
 I resume my comments on the contributions to our symposium on Philosophy of Statistics at the Philosophy of Science Association. My earlier comment was on Gerd Gigerenzer’s talk. I move on to Clark Glymour’s “Exploratory Research Is More Reliable Than Confirmatory Research.” His complete slides are after my comments.
I resume my comments on the contributions to our symposium on Philosophy of Statistics at the Philosophy of Science Association. My earlier comment was on Gerd Gigerenzer’s talk. I move on to Clark Glymour’s “Exploratory Research Is More Reliable Than Confirmatory Research.” His complete slides are after my comments.
GLYMOUR’S ARGUMENT (in a nutshell):
“The anti-exploration argument has everything backwards,” says Glymour (slide #11). While John Ioannidis maintains that “Research findings are more likely true in confirmatory designs,” the opposite is so, according to Glymour. (Ioannidis 2005, Glymour’s slide #6). Why? To answer this he describes an exploratory research account for causal search that he has been developing:
 (slide #5)
(slide #5)
What’s confirmatory research for Glymour? It’s moving directly from rejecting a null hypothesis with a low P-value to inferring a causal claim.
 (slide #2)
(slide #2)
MAYO ON GLYMOUR:
I have my problems with Ioannidis, but Glymour’s description of exploratory inquiry is not what Ioannidis is on about. What Ioannidis is or ought to be criticizing are findings obtained through cherry picking, trying and trying again, p-hacking, multiple testing with selective reporting, hunting and snooping, exploiting researcher flexibility—where those gambits make it easy to output a “finding” even though it’s false. In those cases, the purported finding fails to pass a severe test. One reports the observed effect is difficult to achieve unless it’s genuine, when in fact it’s easy (frequent) to attain just by expected chance variability. The central sources of nonreplicability are precisely these data-dependent selection effects, and that’s why they’re criticized.
If you’re testing purported claims with stringency and multiple times, as Glymour describes, subjecting claims arrived at one stage to checks at another, then you’re not really in “exploratory inquiry” as Ioannidis and others describe it. There can be no qualms with testing a conjecture arrived at through searching, using new data (so long as the probability of affirming the finding isn’t assured, even if the causal claim is false.) I have often said that the terms exploratory and confirmatory should be dropped, and we should talk just about poorly tested and well tested claims, and reliable versus unreliable inquiries.
(Added Nov. 20, 2016 in burgundy): Admittedly, and this may be Glymour’s main point, Ioannidis’ categories of exploratory and confirmatory inquires are too coarse. Here’s Ioannidis’ chart:
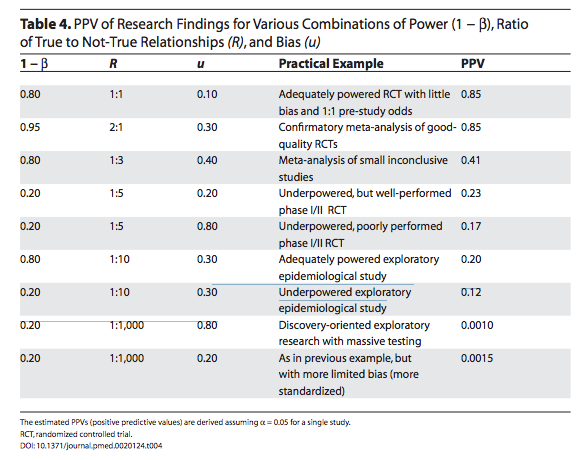
But nowadays, to come away from a discussion thinking that the warranted criticism of unreliable explorations can be ignored, is dangerous. Hence my comment.
Thus we can agree that compared to Glymour’s “exploratory inquiry,” what he calls “confirmatory inquiry” is inferior. Doubtless some people conduct statistical tests this way (shame on them!), but to do so commits two glaring fallacies: (1) moving from a single statistically significant result to a genuine effect; and (2) moving from a statistically significant effect to a causal claim. Admittedly, Ioannidis’ (2005) critique is aimed at such abusive uses of significance tests.
R.A. Fisher denounced these fallacies donkey’s years ago:
“[W]e need, not an isolated record, but a reliable method of procedure. In relation to the test of significance, we may say that a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result.” (Fisher 1935, p.14)
“[A]ccording to Fisher, rejecting the null hypothesis is not equivalent to accepting the efficacy of the cause in question. The latter…requires obtaining more significant results when the experiment, or an improvement of it, is repeated at other laboratories or under other conditions.” (Gigerenzer et al 1989, pp. 95-6)
Glymour has been a leader in developing impressive techniques for causal exploration and modeling. I take his thesis to be that stringent modeling and self-critical causal searching are likely to do better than extremely lousy “experiments.” (He will correct me if I’m wrong.)
