

Graphing t-plots (This is my first experiment with blogging data plots, they have been blown up a bit, so hopefully they are now sufficiently readable).
Here are two plots (t-plots) of the observed data where yt is the population of the USA in millions, and xt our “secret” variable, to be revealed later on, both over time (1955-1989).
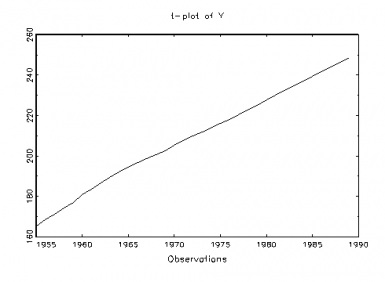
Fig 1: USA Population (y)

Fig. 2: Secret variable (x)
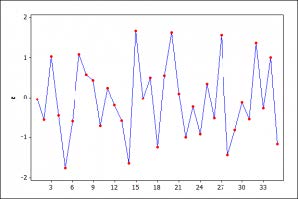
Figure 3: A typical realization of a NIID process.
Pretty clearly, there are glaring departures from IID when we compare a typical realization of a NIID process, in fig. 3, with the t-plots of the two series in figures 1-2. In particular, both data series show the mean is increasing with time – that is, strong mean-heterogeneity (trending mean).Our recommended next step would be to continue exploring the probabilistic structure of the data in figures 1 and 2 with a view toward thoroughly assessing the validity of the LRM assumptions [1]-[5] (table 1). But first let us take a quick look at the traditional approach for testing assumptions, focusing just on assumption [4] traditionally viewed as error non-autocorrelation: E(ut,us)=0 for t≠s, t,s=1,2,…,n.Testing Non-Autocorrelation: The Parametric Durbin-Watson (D-W) Test
The most widely used parametric test for independence is the Durbin-Watson (DW) test. Here, all the assumptions of the LRM are retained, except the one under test —independence—which is ‘relaxed’. In particular, the original error term in M0 is extended to allow for the possibility that the errors ut are correlated with their own past using a particular form of error correlation known as first order AutoRegression (AR(1)), i.e.
ut =ρut-1 + εt, t=1,2,…,n,…,
where {εt, t=1,2, …, n, …,} is a Normal, white-noise process.
That is, a new model, the Autocorrelation-Corrected (A-C) LRM, is assumed as the overarching model:
M1: yt = β0 + β1xt + ut, ut =ρut-1 + εt, t=1,2,…,n,…
If ρ = 0, we are back to Ho. So the D-W test assesses whether or not ρ = 0 in model M1. Obviously, either ρ=0 or ρ ≠ 0, but it is a mistake to suppose we are exhausting all possibilities here, unless we are within M1. One way to bring this out is to view the D-W test as actually considering the conjunctions:
H0: {M1 & ρ=0}, vs. H1: {M1 & ρ ≠ 0}.
With the data in our example, the D-W test statistic rejects the null hypothesis (at level .02), which is standardly taken as grounds to adopt H1. This move to infer H1, however, is warranted only if we are within M1. True, if ρ = 0, we are back to the LRM, but ρ ≠ 0 does not entail the particular violation of independence asserted in H1. Nevertheless, modelers routinely go on to infer H1 upon rejecting H0, despite warnings, e.g., “A simple message for autocorrelation correctors: Don’t” (Mizon, 1995).
But it must be admitted that such warnings, right-headed as they are, generally do not go hand in hand with a clear elucidation of why the reasoning is flawed. Only with such an elucidation can one grasp the fallacy that prevents this strategy from uncovering what is really wrong, both with the original LRM and the autocorrelation-corrected (A-C) version of LRM. The latter may be written as A-C LRM, which is too many letters, but not too bad.
Granted, the flaw is not entirely obvious at first, and so it is perhaps understandable that, far from detecting the fallacy, the traditional strategy finds strong evidence that the data misfit makes it necessary to infer the error-autocorrelation of the new model.
Having inferred the A-C LRM, the traditional strategy goes merrily on its way to estimate the new model yielding:
M1: yt = 167.2+ 1.9xt + ût, ut = .43ut-1 + εt,
It appears that the A-C LRM has ‘corrected for’ the anomalous result that led to rejecting the LRM–at least according to the traditional analysis. After all, if we go on to check if the new error process {εt, t=1,2, …, n, …,} is free of any autocorrelation by running another DW test–as is the common strategy– we find indeed it is[1].
Although the A-C LRM has, in one sense, ‘corrected for’ the presence of autocorrelation, because the assumptions of model M1 have been retained in H1, this check had no chance to uncover the various other forms of dependence that could have been responsible for ρ ≠ 0. Thus the inference to H1 lacks severity.
Duhemian problems loom large. By focusing exclusively on the error term the traditional viewpoint overlooks the ways the systematic component of M1 may be misspecified and fails also to acknowledge other hidden assumptions, e.g.,
θ:=(β0 , β1, σ2), are not changing with the index t =1, 2, …, n.
These logical failings lead to a model which, while acceptable according to its own self-scrutiny, is in fact statistically inadequate. If used for the ‘primary’ statistical inferences, the actual error probabilities are much higher than the ones it is thought to license, and such inferences are unreliable at predicting values beyond the data used. This illustrates the kind of pejorative use of the data to construct (ad hoc) a model to account for an anomaly that leads many philosophers of science, as well as statistical modelers, to be wary of any and all misspecification, since ‘double counting’ is involved. But it is a mistake to lump all m-s tests together in the same bin. What is a better way? Stay tuned!
See other parts:
PART 3: https://errorstatistics.com/2012/02/27/misspecification-testing-part-3-m-s-blog/
PART 4: https://errorstatistics.com/2012/02/28/m-s-tests-part-4-the-end-of-the-story-and-some-conclusions/
PART 1: https://errorstatistics.com/2012/02/22/2294/
[1] The Durbin-Watson test statistic, DW = 1.83 – not significant. The t-test for H0: ρ = 0 vs. H1: ρ≠ 0, is significant (p= .004), indicating that the ‘correction’ is justified. In addition, the A-C LRM shows improvements over the LRM in fit.


")

