

.
Aris Spanos
Wilson Schmidt Professor of Economics
Department of Economics
Virginia Tech
The following guest post (link to updated PDF) was written in response to C. Hennig’s presentation at our Phil Stat Wars Forum on 18 February, 2021: “Testing With Models That Are Not True”.

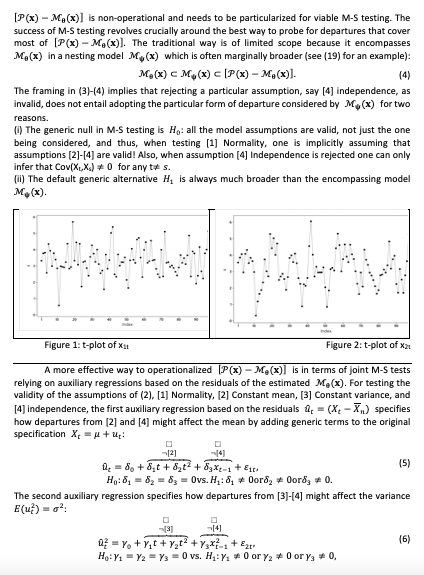









")


Great post, Aris. I’m curious about something, though: the relationship between these results (generally) and those that come from the study of algorithmic randomness.
From the AR perspective, a random sequence cannot be compressed. Thus random sequences cannot contain any regularities that could be used to formulate a model to predict it and thus compress it. The primary theorem in this field is (roughly) that there is no way to determine whether a given sequence is random.
The validation of a model in your post, though, seems to proceed by fitting a model and then checking to see whether the residuals are essentially random. But if algorithmic randomness applies, we can’t determine that.
I may be misrepresenting your work or failing to understand something important about the relationship between algorithmic and stochastic randomness, but I wonder if assumptions made regarding the size of the model class from which the data-generating model is drawn is doing the extra work, and whether those assumptions are typically justified in worldly applications. What do you think?
Thanks Tom. I appreciate your comment. The idea behind M-S testing is to establish that there is no lingering statistical systematic information (reflected by chance regularity patterns) in the residuals that are linked to departures from the probabilistic assumptions of the statistical model. That does not entail algorithmic randomness because the notion used for systematic information in M-S testing is that of a martingale difference process. In the case of the simple Normal and the Normal AR(1) is a Normal (second-order) martingale difference process. There is a relationship between algorithmic and stochastic randomness in the sense that the former is a generic form of randomness, and the latter is more specific and germane to the particular probabilistic assumptions of the underlying statistical model in question, and thus easier to evaluate using M-S testing.
ARis:
Thank you for this guest post spurred on by Hennig’s talk last Thursday. I think the key issue of disagreement with him concerns the “combined procedures” discussed in your post. I take your point to be that the combined procedure revolves around a fallacious use of M-S tests wherein, for example, a rejection of a null that asserts an assumption holds is taken to lead to a particular way in which it fails, and then, unsurprisingly, the overall error probability of the procedure no longer holds. This was one of the casualties I listed at the meeting.
I’ll respond later in more detail, however note that a “combined procedure” in my view is very general; it is any fully formalised sequence of tests that leads to an ultimate result, which then can be analysed. If one wants to use several tests to assess several model assumptions and allow for several different alternative models and methods (the term “alternative here referring to methods that require different and/or more general assumptions) depending on exactly which MS test says what, that would be a combined procedure as well albeit a more complex one than the ones I have used as simple examples.
Of course one can say there is an infinite range of possibilities how a model might be violated, and therefore what should be done can never be fully formalised, but in practice there’s only finite time and a finite range of things the data analyst can try out. If we’re talking about people who are not highly qualified and very experienced statisticians with enough time in their hands, it would be very optimistic to hope that they take into account more than two or three alternative models.
My casualties:
Here are some comments on casualties to get the discussion going.
A central focus of the statistics wars concern statistical significance testing, and some recommend banning them outright. A major casualty is that they’re a main way to check the statistical assumptions that are used across rival accounts.
Even Bayesians will turn to them— if they care to check their assumptions: Examples are George Box, Jim Berger, Andrew Gelman. (Described in some of the work by Hennig and Gelman.)
A second but related casualty comes out in the charge that since the statistical model used in testing is known to be wrong, there’s no point in testing a null hypothesis within that model. That’s dangerously confused and wrong. Remember the statistics debate that served as our October meeting? One of the debaters, editor (Basic and Applied Social Psychology), David Trafimow, gives this as the reason for banning p-value reports in published papers (though it’s OK to use them in the paper to get it accepted).
