
StatSci/PhilSci Museum
Where you are in the Journey*
Cox: [I]n some fields foundations do not seem very important, but we both think that foundations of statistical inference are important; why do you think that is?
Mayo: I think because they ask about fundamental questions of evidence, inference, and probability … we invariably cross into philosophical questions about empirical knowledge and inductive inference. (Cox and Mayo 2011, p. 103)
Contemporary philosophy of science presents us with some taboos: Thou shalt not try to find solutions to problems of induction, falsification, and demarcating science from pseudoscience. It’s impossible to understand rival statistical accounts, let alone get beyond the statistics wars, without first exploring how these came to be “lost causes.” I am not talking of ancient history here: these problems were alive and well when I set out to do philosophy in the 1980s. I think we gave up on them too easily, and by the end of Excursion 2 you’ll see why. Excursion 2 takes us into the land of “Statistical Science and Philosophy of Science” (StatSci/PhilSci). Our Museum Guide gives a terse thumbnail sketch of Tour I. Here’s a useful excerpt:
Once the Problem of Induction was deemed to admit of no satisfactory, non-circular solutions (~1970s), philosophers of science turned to building formal logics of induction using the deductive calculus of probabilities, often called Confirmation Logics or Theories. A leader of this Confirmation Theory movement was Rudolf Carnap. A distinct program, led by Karl Popper, denies there is a logic of induction, and focuses on Testing and Falsification of theories by data. At best a theory may be accepted or corroborated if it fails to be falsified by a severe test. The two programs have analogues to distinct methodologies in statistics: Confirmation theory is to Bayesianism as Testing and Falsification are to Fisher and Neyman–Pearson.
.
Tour I begins with the traditional Problem of Induction, then moves to Carnapian confirmation and takes a brief look at contemporary formal epistemology. Tour II visits Popper, falsification, and demarcation, moving into Fisherian tests and the replication crisis. Redolent of Frank Lloyd Wright’s Guggenheim Museum in New York City, the StatSci/PhilSci Museum is arranged in concentric sloping oval floors that narrow as you go up. It’s as if we’re in a three-dimensional Normal curve. We begin in a large exposition on the ground floor. Those who start on the upper floors forfeit a central Rosetta Stone to decipher today’s statistical debates.
2.1 The Traditional Problem of Induction
Start with the asymmetry of falsification and confirmation. One black swan falsifies the universal claim that C: all swans are white. Observing a single white swan, while a positive instance of C, wouldn’t allow inferring generalization C, unless there was only one swan in the entire population. If the generalization refers to an infinite number of cases, as most people would say about scientific theories and laws, then no matter how many positive instances observed, you couldn’t infer it with certainty. It’s always possible there’s a black swan out there, a negative instance, and it would only take one to falsify C. But surely we think enough positive instances of the right kind might warrant an argument for inferring C. Enter the problem of induction. First, a bit about arguments.
Soundness versus Validity
An argument is a group of statements, one of which is said to follow from or be supported by the others. The others are premises, the one inferred, the conclusion. A deductively valid argument is one where if its premises are all true, then its conclusion must be true. Falsification of “all swans are white” follows a deductively valid argument. Let ~C be the denial of claim C.
(1) C: All swans are white.
x is a swan but is black.
Therefore, ~C.
We can also infer, validly, what follows if a generalization C is true.
(2) C: All swans are white
x is a swan.
Therefore, x is white.
However, validity is not the same thing as soundness. Here’s a case of argument form (2):
(3) All philosophers can fly
Mayo is a philosopher.
Therefore, Mayo can fly.
Validity is a matter of form. Since (3) has a valid form, it is a valid argument. But its conclusion is false! That’s because it is unsound: at least one of its premises is false (the first). No one can stop you from applying deductively valid arguments, regardless of your statistical account. Don’t assume you will get truth thereby. Bayes’ Theorem can occur in a valid argument, within a formal system of probability:
(4) If Pr(H1), .. . , Pr(Hn) are the prior probabilities of an exhaustive set of hypotheses, and Pr(x|Hi) the corresponding likekihoods.
Data x are given, and Pr(H1|x) is defined.
Therefore, Pr(H1|x) = p.1
The conclusion is the posterior probability Pr(H1|x). It can be inferred only if the argument is sound: all the givens must hold (at least approximately). To deny that all of statistical inference is reducible to Bayes’ Theorem is not to preclude your using this or any other deductive argument. What you need to be concerned about is their soundness. So, you will still need a way to vouchsafe the premises.
