

.
Aris Spanos
Wilson Schmidt Professor of Economics
Department of Economics
Virginia Tech
The following guest post (link to PDF of this post) was written as a comment to Mayo’s recent post: “Abandon Statistical Significance and Bayesian Epistemology: some troubles in philosophy v3“.
On Frequentist Testing: revisiting widely held confusions and misinterpretations
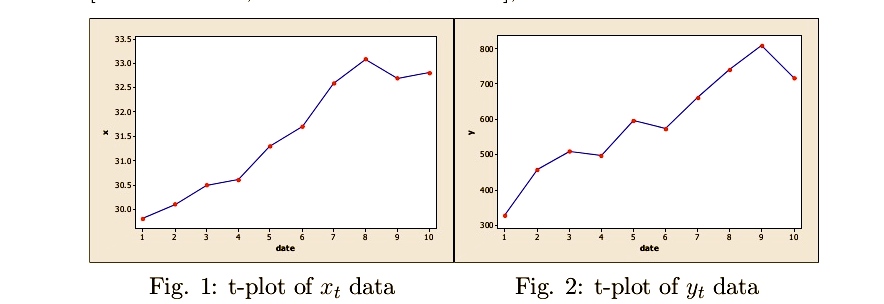
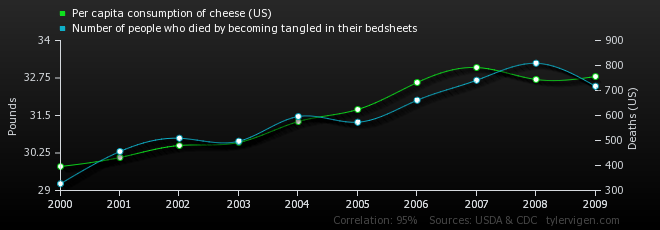
After reading chapter 13.2 of the 2022 book Fundamentals of Bayesian Epistemology 2: Arguments, Challenges, Alternatives, by Michael G. Titelbaum, I decided to write a few comments relating to his discussion in an attempt to delineate certain key concepts in frequentist testing with a view to shed light on several long-standing confusions and misinterpretations of these testing procedures. The key concepts include ‘what is a frequentist test’, ‘what is a test statistic and how it is chosen’, and ‘how the hypotheses of interest are framed’. Continue reading












")