Here’s a quote from him:
“See, it’s tantamount to impossible that the model is correct, and so …you’re using the P-value to index evidence against a model that is already known to be wrong. … And so there’s no point in indexing evidence against it. “
But the statistical significance test is not testing whether the overall statistical model is wrong, and it is not indexing evidence against that model. It is only testing the null hypothesis (or test hypothesis) H0 within it. If the primary test is, say, about probability of success on each independent Bernouilli trial, it’s not also testing assumptions, say independence. Violated assumptions can lead to an incorrectly high, or an incorrectly low, P-value: P-values don’t “track” violated assumptions.
There are design based tests and model based tests In “design-based” tests, we look to experimental procedures, within our control, as with randomization, to get the assumptions to hold.
When we don’t have design-based assumptions, a standard way to check the assumptions is to get those checks to be independent of the unknowns in the primary test.
The secret of statistical significance tests that enable them to work so well is that running them only requires the distribution of the test statistic be known, at least approximately, under the assumption of H0 –whatever it is. It comes about as close to offering a direct falsification that one can hope for.
Given the assumptions the trials are like coin tossing (independent Bernouilli trials) I can deduce the probability of getting an even greater number of successes in a row, in n trials, than I observed, and so determine the p-value—where the null hypothesis is that the assumption of randomness holds.
What’s being done is often described as conditioning on the value of the sufficient statistic. (David Cox)
If you can’t do this, you’ve picked the wrong test statistic for the case at hand.
In some cases there is literally hold out data for checking but that’s different. The essence of the reasoning I’m talking about uses the “same” data but modelled differently.
It can be made out entirely informally. When the 2019 Eddington eclipse tests probed departures from the Newtonian predicted light deflection in testing the Einstein deflection, the tests—which were statistical– relied upon sufficient accuracy in the telescopes. Testing the distortions of the telescopes are done independently of the primary test of the deflection effect. In one famous case, thought to support Newton, it became clear after several months of analysis that the sun’s heat had systematically distorted the telescope mirror—the mirror had melted. No assumption about general relativity was required to infer that no adequate estimate of error for star positions was possible—only known star positions was required. That’s the essence of pinpointing blame for anomalies in primary testing.
If you can’t do this, you don’t have a test from which you can learn what’s intended—because you can’t distinguish if the observed phenomena is a real effect or noise in the data.
One other casualty is to declare: don’t test assumptions because you might do it badly. You might infer any of many possible ways to fix a model, upon finding evidence of violations.
Some of the examples Hennig gives are based on such a fallacy: replace the primary model by one where the error disappears. Maybe replace parameters in the model of gravity so it goes away—perhaps fiddle with the error term. Worse is if this depends on one of the rival gravity theories. That’s a disaster. There are many rival ways to save theories, and these error fixed hypotheses pass with very low severity. The proper inference only inferred you can’t use the data to reliably test the primary claim.
Looking for a decision routine on automatic pilot instead of piecemeal checking is very distant from good testing in science.
1/4 Introduction
Thanks to Aris Spanos for the detailed and well explained posting. There is much in it with which I agree; in particular I have no issue with the data analytic suggestions that are made. I will however focus on what I see differently. Spanos doesn’t make direct reference to what I said in my presentation, but if I take his section on “Combined Procedures” as a reply to it, it doesn’t represent appropriately the reasons why I am interested in analysing the performance of combined procedures.
It is important to note that I do not advocate a fully automated use of any specific combined procedure. Rather my aim (and the aim of the researchers who have already investigated combined procedures as cited in Shamsudheen and Hennig (2020)) is to investigate the characteristics (such as error probabilities) of what is actually done, being open minded about the results. Where MS testing is done before running a model-based test, MS testing has to be taken into account. This will ultimately allow to make statements about how to do MS testing more or less efficiently (as have been made in the literature since 1944 already, if in a somewhat patchy manner).
2/4 Analysing the performance characteristics of what is actually done
In order to understand why it makes a difference whether or not preliminary MS testing needs to be taken into account when analysing performance, it is important to remember that the error probabilities of model-based tests are derived from the full possible distribution of data to be observed, and this includes data that look “atypical” and can happen with low probability even if the assumed model is true.
Assume the researcher (called R in the following) wants to use a model that requires four model assumptions. Assume further R specifies four MS tests, one for each of the assumptions, and R will call a model “valid for the data” if it passes all four tests. If this is indeed the case, R carries out a test of a null hypothesis connected to a substantive hypothesis of interest. Regardless of whether and for what reasons R thinks that the MS tests do something essentially different from the final test, I’m asking what the performance characteristics (often error probabilities) are of what R is doing. In order to do this I need to specify a model for the true data generating function, which may be the one that the final test in fact assumes (modelling the case of correct specification), or a different one (modelling the case of misspecification).