Now to the traditional philosophical problem of induction. What is it? Why has confusion about induction and the threat of the traditional or “logical” problem of induction made some people afraid to dare use the “I” word? The traditional problem of induction seeks to justify a type of argument: one taking a form of enumerative induction (EI) (or the straight rule of induction). Infer from past cases of A’s that were B’s to all or most A’s will be B’s:
EI: All observed A1, A2, .. ., An have been B’s.
Therefore, H: all A’s are B’s.
It is not a deductively valid argument, because clearly its premises can all be true while its conclusion false. It’s invalid, as is so for any inductive argument. As Hume (1739) notes, nothing changes if we place the word “probably” in front of the conclusion: it is justified to infer from past A’s being B’s that, probably, all or most A’s will be B’s. To “rationally” justify induction is to supply a reasoned argument for using EI. The traditional problem of induction, then, involves trying to find an argument to justify a type of argument!
Exhibit (i): Justifying Induction Is Circular. In other words, the traditional problem of induction is to justify the conclusion:
Conclusion: : EI is rationally justified, it’s a reliable rule.
We need an argument for concluding EI is reliable. Using an inductive argument to justify induction lands us in a circle. We’d be using the method we’re trying to justify, or begging the question. What about a deductively valid argument? The premises would have to be things we know to be true, otherwise the argument would not be sound. We might try:
Premise 1: EI has been reliable in a set of observed cases.
Trouble is, this premise can’t be used to deductively infer EI will be reliable in general: the known cases only refer to the past and present, not the future. Suppose we add a premise:
Premise 2: Methods that have worked in past cases will work in future cases.
Yet to assume Premise 2 is true is to use EI, and thus, again, to beg the question.
Another idea for the additional premise is in terms of assuming nature is uniform. We do not escape: to assume the uniformity of nature is to assume EI is a reliable method. Therefore, induction cannot be rationally justified. It is called the logical problem of induction because logical argument alone does not appear able to solve it. All attempts to justify EI assume past successes of a rule justify its general reliability, which is to assume EI – what we’re trying to show.
I’m skimming past the rest of a large exhibition on brilliant attempts to solve induction in this form. Some argue that although an attempted justification is circular it is not viciously circular. (An excellent source is Skyrms 1986.)
But wait. Is inductive enumeration a rule that has been reliable even in the past? No. It is reasonable to expect that unobserved or future cases will be very different from the past, that apparent patterns are spurious, and that observed associations are not generalizable. We would only want to justify inferences of that form if we had done a good job ruling out the many ways we know we can be misled by such an inference. That’s not the way confirmation theorists see it, or at least, saw it.
Exhibit (ii): Probabilistic (Statistical) Affirming the Consequent. Enter logics of confirmation. Conceding that we cannot justify the inductive method (EI), philosophers sought logics that represented apparently plausible inductive reasoning. The thinking is this: never mind trying to convince a skeptic of the inductive method, we give up on that. But we know what we mean. We need only to make sense of the habit of applying EI. True to the logical positivist spirit of the 1930s–1960s, they sought evidential relationships between statements of evidence and conclusions. I sometimes call them evidential-relation (E-R) logics. They didn’t renounce enumerative induction, they sought logics that embodied it. Begin by fleshing out the full argument behind EI:
If H: all A’s are B’s, then all observed A’s (A1, A2, .. ., An) are B’s.
All observed A’s (A1, A2, .. ., An) are B’s.
Therefore, H: all A’s are B’s.
The premise that we added, the first, is obviously true; the problem is that the second premise can be true while the conclusion false. The argument is deductively invalid – it even has a name: affirming the consequent. However, its probabilistic version is weaker. Probabilistic affirming the consequent says only that the conclusion is probable or gets a boost in confirmation or probability – a B-boost. It’s in this sense that Bayes’ Theorem is often taken to ground a plausible confirmation theory. It probabilistically justifies EI in that it embodies probabilistic affirming the consequent.
How do we obtain the probabilities? Rudolf Carnap’s audacious program (1962) had been to assign probabilities of hypotheses or statements by deducing them from the logical structure of a particular (first order) language. These were called logical probabilities. The language would have a list of properties (e.g., “is a swan,” “is white”) and individuals or names (e.g., i, j, k). The task was to assign equal initial probability assignments to states of this mini world, from which we could deduce the probabilities of truth functional combinations. The degree of probability, usually understood as a rational degree of belief, would hold between two statements, one expressing a hypothesis and the other the data. C(H,x) symbolizes “the confirmation of H, given x.” Once you have chosen the initial assignments to core states of the world, calculating degrees of confirmation is a formal or syntactical matter, much like deductive logic. The goal was to somehow measure the degree of implication or confirmation that x affords H. Carnap imagined the scientist coming to the inductive logician to have the rational degree of confirmation in H evaluated, given her evidence. (I’m serious.) Putting aside the difficulty of listing all properties of scientific interest, from where do the initial assignments come?
