 The one method that enjoys the approbation of the New Reformers is that of confidence intervals. The general recommended interpretation is essentially this:
The one method that enjoys the approbation of the New Reformers is that of confidence intervals. The general recommended interpretation is essentially this:
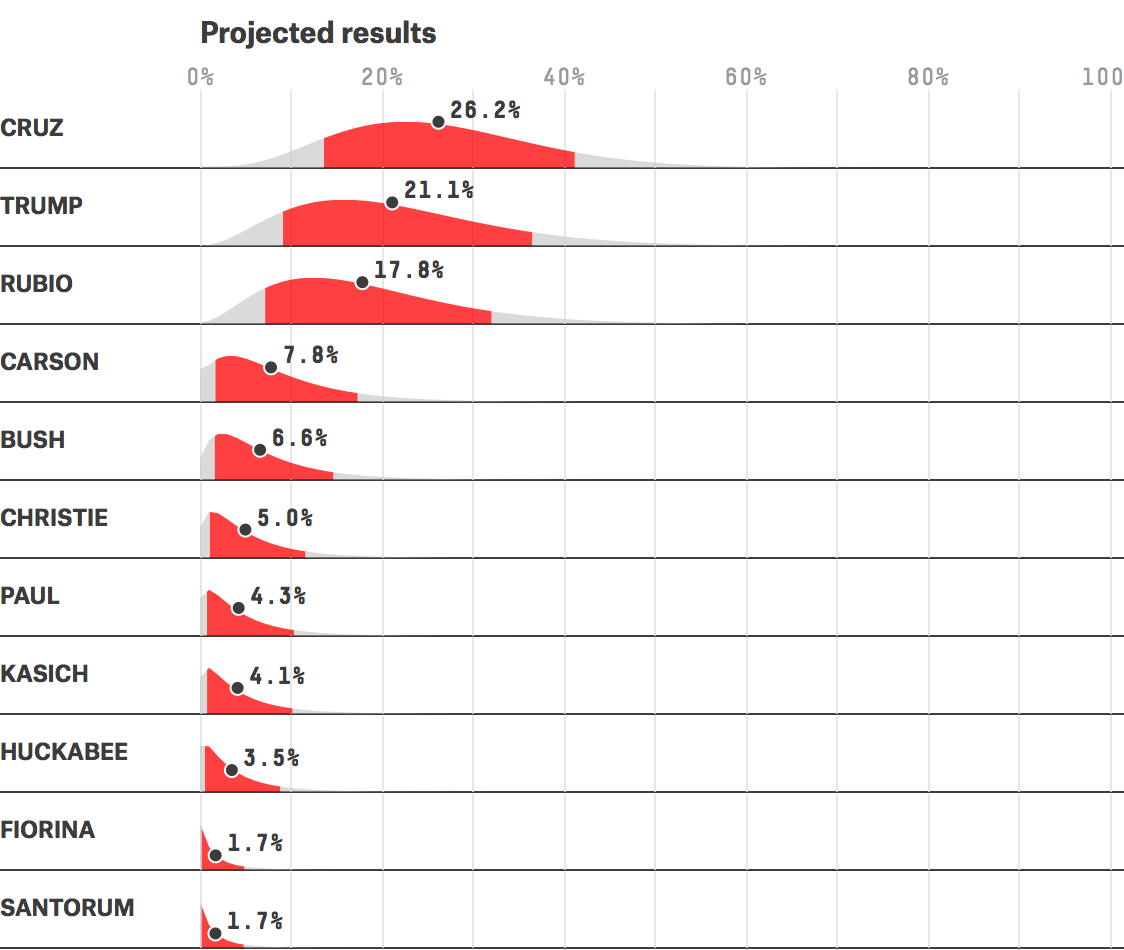
For a reasonably high choice of confidence level, say .95 or .99, values of µ within the observed interval are plausible, those outside implausible.
Geoff Cumming, a leading statistical reformer in psychology, has long been pressing for ousting significance tests (or NHST[1]) in favor of CIs. The level of confidence “specifies how confident we can be that our CI includes the population parameter m (Cumming 2012, p.69). He recommends prespecified confidence levels .9, .95 or .99:
“We can say we’re 95% confident our one-sided interval includes the true value. We can say the lower limit (LL) of the one-sided CI…is a likely lower bound for the true value, meaning that for 5% of replications the LL will exceed the true value. “ (Cumming 2012, p. 112)[2]
For simplicity, I will use the 2-standard deviation cut-off corresponding to the one-sided confidence level of ~.98.
However, there is a duality between tests and intervals (the intervals containing the parameter values not rejected at the corresponding level with the given data).[3]
“One-sided CIs are analogous to one-tailed tests but, as usual, the estimation approach is better.”
Is it? Consider a one-sided test of the mean of a Normal distribution with n iid samples, and known standard deviation σ, call it test T+.
