

.
In my last post, I said I’d come back to a (2021) article by David Bickel, “Null Hypothesis Significance Testing Defended and Calibrated by Bayesian Model Checking” in The American Statistician. His abstract begins as follows:
Significance testing is often criticized because p-values can be low even though posterior probabilities of the null hypothesis are not low according to some Bayesian models. Those models, however, would assign low prior probabilities to the observation that the p-value is sufficiently low. That conflict between the models and the data may indicate that the models needs revision. Indeed, if the p-value is sufficiently small while the posterior probability according to a model is insufficiently small, then the model will fail a model check….(from Bickel 2021)
Bickel will go further and use this result to transform a P-value into an upper bound on the posterior probability of the null hypothesis (conditional on rejection) for any Bayesian model that would pass the check (at some small, conventional level). I focus just on the first part, as it appears to be a reductio argument against the most common form of criticism of P-values. I suggested, in my post, that one might look at his argument as rigorously cashing out R.A. Fisher’s claim that if a p-value is low, but a given prior probability assignment to the null results in the posterior probability of the null hypothesis being high, then the prior would itself be rejected by data at a small level of significance. (I’m not sure if that’s quite how Bickel sees it although he does regard his argument as following Fisher’s disjunctive statistical significance test reasoning.)
The key equation from which his result follows is an application of Bayes’ theorem (cash out the left most term and it falls out):
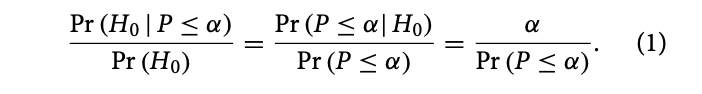
“Thus, even if α is small, the posterior probability of H0 can be high relative to its prior probability, provided that Pr(P < α) is not much larger than α. In that case, however, Pr(P < α) would be small even though P < α was observed.” (250)
The argument and its corollaries “support the intuition that null hypotheses with very low p values tend to have relatively low posterior probabilities unless the Bayesian model is inadequate as a predictor of the observation that P < α” (ibid.).
I don’t know the Bayesian response to Bickel’s argument. Do you? (If so, please share ideas in the comments.) As Bayesians, they may simply deny the relevance of a (non-Bayesian) p-value test of assumptions. I know that some Bayesians check their models, e.g., Gelman, but he describes this as a “non-Bayesian” piece of his account. I also know Gelman rejects the use of the “spike” prior on a point null. Still, he also seems to buy the argument that p-values “exaggerate” evidence against the null (or at least it crops up in joint papers). I do not claim to know what he would say (I will ask him).
Interestingly, Bickel opens his article noting:
“The mounting opposition against null hypothesis significance testing ranges from” warnings to bannings. “The most trenchant criticisms come from supporters of the likelihood principle, especially Bayesians.” (249) But, as we know, supporting the likelihood principle (LP) is at odds with the use of error probabilities in inference (since it conditions on the observed data, rather than considering other outcomes that could have arisen). Bickel does not say anything more about the LP here, unless I missed it. Granted, even staunch supporters of the LP make an exception for testing assumptions (as the LP already assumes the model)–but their ground for doing so is unclear.
The prior predictive p-value for checking the Bayesian model for the prior, which he writes as mdl, considers P-values other than the one observed, and so, strictly speaking, violates the LP. The prior predictive p-value is:
F(p) = Pr(P < p).
“In analogy with testing a null hypothesis, P plays the role of a test statistic, p plays the role of the observed vlue of P, and mdl plays the role of the tested null hypothesis.If the p-value for testing H0 is sufficiently low and yet the posterior probability of H0 is sufficiently high, then the Bayesian model mdl fails the model check based on the prior predictive p-value and passes the check otherwise”. (251)
He proves Theorem 1:
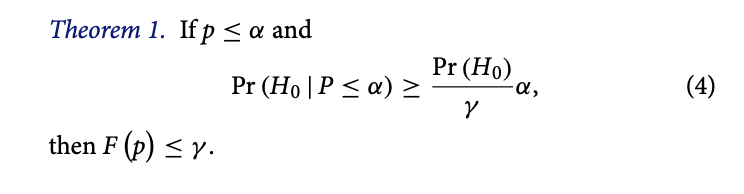
A corollary of Theorem 1 is that “if the p-value is sufficiently low, then any Bayesian model that passes the check yields a relatively low posterior probability of the null hypothesis”. (251)

In fact the corollary is just a logically equivalent transformation of Theorem 1 since
((A & B) → C) is logically equivalent to ((A &~C) → ~B)
From this result, a low p-value ought to lead to a low posterior probability of H0, and the alleged exaggeration cannot happen unless the Bayesian model is flawed.[i] But are Bayesians bound to follow this Fisherian reasoning?
I think Bickel’s paper is very interesting, and I invite you to share your thoughts and any corrections.
[i]I think there are less extreme cases that would still live, including those that arise in what I call the “screening model” of tests. I can come back those examples if they arise in the comments.
References:
Bickel, D. (2021). Null Hypothesis Significance Testing Defended and Calibrated by Bayesian Model Checking. The American Statistician 75(3):249-255.


")


David Bickel shared a link that gives a brief intro to his paper:
https://www.growkudos.com/publications/10.1080%25252F00031305.2019.1699443/reader
> I suggested, in my post, that one might look at his argument as rigorously cashing out R.A. Fisher’s claim that if a p-value is low, but a given prior probability assignment to the null results in the posterior probability of the null hypothesis being high, then the prior would itself be rejected by data at a small level of significance. (I’m not sure if that’s quite how Bickel sees it although he does regard his argument as following Fisher’s disjunctive statistical significance test reasoning.)
I added a response as a comment of that post.
thanks, I will reply to it there.