

.
This was initially posted as slides from our joint Spring 2014 seminar: “Talking Back to the Critics Using Error Statistics”. (You can enlarge them.) Related reading is Mayo and Spanos (2011)

.
This was initially posted as slides from our joint Spring 2014 seminar: “Talking Back to the Critics Using Error Statistics”. (You can enlarge them.) Related reading is Mayo and Spanos (2011)

At the start of our seminar, I said that “on weekends this spring (in connection with Phil 6334, but not limited to seminar participants) I will post some of my ‘deconstructions‘ of articles”. I began with Andrew Gelman‘s note “Ethics and the statistical use of prior information”[i], but never posted my deconstruction of it. So since it’s Saturday night, and the seminar is just ending, here it is, along with related links to Stat and ESP research (including me, Jack Good, Persi Diaconis and Pat Suppes). Please share comments especially in relation to current day ESP research. Continue reading
Aris Spanos’ overview of error statistical responses to familiar criticisms of statistical tests. Related reading is Mayo and Spanos (2011)

 S. Stanley Young, PhD
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
Here are Dr. Stanley Young’s slides from our April 25 seminar. They contain several tips for unearthing deception by fraudulent p-value reports. Since it’s Saturday night, you might wish to perform an experiment with three 10-sided dice*,recording the results of 100 rolls (3 at a time) on the form on slide 13. An entry, e.g., (0,1,3) becomes an imaginary p-value of .013 associated with the type of tumor, male-female, old-young. You report only hypotheses whose null is rejected at a “p-value” less than .05. Forward your results to me for publication in a peer-reviewed journal.
*Sets of 10-sided dice will be offered as a palindrome prize beginning in May.
We are pleased to announce our guest speaker at Thursday’s seminar (April 24, 2014): “Statistics and Scientific Integrity”:
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
Author of Resampling-Based Multiple Testing, Westfall and Young (1993) Wiley.