Assuming that the model is specified correctly, if the four MS tests are all independent of the final test statistic, which is sometimes the case (see Spanos’s Sec. 1.2) but not always (for example bad leverage points in linear regression cannot be detected from the residuals alone), then conditionally on passing the four MS tests, the final test will have the same error probabilities as had it been run directly on the data without running MS tests before. However, this is not the full story. Assuming that R runs the MS tests at level 5%, and assuming (for the sake of making calculations simple) that they are independent, at least one MS test will reject the true model with overall probability of about 18.5%, in which case R will respecify the model in one way or another despite this not being required because the original model assumptions are in fact satisfied. How much of a problem is this? This depends on what exactly is done, which may depend on the specific MS test that rejected the model. In order to analyse this, it would be required to specify a protocol of what R will be doing in what case. This could even involve something like “ultimately no model is used because all tried out ones were invalid”; but if in reality a result is required to act upon, if this happens too often it can be seen as a weakness of the overall procedure. This defines what I call a combined procedure. Having a combined procedure defined, one can also analyse what happens if the model originally investigated is in fact misspecified and the data have been generated in a different way. In this case it may or may not happen that neither of R’s four MS tests detects the issue; again we’d need analysis of the combined procedure in order to find out how much of a problem that is. In principle R has all freedom for specifying the complete procedure. R can run several MS tests and respecify new models in flexible ways and then also test these (as Spanos suggests), as long as R decides the whole protocol in advance. This allows to analyse the overall quality of what is done, and without such a prespecification this is not possible.
A central issue that I have with Spanos’s approach is that it seems to me that in any real situation he in fact will make decisions to go on analysing data assuming the original model or using a different model, conditionally on an MS test rejecting the original one and potentially more tests later, but he apparently does not want that what is happening is analysed in a “decision-theoretic” way. Instead he argues that such a procedure “institutionalises the fallacies of rejection and acceptance” – still, in a real situation ultimately a decision will be made without having been able to rule out all possibilities how the finally used model could still be violated, because there is an infinite set of possible violations while there is only finite time, and because some violations of model assumptions cannot be detected (such as a constant correlation between Gaussian observations, see my presentation). The idea that we could ultimately, only doing enough MS testing, be safe to avoid using a model that can lead to misleading results, is wrong. This danger always exists, and my aim is to quantify, as far as possible, how likely that is and how severe the consequences are.
3/4 Flexibility vs. automation
An objection to the above could be that good and efficient model checking will also involve looking at visualisations, and that it is hardly possible to presepcify all possible model deviations that the data could show, and all possible models that one may want to fit to account for them. Fully formalised combined procedures inappropriately automate this process and are therefore prone to end up with invalid models.
I partly agree with this, however I think that both is needed: Fully flexible data analysis that allows a researcher to find model deviations and respecify models without the straightjacket of a fully automated approach, but also the analysis of a fully formalised approach as far as feasible.
In all likelihood a highly experienced and qualified statistician can apply flexibility in beneficial ways. Still there are at least two major reasons why fully formal approaches are important. Firstly, much statistical analysis is done by researchers who do not have the required degree of understanding and experience (in fact, as Spanos should know from his critical appreciation of the existing literature, even apparently qualified statisticians don’t always have all the required insight to do this well). Some of them know their limits, and precise guidelines what to do (as are given by a fully formalised combined procedure) are a frequent request for good reasons.
Secondly, only a fully formalised procedure allows to analyse its performance statistically. The quality of statistical procedures can only be convincingly established using mathematical theory and reproducible empirical experiments. These are only available for fully formalised procedures (some experiments regarding how human data analysts do data analyses “freely” exist, but as far as I know, results are all over the place). Following Spanos’s approach may result in good and successful data analysis, but as long as he doesn’t specify fully formally what he recommends to do, this cannot be empirically confirmed.
4/4 Benefits of simplification
It is true that the vast majority of literature investigating combined procedures (or parts of them) concentrates on “binary” situations, i.e., the choice between two different models and associated final tests by one MS test. This is obviously far from what Spanos recommends. But a full formalisation of his approach could be very tedious, if possible at all.
Surely it makes sense in mathematics and statistics to investigate the simpler things first when building up knowledge. Investigating a sophisticated programme involving, say, 9 different MS tests and 10 different models requires a lot of thought, and results may depend on all kinds of details. Neyman and Pearson started their work on optimal tests testing a point hypothesis against a point alternative not because this is most realistic or most relevant in pratice, but because this is the simplest case that allows to see clearly what kind of test is required and why. Mayo routinely uses situations with assumed known variance to demonstrate severity calculation, and the reason is surely not that she believes that known variances are the rule in reality.