I have my own severe gripes with Ioannidis’ portrayal and criticism of significance tests in terms of what I call “the diagnostic screening model of tests.” I can’t tell from Glymour’s slides whether he agrees that looking at the posterior predictive value (PPV), as Ioannidis does, is legitimate for scientific inference, and as a basis for criticizing a proper use of significance tests. I think it’s a big mistake and has caused serious misunderstandings. Two slides from my PSA presentation allude to this[i].


Moreover, using “power” as a conditional probability for a Bayesian-type computation here is problematic (the null and alternative don’t exhaust the space of possibilities). Issues with the diagnostic screening model of tests have come up a lot on this blog. Some relevant posts are at the end. Please share your thoughts.
Here are Clark Glymour’s slides:
Clark Glymour (Alumni University Professor in Philosophy, Carnegie Mellon University, Pittsburgh, Pennsylvania) “Exploratory Research is More Reliable Than Confirmatory Research” (Abstract)
[i] I haven’t posted my PSA slides yet; I wanted the focus of this post to be on Glymour.
Blogposts relating to the “diagnostic model of tests”
- (11/9) Beware of questionable front page articles warning you to beware of questionable front page articles (iii)
- 03/16 Stephen Senn: The pathetic P-value (Guest Post)
- 05/09 Stephen Senn: Double Jeopardy?: Judge Jeffreys Upholds the Law (sequel to the pathetic P-value)
- 01/17 “P-values overstate the evidence against the null”: legit or fallacious?
- 01/19 High error rates in discussions of error rates (1/21/16 update)
- 01/24 Hocus pocus! Adopt a magician’s stance, if you want to reveal statistical sleights of hand
- 04/11 When the rejection ratio (1 – β)/α turns evidenc0e on its head, for those practicing in an error-statistical tribe (ii)
- (08/28) TragiComedy hour: P-values vs posterior probabilities vs diagnostic error rates
References:
- Fisher, R. A. (1947). The Design of Experiments, 4th ed. Edinburgh: Oliver and Boyd.
- Gigerenzer, G., Swijtink, Z., Porter, T., Daston, L., Beatty, J., & Krüger, L. (1989). Empire of Chance: How Probability Changed Science and Everyday Life. Cambridge UK: Cambridge University Press.
- Ioannidis, J. (2005). “Why most published research findings are false“, PLoS Med 2(8):0696-0701.


")


Some people say that the same data set cannot be used to discover an effect and then validate that same effect. Mayo and Glymour seem to dispute that view? Hence, Glymour suggests that, in exploratory research, positive casual claims can be “tested or assessed multiple times, against multiple competing hypotheses in multiple subsamples of the data.” And Mayo says “there can be no qualms with testing a conjecture arrived at through searching, using new data,” …and I think she implies that the “new data” can be from the same data set? So, for example, in psychology the new data could come from the same research participants?
I think that a completely independent data set (i.e., a new study with a new sample of participants) often provides a better test of validity of a newly discovered effect than further exploratory tests using the original data set. However, that does not dispute the point that I take away from Glymour and Mayo here – that exploratory research (or “exploratory inquiry”) can be done well or poorly, and that good exploratory research can involve corroboratory tests that are based on relatively independent (“new”) data that is derived from the *same* data set.
I like Mayo’s point that “if you’re testing purported claims with stringency and multiple times, as Glymour describes, subjecting claims arrived at one stage to checks at another, then you’re not really in “exploratory inquiry” as Ioannidis and others describe it.” But I’m not sure others would agree with this. Some hardliners might argue that if you use the same data set to (a) discover an effect and then (b) validate that effect then you are being “exploratory”. I personally think this sort of argument is too black and white, and that the more moderate and realistic position takes into consideration how “independent” and “new” your corroboratory tests are compared to your discovery tests. The more independent your corroboratory tests from your discovery tests, the less exploratory you are and the more confirmatory you are? Makes any sense?