H0: µ ≤ 0 against H1: µ > 0 , and let σ= 1.
Test T+ at significance level .02 is analogous to forming the one-sided (lower) 98% confidence interval:
µ > M – 2(1/ √n ).
where M, following Cumming, is the sample mean (thereby avoiding those x-bars). M – 2(1/ √n ) is the lower limit (LL) of a 98% CI.
Central problems with significance tests (whether of the N-P or Fisherian variety) include:
(1) results are too dichotomous (e.g., significant at a pre-set level or not);
(2) two equally statistically significant results but from tests with different sample sizes are reported in the same way (whereas the larger the sample size the smaller the discrepancy the test is able to detect);
(3) significance levels (even observed p-values) fail to indicate the extent of the effect or discrepancy (in the case of test T+ , in the positive direction).
We would like to know for what values of δ it is warranted to infer µ > µ0 + δ. Continue reading →












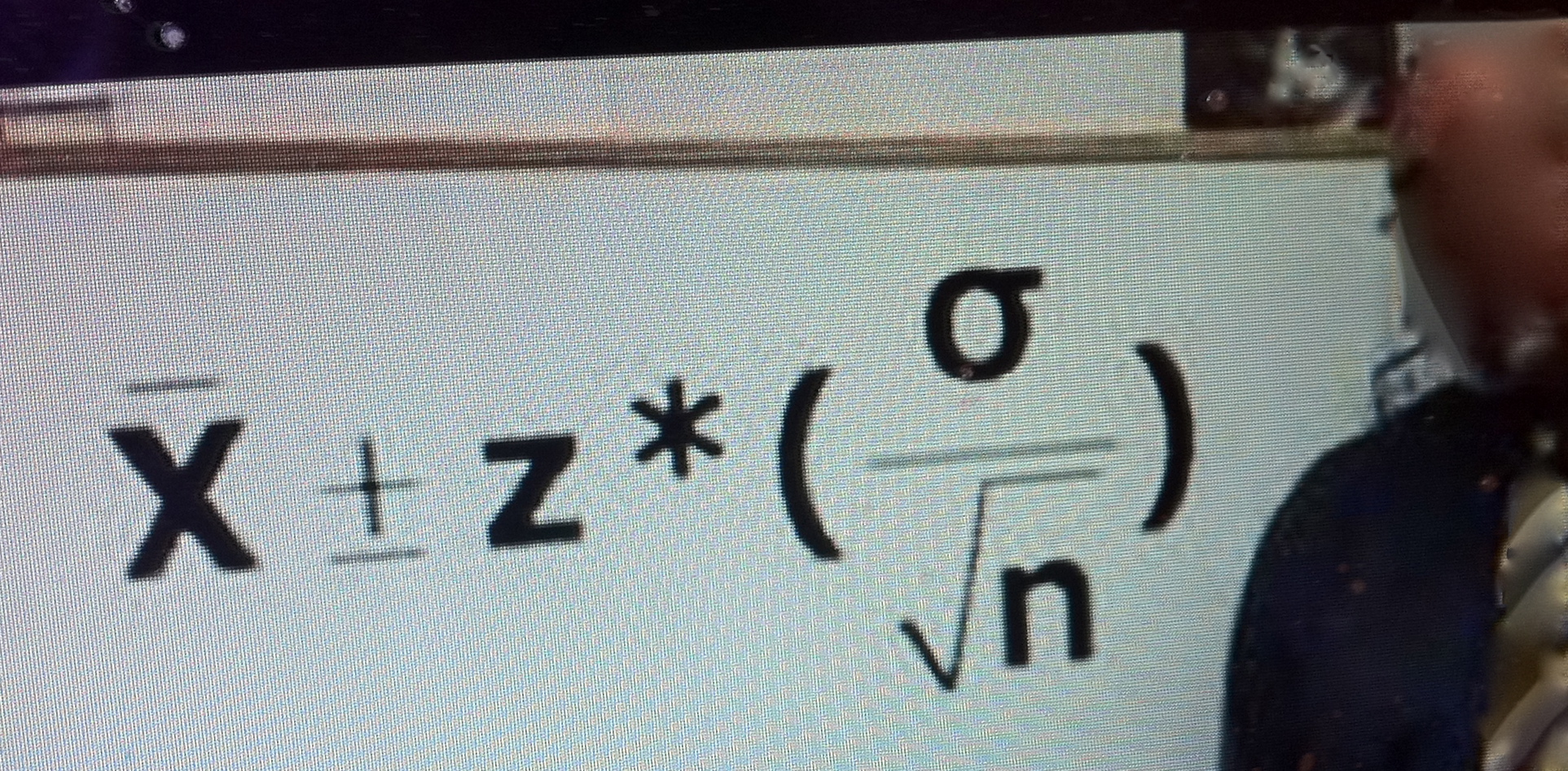



")

