
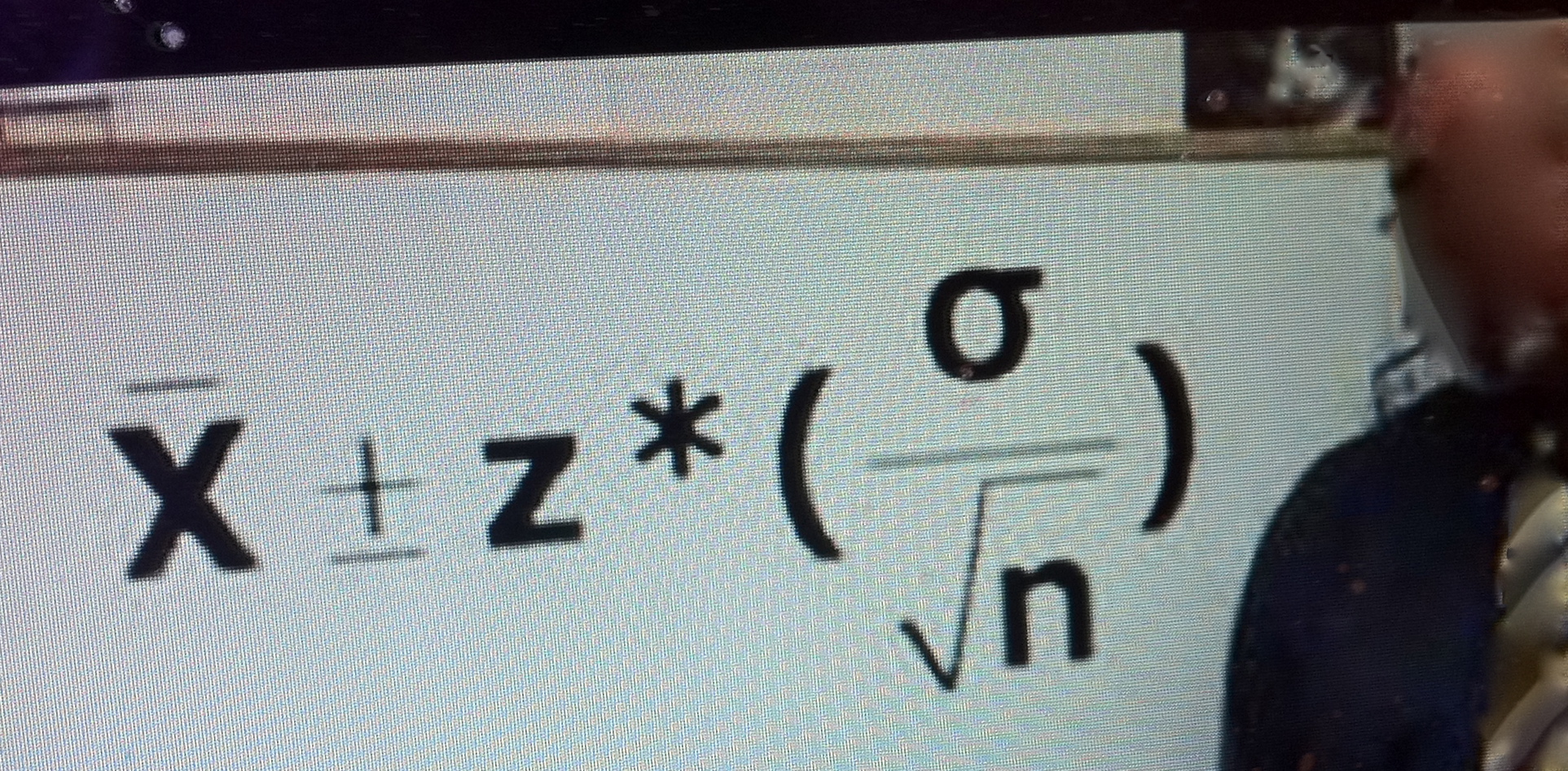 A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer:
A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer:
Consider our favorite test of the mean of a Normal distribution with n iid samples, and known standard deviation σ: test T+. This time let:
H0: µ ≤ 0 against H1: µ > 0 , and let σ= 1.
