
.
From what standpoint should we approach the statistics wars? That’s the question from which I launched my presentation at the Statistics Wars and Their Casualties workshop (phil-stat-wars.com). In my view, it should be, not from the standpoint of technical disputes, but from the non-technical standpoint of the skeptical consumer of statistics (see my slides here). What should we do now as regards the controversies and conundrums growing out of the statistics wars? We should not leave off the discussions of our workshop without at least sketching a future program for answering this question. We still have 2 more sessions, December 1 and 8, but I want to prepare us for the final discussions which should look beyond a single workshop. (The slides and videos from the presenters in Sessions 1 and 2 can be found here.)
I will consider three, interrelated, responsibilities and tasks that we can undertake as statistical activist citizens. In so doing I will refer to presentations from the workshop, limiting myself to session #1. (I will add more examples in part (ii) of this post.)
1. Keep alert to ongoing evidence policy “reforms”. Scrutinize attempts to replace designs and methods that ensure error control with alternatives that actually make it harder to achieve error control. Be on the lookout for methods that presuppose a principle of evidence where error probabilities drop out–the Likelihood Principle. While they’re unlikely to be described that way, ask journals/ authors etc. directly if the LP is being presupposed. Write letters to editors asking how the proposed change in method benefits (rather than hurts) the skeptical statistical consumer.
In slide #64 of my presentation, I proposed that in the context of the skeptical consumer of statistics, methods should be:
-directly altered by biasing selection effects
-able to falsify claims statistically,
-able to test statistical model assumptions.
-able to block inferences that violate minimal severity
If someone is trying to sell you a reform where any of these are lacking, you might wish to hold off buying.
In reacting to proposed Bayesian replacements for error statistical methods, ask how they are arrived at, what they mean, and how to check them. Here’s a slide (#22) from Stephen Senn on the various types of Bayesian approaches (Slides from Senn presentation)
2. Reject the howlers and caricatures of error statistical methods that are the basis of the vast majority of criticisms against them. Typical examples are claims that either P-values must be misinterpreted as posterior probabilities or else they are irrelevant for science. Resist popular mantras that error statistical control is only relevant to ensure ‘quality control’, apt for such contexts as needing to avoid the acceptance of a batch of bolts with too high a proportion of defectives, but not for science. The supposition that the choice is either “belief or performance” is to commit a false dilemma fallacy. Admittedly what is still needed is a clear articulation of uses of error statistical methods that reflect what Cox, E. Pearson, Birnbaum, Giere (and others, including Mayo) dub the “evidential” vs the “behavioristic” uses of tests. Scientists use error statistical tests to appraise, develop, and answer questions about theories and models (e.g., could the observed effect readily be due to sampling variability? could the data have been generated by a process approximately represented by model M? Is the data-model fit ‘too good to be true?”).