Lucy
Lucy: Thanks for your comment; I agree with your sentiments. There’s been a lot of confusion about when the “same” data can be used both to arrive at and test a hypothesis. That’s why I’ve written so much on “double counting” and violations of “novel data”. In reliably testing assumptions of a statistical model M, for example, the data to be used in testing M’s assumptions aren’t really the “same” as used in testing a claim within M. The data are remodeled to ask a different question, e.g., one looks at residuals. What really matters is whether you’ve done a good job probing the way the given claim may be wrong. That this doesn’t preclude “double counting” is essentially how I arrived at the notion of “severity”. However, despite many clear-cut cases, there are, in the end, vague cases, still needing attention. For an early paper of mine (from 25 years ago!) on novel evidence: the controversy as to how to define it, and when and why it should matter, in philosophy of science, see:
Click to access (1991)%20Novel%20Evidence%20and%20Severe%20Tests.pdf
Also search “double counting” on this blog.
Lucy,
I think the desire for “new data” is borne out of a feeling that exploratory work can be pulled into spurious interpretations by random artifacts in the first data examined. The risk of mistaking noise for signal must be addressed by rigorous examination of methods used and results. It is possible to have a severe test during the course of an exploratory study. The key is to address that explicitly, since every interpretation/conclusion follows from methods used to arrive at them. In my opinion, some of the literature on this topic stumbles in precisely this area. (As when a paper cites numbers of replication failures without drilling into what should have been proper interpretation according to the statistics used. If 20 papers employed cherry-picking to obtain stat significance, this does not point to a deficiency of significance tests. )
Test.
Dear Deborah,
Read Ioannidis 2005 paper carefully. He says his arguments apply to “high throughput” methods, i.e., “exploratory search” like that I (and thousands of others) advocate. He has no argument.
A tweet and a retweet from Maria Glymour, the second with a link to Gelman’s blog:
What an excellent paper Deborah. Thank you for the link. It provides much needed nuance to the other discussions I’ve read on exploratory vs confirmatory research and the idea that you can’t use the same data set to (a) discover a new hypothesis and (b) then test that hypothesis. If I understand your paper correctly, you are saying that whether or not hypotheses are corroborated using exploratory or confirmatory (pre-registered; “use-novel”) data is a bit of a red herring. What really matters is the quality (severity) of the tests used to investigate your hypothesis, and although pre-registration can help to increase the quality (severity) of those tests, high quality tests can also be conducted in the exploratory domain. Two questions if you have time:
1. Would you argue then that the crisis of confidence in psychology and elsewhere is not due to the lack of confirmatory (pre-registered) research per se but rather due to the lack of severe tests?
2. I suppose that some would argue that tests cannot be adequately severe unless researcher degrees of freedom are pinned down via pre-registration; something you touch on in the section on “biased interpretation of evidence”?
Lucy:
I appreciate your comment, glad you liked that paper on novel facts. I would agree to your #1, and deny that literal preregistration is necessary for severity, however, it’s obviously important for people used to cherry picking and p-hacking.
I would argue for 1. As for 2, no one knows the “degrees of freedom” an investigator uses in selecting hypotheses to test; in contrast, one can know exactly the degrees of freedom a search procedure has.
Curmud:
How do you know the degrees in searching? One would still like to know how it influences the overall reliability or severity. It might be good to use a term like “constrained search” rather than lump it under exploratory, which definitely has the connotation of just shopping and not self-testing in any way. Are you familiar with Glymour’s work?
A draft of the paper associated with Glymour’s presentation is here:
Click to access a-million-variables-and-more-2016-proofs.pdf
Mayo writes: “I have my problems with Ioannidis, but Glymour’s description of exploratory inquiry is not what Ioannidis is on about. What Ioannidis is or ought to be criticizing are findings obtained through cherry picking, trying and trying again, p-hacking, multiple testing with selective reporting, hunting and snooping, exploiting researcher flexibility—where those gambits make it easy to output a “finding” even though it’s false. ”
To the contrary, it is exactly what he is on about. To the contrary again, he begins his Plos Medicine paper with a little calculation for when the probability of false “positive relationships” is greater than the probability of true “positive relationships.” That calculation depends on assuming the choice of hypotheses to test is independent of their truth or falsity. Yes, he goes on to denounce cherry picking, bias, etc. but Mayo is wrong about the initial argument. And that is the argument Colquhoun takes up.
In my opinion, boh Ioannidis and Colquhoun mislead us (unwittingly) by their use of priors for truth of nulls. Muddies the water unnecessarily.