The main readings for the discussion are:
 We interspersed key issues from the reading for this session (from Howson and Urbach) with portions of my presentation at the Boston Colloquium (Feb, 2014): Revisiting the Foundations of Statistics in the Era of Big Data: Scaling Up to Meet the Challenge. (Slides below)*.
We interspersed key issues from the reading for this session (from Howson and Urbach) with portions of my presentation at the Boston Colloquium (Feb, 2014): Revisiting the Foundations of Statistics in the Era of Big Data: Scaling Up to Meet the Challenge. (Slides below)*.
Someone sent us a recording (mp3)of the panel discussion from that Colloquium (there’s a lot on “big data” and its politics) including: Mayo, Xiao-Li Meng (Harvard), Kent Staley (St. Louis), and Mark van der Laan (Berkeley).
See if this works: | mp3
*There’s a prelude here to our visitor on April 24: Professor Stanley Young from the National Institute of Statistical Sciences.
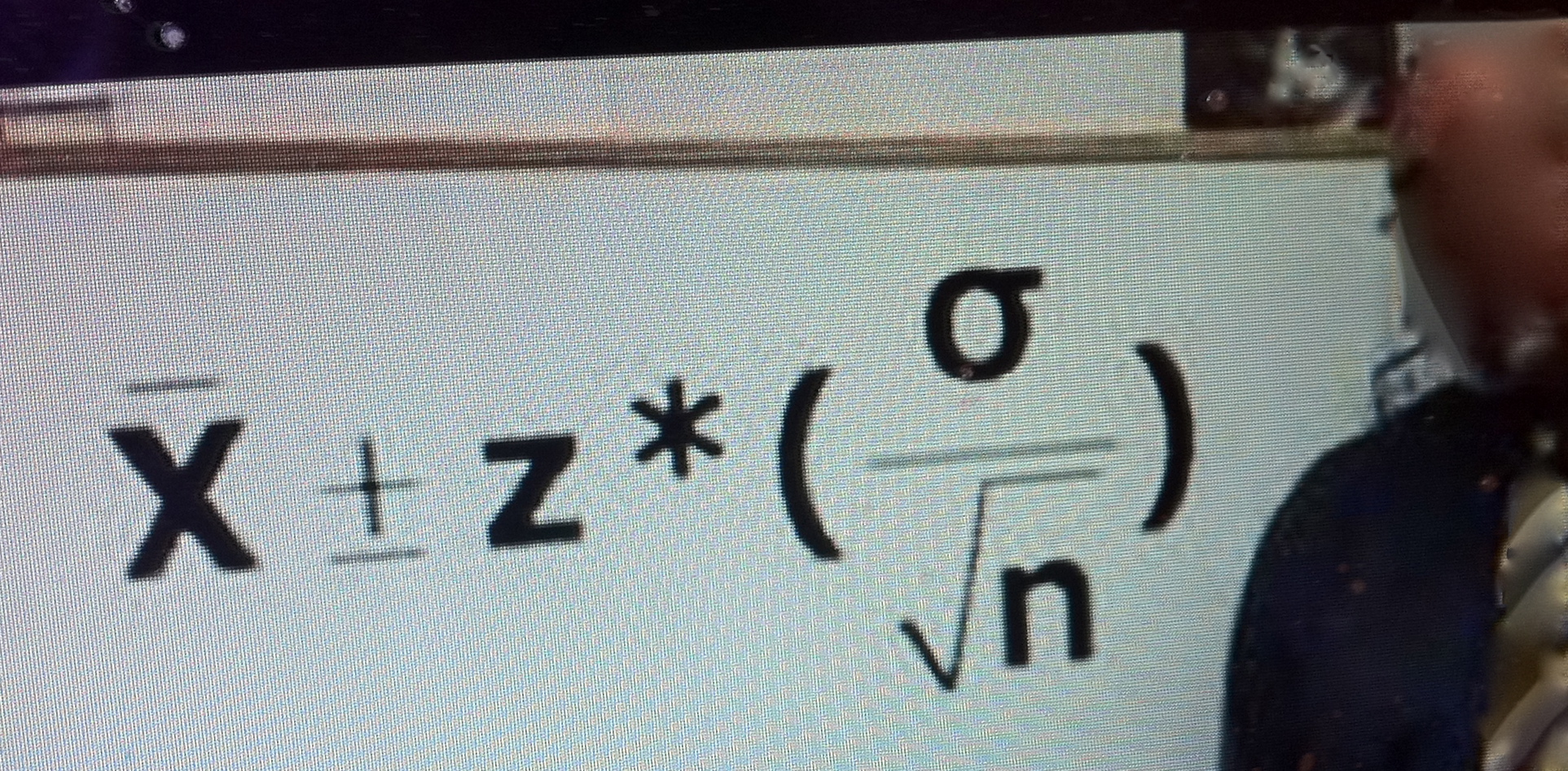 A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer: Continue reading
A question came up in our seminar today about how to understand the duality between a simple one-sided test and a lower limit (LL) of a corresponding 1-sided confidence interval estimate. This is also a good route to SEV (i.e., severity). Here’s a quick answer: Continue reading
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Central Identification Laboratory
JPAC
Guest, March 27, PHil 6334
“Statistical Considerations of the Histomorphometric Test Protocol for Determination of Human Origin of Skeletal Remains”
By:
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Maria-Teresa Tersigni-Tarrant, Ph.D.
Central Identification Laboratory
JPAC
.