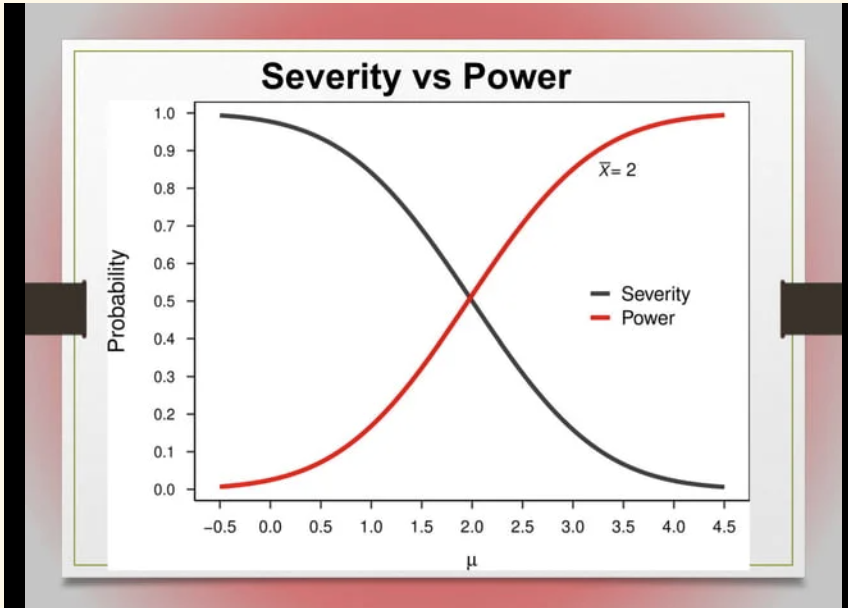
By the way, founders of error statistical methods never claimed low Type I and 2 error probabilities suffice for warranted inference. Observe that a statistically significant result inseverely passes an alternative H’ against which a test has high power. (Mayo, slide #50):
3. No preferential treatment for one methodology or philosophy. Developing author and journal guidelines for avoiding problematic uses of Bayesian (and other) methods is long overdue. In many journals, authors are warned to avoid classic fallacies of statistical significance: statistical significance is not substantive importance; P-values aren’t effect size measures; a nonstatistically significant difference isn’t evidence of no difference; a P-value is not a posterior probability of H0; biasing selection effects (cherry picking, optional stopping, multiple testing, etc.) can alter a method’s error probabilities. Have you ever seen guidelines that alert authors to fallacies of methods that are recommended as replacements to statistical significance tests? (Let me know if you have.) It’s time.[0]
Let’s focus here on one of the rivals that arose in several presentations: Bayes factors (BFs).[1] We can begin with the uses to which they are routinely put, especially in the service of critiques of statistical significance tests. BFs do not satisfy the 4 requirements I list at the outset. Two main problems arise.
Problem #1: High probability of erroneous claims of evidence against a hypothesis H0. Because error probabilities drop out of Bayes factors, the ability to control them goes by the wayside. Stat activists should uncover how biasing selection effects (e.g., multiple testing, data-dredging, optional stopping) might adversely affect a method’s ability to have uncovered mistaken interpretations of data. A part of what I have in mind is an active research area in genomics, machine learning (ML) and big data science under terms such as ‘post data selective inference’. The skeptical statistical consumer should be aware of how data dependent methods can succeed or badly fail in some of the ML algorithms that affect them in medical, legal, and a host of social policies.
One of many well-known examples involves optional stopping in the context of a type of example the BF advocate often recommends—two-sided testing of the mean of a Normal distribution.[2] This example “is enough to refute the strong likelihood principle” (Cox 1978, p. 54), since, with high probability, it will stop with a “nominally” significant result even though the point null hypothesis is true. It contradicts what Cox and Hinkley call “the weak repeated sampling principle” (See SIST 2018, p. 45 or Mayo slides).
Inference by Bayes theorem entails the LP, so either one accepts error probability control or accepts Bayesian “incoherence”.
Interestingly, Richard Morey, a leading developer of BFs, also focused his presentation on how BFs preclude satisfying error statistical severity. But he does not look at false rejections due to biasing selection effects. Rather, Morey shows that BFs allow erroneously accepting hypothesis H0 with high probability (see Morey slides here). Call this problem #2.
Problem #2: Even a statistically significant difference from H0—a low P-value—can, according to a BF computation, become evidence in favor of H0 by assigning it a high enough prior degree of belief, especially coupled with a suitable choice of alternative.[3] See Morey’s conclusions in his slides.

What needs to be done: If a BF purports to supply evidence for a point null, compute, as does Morey, the probability the assignments used would find as much or even more evidence for H0 as it does, even though in fact there’s a discrepancy δ of from H0, for δ a discrepancy of interest (a substantive issue). That is, compute the probability of a Type 2 error in relation to alternatives of form: there’s a discrepancy at least δ from H0. Simple apps can be given for computing this (a twist on Morey’s own severity app would do). If this error probability is not low, then not only should you reject the inference to point hypothesis H0, even a claim that any discrepancy from H0 is less than δ (whether 1 or 2-sided) is unwarranted. Other analogous ways can and have been developed to critically evaluate inferences based on BFs.That is what an adequate meta-methodology demands from the standpoint of the skeptical critical consumer of statistics.