Curmud(g)eon: I am not sure where you think we’re disagreeing. I agree with you as to what’s wrong with (what I call) the diagnostic screening model of statistical tests (in science). Even if “the choice of hypotheses to test” is not independent of their truth or falsity, Colquihoun insists the probability of their truth can’t be more than .5. Further, the tests must be two-sided. The computations are very old: a 2-sided test of point null Ho with spiked prior, the remaining prior on a hypothesis H’ that, together with the null, does not exhaust the space. The power against H’ is supposed to be high, and then that number is used as if it were a conditional probability in a Bayesian computation (which it isn’t). The #’s are usually attributed to Berger and Sellke (1987) but go back at least to Edwards, Lindmann and Savage from~1962. The main problems are listed on my 2 slides.
See the Berger and Sellke chart & links on this post:
https://errorstatistics.com/2016/01/17/p-values-overstate-the-evidence-against-the-null-legit-or-fallacious/
My point (in relation to your slides)wasn’t that they rely on the high prior to the null–unwarranted as that is– it’s that your “exploration” doesn’t seem to be the kind of exploration that Ioannidis is criticizing., that’s all. He requires the searching to increase the probability of a type 1 error (e.g., due to selective reporting, p-hacking, and the like). His numbers depend on that. I took you to be arguing that a finding that survives your analysis has passed a reasonably severe test.
Glymour’s presentation, like Colqohoun’s Royal Society paper, derives pop culture value by presenting headlines with a catchy twist. “Exploratory Research is more reliable than Confirmatory Research” starts a presentation with a “pop”, because on the face of it, it appears to contradict common sense.
I recommend that people take a step back, and get out their thinking caps, when such contradictory statements lead off a discussion. Such constructions are designed to get our attention by being contrarian, rather than to demonstrate proper handling of a complex situation.
How can an initial foray into unknown territory, an initial exploratory analysis, be more reliable than follow-up studies following other follow-up studies, Fisher’s “a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result” scenario?
I do find the term “exploratory analysis” to be useful, precisely in the initial phases of study in new territory, where previous data is nonexistent or lacking. In such situations, we can not perform power calculations generally because we do not yet know what sizes of measured effects have any scientific, economic, biological, or medical relevance. In such circumstances, when we fail to reject a null hypothesis, we can not then accept the null hypothesis. We necessarily are left still in a state of ignorance as to whether the null, or some alternative, better fit the newly derived data. Even if our initial test does end up rejecting the null hypothesis at some given type I error rate, we still do not know if the effect we have uncovered has any scientific relevance, since a statistically significant difference is not always scientifically relevant.
Once we have gathered several sets of data to address the phenomenon under scrutiny, we enter into the confirmatory realm, where (if indeed anything is going on) repeated experiments rarely fail to give us a statistically significant result, and we have a better understanding of what sizes of measured effects have relevance.
Of course in any situation we can always gather several large data sets, and orchestrate repeated statistically significant findings, but if we do not conduct the exercise of hashing out what effect sizes really have any scientific or economic or medical relevance, a set of statistically significant findings can end up being of no real scientific relevance.
Severity calculations on initial exploratory data can certainly aid in understanding what effect sizes are sufficiently severely tested with the data at hand, but the exercise of assessing what measured effect sizes mean something scientifically, or biologically, or medically, still needs to take place. Such exercises are generally challenging – how much extra survival makes a course of radiation or chemotherapy for a cancer patient worthwhile? What level of up or down regulation of cellular proteins yield beneficial or problematic biological outcomes? The challenge of such evaluations leaves too many researchers all too ready to simply apply formulaic statistical procedures in cherry-picking and p-hacking forays. It is our job as statisticians to encourage such conversations, to force researchers to come to some understanding of what sizes of measured effects have relevance in the context of the phenomenon under scrutiny. Only then can we conduct meaningful power calculations, or assess whether relevant measured effect sizes have been severely tested.
I disagree with Glymour’s slide 2 statement “If null [A and B are independent] is rejected, H [A and B are causally connected] is confirmed”. Stating that A and B are causally connected is generally used in fallacious arguments that A causes B, or B causes A. Rejecting the null hypothesis of independence of A and B only demonstrates that some sort of association is present, but does not prove that A causes B or vice versa. Uncovering associations is an important first step in developing understanding of causal pathways, but additional reasoning based on physical or other principles of the phenomenon under study are generally necessary before solid causal relationships can be declared. Presenting statistical tools with labels such as “causal” just starts the problematic resultant writings now in the spotlight.