We spent the first half of Thursday’s seminar discussing the Fisher, Neyman, and E. Pearson “triad”[i]. So, since it’s Saturday night, join me in rereading for the nth time these three very short articles. The key issues were: error of the second kind, behavioristic vs evidential interpretations, and Fisher’s mysterious fiducial intervals. Although we often hear exaggerated accounts of the differences in the Fisherian vs Neyman-Pearson (NP) methodology, in fact, N-P were simply providing Fisher’s tests with a logical ground (even though other foundations for tests are still possible), and Fisher welcomed this gladly. Notably, with the single null hypothesis, N-P showed that it was possible to have tests where the probability of rejecting the null when true exceeded the probability of rejecting it when false. Hacking called such tests “worse than useless”, and N-P develop a theory of testing that avoids such problems. Statistical journalists who report on the alleged “inconsistent hybrid” (a term popularized by Gigerenzer) should recognize the extent to which the apparent disagreements on method reflect professional squabbling between Fisher and Neyman after 1935 [A recent example is a Nature article by R. Nuzzo in ii below]. The two types of tests are best seen as asking different questions in different contexts. They both follow error-statistical reasoning. Continue reading
 Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.
Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.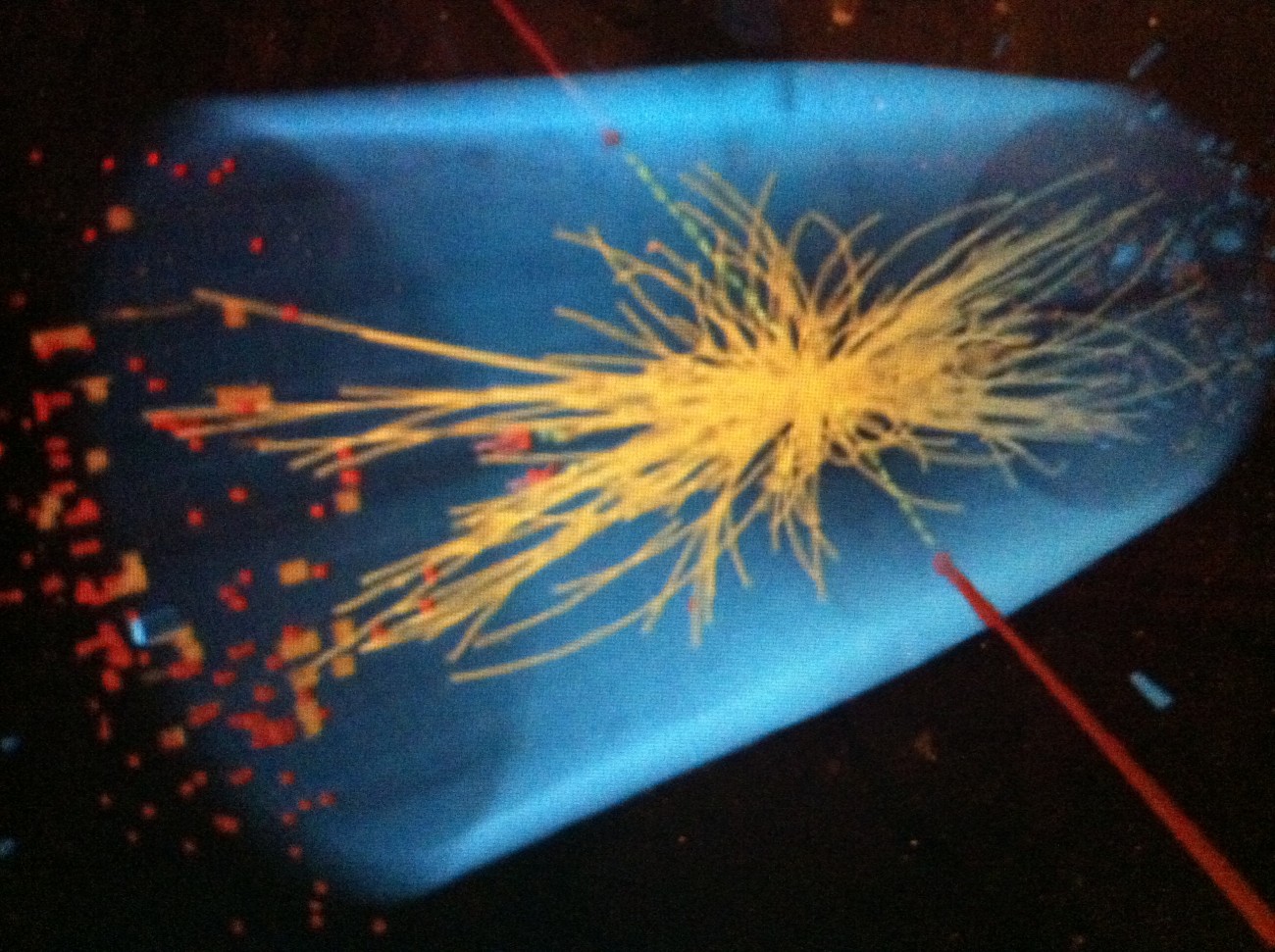
We spent the rest of the seminar computing significance levels, rejection regions, and power (by hand and with the Excel program). Here is the updated syllabus (3rd installment).
A relevant paper on selection effects on this blog is here.
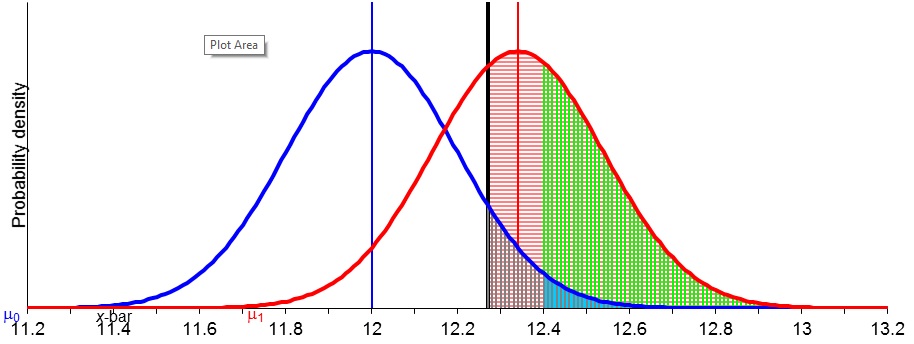