Morey begins by remarking that he himself has developed popular methods for computing BFs, so it is especially meaningful that he concedes their inability to sustain severity. He does an excellent job. One thing the skeptical statistical consumer will want to know is whether Morey alerts the user to these consequences. The user needs to see precisely what he so clearly shows us in his presentation: applying the defaults can have seriously problematic error statistical consequences. If he hasn’t already, I propose Morey include examples of this in his next BF computer package.[4]
The bottom line is: we need to erect guidelines to ward off the bad statistics that can easily result from rivals to error statistical methods, and encourage journals to include such guidelines, especially now that these alternatives are becoming so prevalent. That a method is Bayesian should not make it above reproach, as if it’s a protected class.[5]
——–
[0] In the open discussion in Session 1, Mark Burgman, editor of Conservation Biology, seemed surprised at my suggestion that he add to the guidelines in his journal caveats directed at methods other than statistical significance tests and P-values, including confidence intervals and Bayes factors. I am surprised at his surprise (but perhaps I misunderstood his reaction.)
[1] As I say in my presentation, there are other goals in statistics. We are not always trying to critically probe what is the case. In some contexts, we might merely be developing hypotheses and models for subsequent severe probing. However, it’s important to see that even weaker claims such as “this model is worth probing further” need to be probed with reasonable severity. Severity provides a minimal requirement of evidence for any type of claim, in other words. Moreover, I should note, there are Bayesians who reject BFs and criticize the spiked priors to point null hypotheses. Their objections should be part of the remedy for problem #2. “To me, Bayes factors correspond to a discrete view of the world, in which we must choose between models A, B, or C” (Gelman 2011, p. 74) or a weighted average of them as in Madigan and Raftery (1994).
[2] The error statistical tester, but also some Bayesians, eschew these two-sided tests as artificial—particularly when paired with the lump of prior placed on the point null hypothesis. However, they are the mainstay of the examples currently relied on in launching criticisms of statistical significance tests.
[3] Strictly speaking, BFs do not supply evidence for or against hypotheses—they are only comparative claims, e.g., the data support or fit one hypothesis or model better than another. Morey speaks of “accepting H0”, and that is entirely in sync with the way BF advocates purport to use BFs—namely as tests. Ironically, while BF enthusiasts (like Likelihoodists) are one in criticizing P-values because they are not comparative (and thus, according to them, cannot supply evidence), BF advocates strive to turn their own comparative accounts into tests, by allowing values of the BF to count as accepting or rejecting statistical hypotheses. The trouble is that it is often forgotten that they were really only entitled to a comparative claim. Construed as tests, error probabilities can be high. Moreover, as Morey points out, both claims under comparison can be terribly warranted. Moreover, the value of the BF—essentially a likelihood ratio—doesn’t mean the same thing in different contexts, especially if hypotheses are data dependent. As Morey points out, for the BF advocate, the value of the BF is the evidence measure, whereas for error statisticians, such “fit” measures only function as statistics to which we would need to attach a sampling distribution. By contrast sampling distributions are rejected as irrelevant post data by the BF advocate.
[4] Such consequences are often hidden by Bayesians behind the cover of: we are warranted in a high spiked prior degree of belief in H0 because nature is “simple” or we are “conservative”. The former is a presumed metaphysics, not evidence. As for the latter, consider where the null hypothesis asserts “no serious toxicity exists”. Assigning H0 a high prior is quite the opposite of taking precautions.[4] Even if one would be correct to doubt the existence of the effect, that is very different from having evidential reasons for this. One may reject the effect for the wrong reasons.
[5] All slides and videos from Sessions 1 and 2 can be found on this post.


")

