replicate observational studies, there is a presumption that the former is capable of discerning problems with the latter. But what happens if one procedure fosters a goal that is not recognized or is even opposed by another? Members of rival tribes are free to sneak ammunition from a rival’s arsenal – but what if at the same time they denounce the rival method as useless or ineffective?
Decoupling. On the horizon is the idea that statistical methods may be decoupled from the philosophies in which they are traditionally couched. In an attempted meeting of the minds (Bayesian and error statistical), Andrew Gelman and Cosma Shalizi (2013) claim that “implicit in the best Bayesian practice is a stance that has much in common with the error-statistical approach of Mayo” (p. 10). In particular, Bayesian model checking, they say, uses statistics to satisfy Popperian criteria for severe tests. The idea of error statistical foundations for Bayesian tools is not as preposterous as it may seem. The concept of severe testing is sufficiently general to apply to any of the methods now in use. On the face of it, any inference, whether to the adequacy of a model or to a posterior probability, can be said to be warranted just to the extent that it has withstood severe testing. Where this will land us is still futuristic.
Why Our Journey?
We have all, or nearly all, moved past these old [Bayesian-frequentist] debates, yet our textbook explanations have not caught up with the eclecticism of statistical practice. (Kass 2011, p. 1)
When Kass proffers “a philosophy that matches contemporary attitudes,” he finds resistance to his big tent. Being hesitant to reopen wounds from old battles does not heal them. Distilling them in inoffensive terms just leads to the marshy swamp. Textbooks can’t “catch-up” by soft-peddling competing statistical accounts. They show up in the current problems of scientific integrity, irreproducibility, questionable research practices, and in the swirl of methodological reforms and guidelines that spin their way down from journals and reports.
From an elevated altitude we see how it occurs. Once high-profile failures of replication spread to biomedicine, and other “hard” sciences, the problem took on a new seriousness. Where does the new scrutiny look? By and large, it collects from the earlier social science “significance test controversy” and the traditional philosophies coupled to Bayesian and frequentist accounts, along with the newer Bayesian–frequentist unifications we just surveyed. This jungle has never been disentangled. No wonder leading reforms and semi-popular guidebooks contain misleading views about all these tools. No wonder we see the same fallacies that earlier reforms were designed to avoid, and even brand new ones. Let me be clear, I’m not speaking about flat-out howlers such as interpreting a P-value as a posterior probability. By and large, they are more subtle; you’ll want to reach your own position on them. It’s not a matter of switching your tribe, but excavating the roots of tribal warfare. To tell what’s true about them. I don’t mean understand them at the socio-psychological levels, although there’s a good story there (and I’ll leak some of the juicy parts during our travels).
How can we make progress when it is difficult even to tell what is true about the different methods of statistics? We must start afresh, taking responsibility to offer a new standpoint from which to interpret the cluster of tools around which there has been so much controversy. Only then can we alter and extend their limits. I admit that the statistical philosophy that girds our explorations is not out there ready-made; if it was, there would be no need for our holiday cruise. While there are plenty of giant shoulders on which we stand, we won’t be restricted by the pronouncements of any of the high and low priests, as sagacious as many of their words have been. In fact, we’ll brazenly question some of their most entrenched mantras. Grab on to the gondola, our balloon’s about to land.
In Tour II, I’ll give you a glimpse of the core behind statistics battles, with a firm promise to retrace the steps more slowly in later trips.
FOR ALL OF TOUR I: SIST Excursion 1 Tour I
THE FULL ITINERARY: Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars: SIST Itinerary
REFERENCES:
Berger, J. (2003). ‘Could Fisher, Jeffreys and Neyman Have Agreed on Testing?’ and ‘Rejoinder’, Statistical Science 18(1), 1–12; 28–32.
Box, G. (1983). ‘An Apology for Ecumenism in Statistics’, in Box, G., Leonard, T., and Wu, D. (eds.), Scientific Inference, Data Analysis, and Robustness, New York:
Academic Press, 51–84.
Cox, D. (1978). ‘Foundations of Statistical Inference: The Case for Eclecticism’, Australian Journal of Statistics 20(1), 43–59.
Efron, B. (2013). ‘A 250-Year Argument: Belief, Behavior, and the Bootstrap’, Bulletin of the American Mathematical Society 50(1), 126–46.
Fraser, D. (2011). ‘Is Bayes Posterior Just Quick and Dirty Confidence?’ and ‘Rejoinder’, Statistical Science 26(3), 299–316; 329–31.
Gelman, A. and Shalizi, C. (2013). ‘Philosophy and the Practice of Bayesian Statistics’ and ‘Rejoinder’, British Journal of Mathematical and Statistical Psychology 66(1), 8–38; 76–80.
Greenland, S. and Poole, C. (2013). ‘Living with P Values: Resurrecting a Bayesian Perspective on Frequentist Statistics’ and ‘Rejoinder: Living with Statistics in Observational Research’, Epidemiology 24(1), 62–8; 73–8.
Kadane, J. (2008). ‘Comment on Article by Gelman’, Bayesian Analysis 3(3), 455–8.
Kass, R. (2011). ‘Statistical Inference: The Big Picture (with discussion and rejoinder)’, Statistical Science 26(1), 1–20.
Mayo, D. (2003b). ‘Could Fisher, Jeffreys and Neyman Have Agreed on Testing? Commentary on J. Berger’s Fisher Address’, Statistical Science 18, 19–24.
Wasserman, L. (2012b). ‘What is Bayesian/Frequentist Inference?’, Blogpost on normaldeviate.wordpress.com (11/7/2012).


")


What has changed most dramatically, at least in the U.S., is the policy decision by the ASA in 2019 to put its foot on the scales and uphold a non-consensus position against error statistical methods and in favor of…well anything but, it seems. Its position wasn’t won by good arguments–in fact, the “alternative measures of evidence” that get its approval, or seem to, are not even critically appraised. It declares in its March 20 update (to the 2016 ASA Guide) that the concept of statistical significance should hereafter be abandoned, rejected, and the words “significance/significant” not be uttered. More than that, attaining or not attaining P-value thresholds should play no role “at all” in interpreting results. This, of course, is tantamount to disavowing testing and statistical falsification. I refer to the 2019 update as ASA II. For a discussion, see these posts:
https://errorstatistics.com/2019/06/17/the-2019-asa-guide-to-p-values-and-statistical-significance-dont-say-what-you-dont-mean-some-recommendations/
Another link to post: Bus or Bandwagon?
https://errorstatistics.com/2019/09/19/excerpts-from-p-value-thresholds-forfeit-at-your-peril-free-access-preprint/
Rick: Yes, I meant to include that post. By making the choice bus or bandwagon, the anti-error stat tribes ensure their pet positions won’t be examined–at least not now. Instead you’re enticed to joint the pop bandwagon which is negative: don’t say that, don’t do that, be popular. As Goodman says in an 2018 paper, sounding like one of our politicians, never waste a crisis. For decades, they couldn’t get their preferred tools accepted on grounds of argument or the properties of the tools. If we’re in Kuhnian non-normal science, “anything goes”. As Kuhn says, scientists aren’t trained for practice outside a paradigm, so in these cases, they behave like philosophers. This is in the preface of SIST. In 10 years or so, it will be clear how things went off the rails, however, people will still be doing back-door significance tests.