Nothing of interest to the logic changes if s.d. is estimated as is more typical. If σ = 1, n = 25, (σ/ √n) = .2.
The (1 – α) confidence interval (CI) corresponding to test T+ is that µ > the (1 – α) LL:
µ > M – ca(1/ √n ).
where M represents the statistic, usually written X-bar, the sample mean. For example,
M – 2.5(1/ √n )
is the generic lower limit (LL) of a 99% CI. The impressive thing is that this holds regardless of the true value of µ. If, for any M you assert:
µ > M – ca(1/ √n ),
your assertions will be correct 99% of the time. [Once the data are in hand, M takes the value of a particular sample mean. Without quantifiers, this is a little imprecise.]
Now for the duality between CIs and tests. How does it work?
Put aside for the moment our fixed hypothesis of interest; just retain the form of test T+. Keeping the s.d. of 1, and n = 25, suppose we have observed M = .6.
Consider the question: For what value of µ0 would M = .6 be the 2.5 s.d. cut-off (in test T+)? That is, for what value of µ0 would an observed mean of .6 exceed µ0 by 2.5 s.d.s? (Or again, for what value of µ0 would our observation reach a p-value of .01 in test T+?)
Clearly, the answer is in testing H0: µ ≤ .1 against H1: µ > .1.
The corresponding .99 lower limit of the one-sided confidence interval would be:
[.1 < µ , infinity]
The duality with tests says that these are the µ values (in the given model and test) that would not be statistically significant at the .01 level, had they been the ones tested in T+. For example:
H0: µ ≤ .15 would not be rejected, nor would H0: µ ≤ .2, H0: µ ≤ .25 and so on. That’s because the observed M is not statistically significantly greater (at the .01 level) than any of the µ values in the interval. Since this is continuous, it does not matter if the cut-off is just at .1 or values greater than .1.
On the other hand, a test hypothesis of H0: µ ≤ .09 would be rejected by M = .6; as would µ ≤ .08, µ ≤ .07…. H0: µ ≤ 0, and so on. Using significance test language again, the observed M is statistically significantly greater than all these values (p-level smaller than .01), and at smaller and smaller levels of significance.
Under the supposition that the data were generated from a world where H0: µ ≤ .1 against µ >.1, at least 99% of the time a larger M than was observed would occur.
The test was so incapable of having produced so large a value of M as .6, were µ less than the 99% CI lower bound, that we argue there is an indication (if not full blown evidence) that µ > .1.
We are assuming these values are “audited”, and the assumptions of the model permit the computations to be approximately valid. Following Fisher, evidence of an experimental effect requires more than a single, isolated significant result, but let us say that is satisfied.
The severity with which µ > .1 “passes” the test with this result M = .6 (in test T+) is ~ .99.
SEV( µ > .1, test T+, M = .6) = P(M < .6; µ =.1) = P( Z < (.6 – .1)/.2)=
P(Z < 2.5) = .99.
Here’s a little chart for this example:
Duality between LL of 1-sided confidence intervals and a fixed outcome M = .6 of test T+: H0: µ ≤ µ0 vs H1: µ > µ0. σ = 1, n = 25, (σ/ √n) = .2. These computations are approximate.
| Were µ no greater than | The capability of T+ to produce M as large as .6 is _ | µ is the 1-sided LL with level _ | Claim C | SEV associated with C |
| .1 | .01 | .99 | (µ > .1) | .99 |
| .2 | .025 | .975 | (µ > .2) | .975 |
| .3 | .07 | .93 | (µ > .3) | .93 |
| .4 | .16 | .84 | (µ > .4) | .84 |
| .5 | .3 | .7 | (µ > .5) | .7 |
| .6 | .5 | .5 | (µ > .6) | .5 |
| .7 | .69 | .31 | (µ > .7) | .31 |
In all these cases, the test had fairly low capability to produce M as large at .6–the largest it gets is .69. I’ll consider what the test is more capable of doing in another post. Note that: as the capability increases, the corresponding confidence level decreases.


")