Glymour concludes with another contrarian statement: “Almost everything said and written in statistics about the superiority of ‘confirmatory’ research and the evils of data driven hypothesis search is wrong, very wrong”. I find it challenging to believe that the thinking of heavyweights from Karl Pearson and Ronald Fisher through Eric Lehman, David Cox, Bradley Efron and other Stanford heavyweights, and Deborah Mayo have yielded nothing but a mountain of wrong, which Clark Glymour has now set right.
Steven:
It may be that much of the apparent disagreement here is semantical. Today’s world of alarming pronouncements (most findings are false, science is in crisis, is broken, has lost its self-correcting ability) might provoke one to a rival surprising claim (as with my “beware of questionable front page articles warning you to beware of questionable front page articles”.
https://errorstatistics.com/2013/11/09/beware-of-questionable-front-page-articles-warning-you-to-beware-of-questionable-front-page-articles-i/).
However, there’s too much danger that people will think bad exploratory practices are being condoned if they’re waved away, even though I know that Glymour has a much more self-conscious program in mind, designed to avoid common sources of unreliability. That’s mostly what I meant to highlight by my response.
Reportedly, medievals cited Aristotle to determine the number of teeth a horse has. Mr. McKinney uses the same strategy for issues of causal inference. He does not recognize when a slide is stating a viewpoint other than authors. I can only urge, likeliy in vain, that he put aside his a priori contempt and read the arguments and proofs that have emerged in the last quarter century, starting with Spirtes, et al. Causation, Prediction and Search.
Clark: The number of teeth a horse has? I’d heard of the # of deaths through horse kicks in some army being modeled with the Poisson distribution.
On your point, suppose we agree that a correct description of a “confirmatory” or “corroboratory” test wouldn’t be the howler described by Ioannidis (as per your slide #2), but something more like a stringent experimental test. Then is it still true that exploratory is better than confirmatory?
With all of Ioannidis valuable later work on method, it’s too bad this early paper has led to a widespread tendency to confuse the probability of a type 1 error with a very different animal: the prevalence of true nulls among those randomly chosen from an urn with k% true and rejected with p=.05. The prosecutor’s fallacy is more common than ever as a result, and p-values are thought to “exaggerate” the evidence against a null because they differ from this erroneous prevalence computation.
Clark:
You do seem to be following Fisher’s advice for analyzing non-randomized studies – make your theories complex – and try very hard to displace a hoped for theory with another ho-hum theory that can explain almost just as well.
With limited data I tried to do something similar here – found the minimum adjusted effect estimate for all possible adjustments for measured covariates http://cid.oxfordjournals.org/content/28/4/800.full.pdf
I am guessing with a well designed and executed randomized study you likely would do a confirmatory analysis.
Or maybe not?
Keith O’Rourke
This is very interesting, although I’d have used the term “exploratory” in a somewhat different manner, following the John W. Tukey tradition. The major difference to what is discussed here is that when I analyse data in an exploratory manner, I don’t aim at “significance” claims. I may occasionally use formal significance tests but don’t take the results literally because these tests are embedded in a flow of steps that is not formalised and therefore doesn’t allow for proper adjustment of p-values. Rather these tests are there to highlight some issues for further investigation, besides many other techniques, particularly graphical.
There are attempts to test outcomes of such an analysis (e.g., “Statistical inference for exploratory data analysis and model diagnostics”, Buja, Cook, Hofmann, Lawrence, Lee, Swayne, Wickham, 2009; Philosophical Transactions of The Royal Society, A, available on Andreas Buja’s homepage http://www-stat.wharton.upenn.edu/~buja/), but the interpretation of a significant result is quite unspecific, “the data are not compatible with the null model” without inference to any specific alternative (although of course it is possible to give a “qualitative” interpretation of the findings).
The methods alluded to in Glymour’s slides seem to be somehow between Tukey-style exploratory analysis and confirmatory analysis in that procedures need to be sufficiently formally defined and restricted and the same holds for the considered model classes.
By the way, while these methods probably work well in situations in which there are few true effects but those are big, in more common situations in which there are many effects and the vast majority of them is pretty small, and there is a smooth transition between the smallest and the biggest effects, the power of these procedures may be too weak (“biased against positive findings”) to find anything.
Christian: Thanks much for the reference!