Carnap’s first attempt at a C-function resulted in no learning! For a toy illustration, take a universe with three items, i, j, k, and a single property B. “Bk” expresses “k has property B.” There are eight possibilities, each called a state description. Here’s one: {Bi, ~Bj, ~Bk}. If each is given initial probability of ⅛, we have what Carnap called the logic c†. The degree of confirmation that j will be black given that i was white = ½, which is the same as the initial confirmation of Bi (since it occurs in four of eight state descriptions). Nothing has been learned: c† is scrapped. By apportioning initial probabilities more coarsely, one could learn, but there was an infinite continuum of inductive logics characterized by choosing the value of a parameter he called λ (λ continuum). λ in effect determines how much uniformity and regularity to expect. To restrict the field, Carnap had to postulate what he called “inductive intuitions.” As a logic student, I too found these attempts tantalizing – until I walked into my first statistics class. I was also persuaded by philosopher Wesley Salmon:
Carnap has stated that the ultimate justification of the axioms is inductive intuition. I do not consider this answer an adequate basis for a concept of rationality. Indeed, I think that every attempt, including those by Jaakko Hintikka and his students, to ground the concept of rational degree of belief in logical probability suffers from the same unacceptable apriorism. (Salmon 1988, p. 13).
This program, still in its heyday in the 1980s, was part of a general logical positivist attempt to reduce science to observables plus logic (no metaphysics). Had this reductionist goal been realized, which it wasn’t, the idea of scientific inference being reduced to particular predicted observations might have succeeded. Even with that observable restriction, the worry remained: what does a highly probable claim, according to a particular inductive logic, have to do with the real world? How can it provide “a guide to life?” (e.g., Kyburg 2003, Salmon 1966). The epistemology is restricted to inner coherence and consistency. However much contemporary philosophers have gotten beyond logical positivism, the hankering for an inductive logic remains. You could say it’s behind the appeal of the default (non-subjective) Bayesianism of Harold Jeffreys, and other attempts to view probability theory as extending deductive logic.
Exhibit (iii): A Faulty Analogy Between Deduction and Induction. When we heard Hacking announce (Section 1.4): “there is no such thing as a logic of statistical inference” (1980, p. 145), it wasn’t only the failed attempts to build one, but the recognition that the project is “founded on a false analogy with deductive logic” (ibid.). The issue here is subtle, and we’ll revisit it through our journey. I agree with Hacking, who is agreeing with C. S. Peirce:
In the case of analytic [deductive] inference we know the probability of our conclusion (if the premises are true), but in the case of synthetic [inductive] inferences we only know the degree of trustworthiness of our proceeding. (Peirce 2.693)
In getting new knowledge, in ampliative or inductive reasoning, the conclusion should go beyond the premises; probability enters to qualify the overall “trustworthiness” of the method. Hacking not only retracts his Law of Likelihood (LL), but also his earlier denial that Neyman–Pearson statistics is inferential. “I now believe that Neyman, Peirce, and Braithwaite were on the right lines to follow in the analysis of inductive arguments” (Hacking 1980, p. 141). Let’s adapt some of Hacking’s excellent discussion.
When we speak of an inference, it could mean the entire argument including premises and conclusion. Or it could mean just the conclusion, or statement inferred. Let’s use “inference” to mean the latter – the claim detached from the premises or data. A statistical procedure of inferring refers to a method for reaching a statistical inference about some aspect of the source of the data, together with its probabilistic properties: in particular, its capacities to avoid erroneous (and ensure non-erroneous) interpretations of data. These are the method’s error probabilities. My argument from coincidence to weight gain (Section 1.3) inferred H: I’ve gained at least 4 pounds. The inference is qualified by the detailed data (group of weighings), and information on how capable the method is at blocking erroneous pronouncements of my weight. I argue that, very probably, my scales would not produce the weight data they do (e.g., on objects with known weight) were H false. What is being qualified probabilistically is the inferring or testing process.