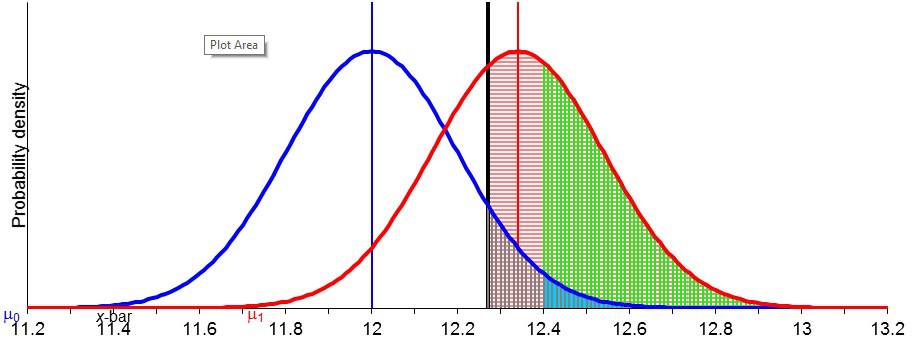 Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
[i]I was tempted to say power is one of the “most powerful” notions.It is.True, severity leads us to look, not at the cut-off for rejection (as with power) but the actual observed value, or observed p-value. But the reasoning is the same. Likewise for less artificial cases where the standard deviation has to be estimated. See Mayo and Spanos 2006.
[ii]
You can find a link to the Severity Excel Program (from which the pictures came) on the left hand column of this blog, and a link to basic instructions.This corresponds to EXAMPLE SET 1 pdf for Phil 6334.
Howson, C. and P. Urbach (2006). Scientific Reasoning: The Bayesian Approach. La Salle, Il: Open Court.
Mayo, D. G. and A. Spanos (2006) “Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction“ British Journal of Philosophy of Science, 57: 323-357.
Morrison and Henkel (1970), The significance Test controversy.
Ziliak, Z. and McCloskey, D. (2008), The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice and Lives, University of Michigan Press.
 PHIL 6334 – “Probability/Statistics Lecture Notes 3 for 2/20/14: Estimation (Point and Interval)”:(Prof. Spanos)*
PHIL 6334 – “Probability/Statistics Lecture Notes 3 for 2/20/14: Estimation (Point and Interval)”:(Prof. Spanos)*
*This is Day #5 on the Syllabus, as Day #4 had to be made up (Feb 24, 2014) due to snow. Slides for Day #4 will go up Feb. 26, 2014. (See the revised Syllabus Second Installment.)

Statistical Snow Sculpture
No Seminar. Blizzard.

")

Experts convene to explore new philosophy of statistics field


Power taboos: Statue of Liberty, Senn, Neyman, Carnap, Severity
My fire alarm analogy is here. My analogy presumes you are assessing the situation (about the fire) long distance. Continue reading →