Also in the framework of MS testing and combined procedures it is possible to find out things using simplified approaches. For example, when running a t-test, one can look at a situation where the true data generating process is i.i.d. but not necessarily normal to assess the performance of normality tests and combined procedures involving them, assuming that potential dependence and non-identity are already dealt with (which can also be investigated in an isolated manner). We have learnt a number of things from this, for example that there are many non-normal distributions under which running the t-test without prior normality testing works better than nonparametric alternatives or combined procedures involving normality tests, whereas on the other hand there are some models (mostly those generating gross outliers easily) under which the t-test loses power dramatically. Also this approach can demonstrate in what sense it is not a problem, if we assume a normal model, that data are actually discrete because of rounding or imprecise measurement. Technically this is a violation of the normality assumption, and an easy test can be defined that finds this violation with probability 1 (“reject normality if all data are rational”), however this violation is not relevant, because it can be shown that a combined procedure involving this test and pretty much any conceivable action in case of rejection would not perform better on such data than the plain t-test.
So I’m advocating the investigation of simplistic combined procedures, not because I believed that such procedures should be applied automatically in practice, but in order to learn about the building blocks of a more sophisticated approach, which may well follow Spanos’s recommendations. The major difference between Spanos and me is that Spanos seems to argue against taking such opportunities for learning.
Reference (references to earlier work can be found there):
Shamsudheen, M. I. and Hennig, C. (2020) Should we test the model assumptions before running a model-based test? arXiv:1908.02218.
Christian: Thank you so much for the extended comments. I should think you might favor the kind of approach to M-S testing favored by David Hendry, with whom Spanos has worked. Do you recall his paper from our 2010 conference on Statistical Science and Philosophy of Science?
Click to access hendry-rmm-article.pdf
I would very much like to know how your concerns relate to the Gelman Bayesian falsificationist approach. As I understand it, he will use a type of Bayesian p-value test to check the underlying model combined with the priors. All are tested at one time. One of the issues, of course, is how to distinguish flaws due to model violations from those due to the priors (I don’t know if “mistakes” can be used in talking about them, but I think Gelman thinks so). Does the overall posterior probability include the probability that the prior probability is “wrong”? What about the improved model which I take it he will substitute the original model with upon “falsification” using a Bayesian p-value. Will he consider the probability that this replacement model is wrong in the combined analysis?
You may be one of the only people who can explain this because (a) you’re sensitive to the issue and (b) you’ve done work with him. I haven’t been able to really get an answer from him (and you can tell from my treatment in my book, SIST, that I’m unclear), but I’m fairly sure he will not try to compute an overall posterior–but correct me if I’m wrong. Still the question is, what can be said about the overall error probability of the Bayesian falsificationist inference? Does it even receive an error statistical assessment?
I’d be very grateful to get clear on this.
Gelman explains things in quite some detail here:
Click to access bdachapter6.pdf
It’s not true that “all are tested at one time”. In fact the attitude is similar to Aris’s in that respect. Various test statistics can test various aspects of the model. There are specific tests for specific aspects of the sampling model such as independence; sometimes this can be separated from aspects of the prior, sometimes not so well. It depends on the details of the model. Graphical methods are also advocated.
Regarding the possibility to analyse this as combined procedure, there is even less clear guidance than Aris gives (actually Aris has some quite clear guidance if not going as far as full formalisation). So all my concerns apply there just as well (I don’t think Gelman would object against this kind of analysis but I haven’t checked that with him). Actually, while this is done in frequentist statistics since 1944, I’m not sure anything of this kind has been done yet for Bayesian analysis. What Gelman advocates is more recent and runs against how some interpret Bayesian statistics. If I had a huge research group for such things I would put half of them on the Bayesian case. Surely there’s a rich potential for research, as there is in frequentism (although many Bayesians won’t like it so it may be hard to publish it; I’d have thought that it’d be easier for frequentist work in this spirit but we have big difficulties to get this accepted – some frequentists clearly don’t like this either). Maybe there’s even more potential because the prior adds complexity. One reason why this is not done for the Bayesian case is that much of Gelman’s own work is non-routine in the sense of using new and complex models all the time. This probably makes people think less about how a routine procedure for, for example, a one dimensional two sample comparision could look like, and then to analyse it. I don’t know much of his regression book, maybe that has some more routine examples.
Ultimately there’s the same “flexibility vs. automation” issue here that I have discussed above. By the way I forgot to mention in that section that full formalisation/”automation” is a kind of pre-registration and will also support replicability.