By contrast, in a probability or confirmation logic, what is generally detached is the probability of H, given data. It is a probabilism. Hacking’s diagnosis in 1980 is that this grows out of an abiding logical positivism, with which he admits to having been afflicted. There’s this much analogy with deduction: In a deductively valid argument: if the premises are true then, necessarily, the conclusion is true. But we don’t attach the “necessarily” to the conclusion. Instead it qualifies the entire argument. So mimicking deduction, why isn’t the inductive task to qualify the method in some sense, for example, report that it would probably lead to true or approximately true conclusions? That would be to show the reliable performance of an inference method. If that’s what an inductive method requires, then Neyman–Pearson tests, which afford good performance, are inductive.
My main difference from Hacking here is that I don’t argue, as he seems to, that the warrant for the inference is that it stems from a method that very probably gets it right (so I may hope it is right this time). It’s not that the method’s reliability “rubs off” on this particular claim. I say inference C may be detached as indicated or warranted, having passed a severe test (a test that C probably would have failed, if false in a specified manner). This is the central point of Souvenir D. The logician’s “semantic entailment” symbol, the double turnstile: “|=”, could be used to abbreviate “entails severely”:
Data + capacities of scales |=SEV I’ve gained at least k pounds.
(The premises are on the left side of |=.) However, I won’t use this notation
Keeping to a deductive logic of probability, we never detach an inference. This is in sync with a probabilist such as Bruno de Finetti:
The calculus of probability can say absolutely nothing about reality .. . As with the logic of certainty, the logic of the probable adds nothing of its own: it merely helps one to see the implications contained in what has gone before. (de Finetti 1974, p. 215)
These are some of the first clues we’ll be collecting on a wide difference between statistical inference as a deductive logic of probability, and an inductive testing account sought by the error statistician. When it comes to inductive learning, we want our inferences to go beyond the data: we want lift-off. To my knowledge, Fisher is the only other writer on statistical inference, aside from Peirce, to emphasize this distinction.
In deductive reasoning all knowledge obtainable is already latent in the postulates. Rigour is needed to prevent the successive inferences growing less and less accurate as we proceed. The conclusions are never more accurate than the data. In inductive reasoning we are performing part of the process by which new knowledge is created. The conclusions normally grow more and more accurate as more data are included. It should never be true, though it is still often said, that the conclusions are no more accurate than the data on which they are based. (Fisher 1935b, p. 54)
NOTES:
1
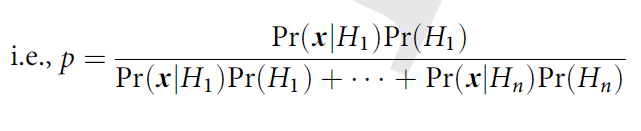

.
*Where you are in the Journey: I posted all of Excursion 1 Tour I, here, here, and here, and omitted Tour II (but blogposts on the Law of Likelihood, Royall, optional stopping, and Barnard, whose birthday was Sept 23, may be found by searching this blog). I am now moving to Excursion 2, posting the first stop of Tour I (2.1). For the full Itinerary of Statistical Inference as Severe Testing: How to Get Beyond the Stat Wars (2018, CUP) SIST Itinerary


")


A very interesting post – thank you for that.
Some readers might not be aware that a lot of progress was made on Carnap’s approach after the 1980s. Paris and Vencovska (2015), Pure Inductive Logic, CUP, provides a detailed guide to the state of the art. I’m a bit sceptical about Carnap’s approach, but in my (2017) Lectures on Inductive Logic, OUP, I put forward a synthesis of a Bayesian approach and a frequentist approach to develop an inductive logic that, I suggest, achieves much of what Carnap set out to do.
Note that the Bayesian does have a way to detach the probability from the conclusion statement: having determined which probability attaches to the conclusion statement, one can go on to infer the conclusion categorically if doing so has maximum expected utility. This also yields a genuinely ampliative form of induction. (As you point out, some argue, in line with de Finetti and Howson (2000, Hume’s Problem, OUP), that the ‘logic’ only covers determining the probability of the conclusion. Accepting the conclusion might be thought to go beyond logic because such an inference depends on the utilities of correctly or mistakenly accepting of failing to accept.)
Thanks for your comment. I agree the Bayesian can detach the probability of a hyp. It relies on an exhaustive set of hypotheses, which is why many if not most Bayesians prefer to stop with a comparative claim. The problem remains assigning the priors. The kind of system you endorse, a default Bayesian assignment, is discussed elsewhere in the book. Here the main emphasis is to explain what an alternate view might be, starting from the position that probabilistic affirming the consequent is not a reliable way to proceed, unless one can rule out the flaws in moving from positive instances to generalizations or predictions. (Of course a lot can be hidden under utilities.) I’ll be glad to hear what you think of the more sustained discussion of default Bayesianism.