

A Better Way The traditional approach described in Part 2 did not detect the presence of mean-heterogeneity and so it misidentified temporal dependence as the sole source of misspecification associated with the original LRM.
On the basis of figures 1-3 we can summarize our progress in detecting potential departures from the LRM model assumptions to probe thus far:
| LRM | Alternatives | |
| (D) Distribution: | Normal | ? |
| (M) Dependence: | Independent | ? |
| (H) Heterogeneity: | Identically Distributed | mean-heterogeneity |
Discriminating and Amplifying the Effects of Mistakes We could correctly assess dependence if our data were ID and not obscured by the influence of the trending mean. Although, we can not literally manipulate relevant factors, we can ‘subtract out’ the trending mean in a generic way to see what it would be like if there were no trending mean. Here are the detrended xt and yt.
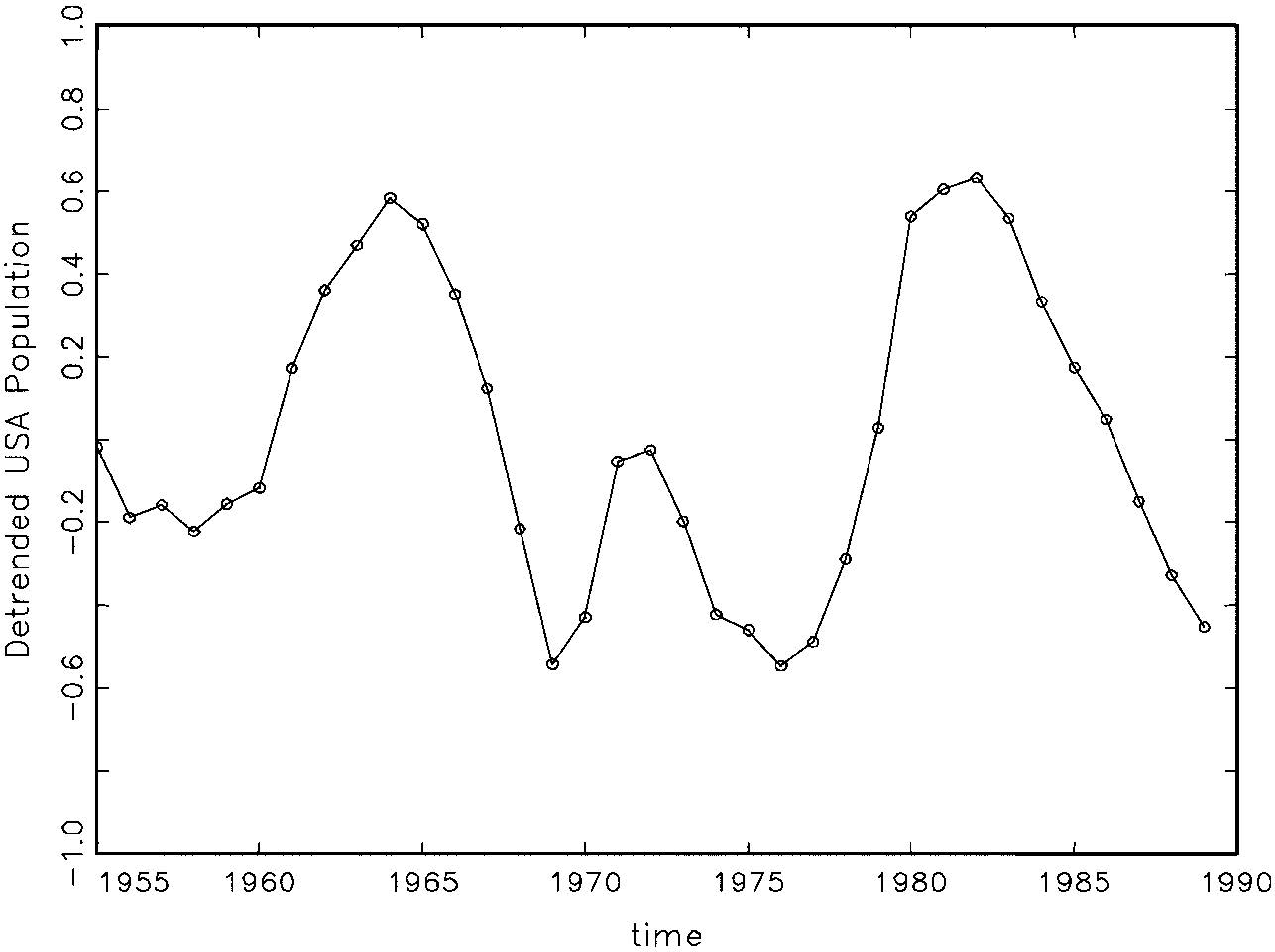
Fig. 4: Detrended Population (y – trend )
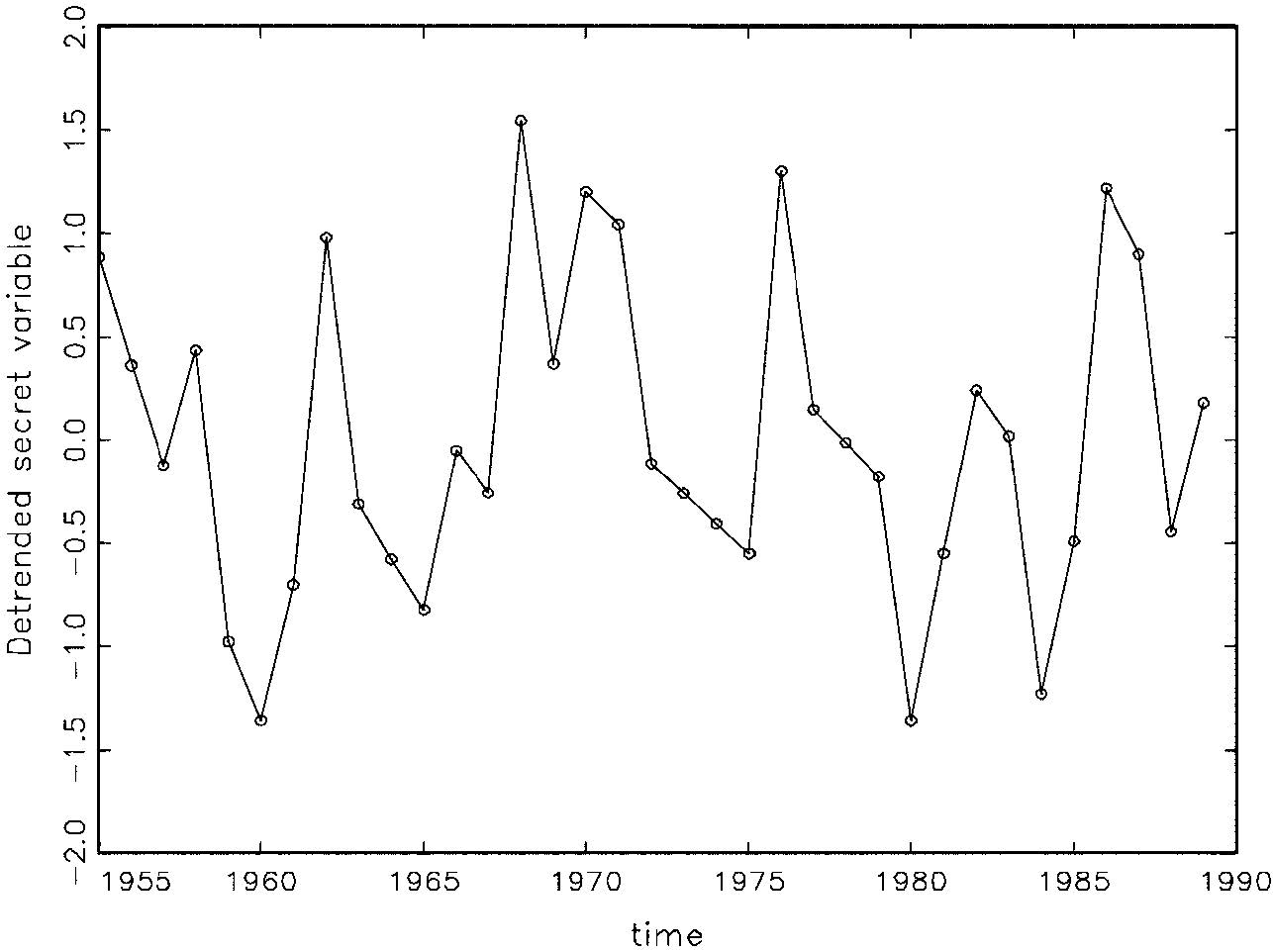
Fig. 5: Detrended Secret Variable (x-trend)
The data in both figures (4-5) indicate, to a trained eye, positive dependence or ‘memory’ in the form of cycles – Markov dependence. So the independence assumption also looks problematic, and this explains the autocorrelation detected by the M-S tests discussed earlier.
Our LRM assessment so far, just on the basis of the graphical analysis is:
| LRM | Alternatives | |
| (D) Distribution: | Normal | ? |
| (M) Dependence: | Independent | Markov |
| (H) Heterogeneity: | Identically Distrib. | mean-heterogeneity |
Finally, we can evaluate the distribution assumption (Normality) graphically if we had IID data. So if we can see what the data z0={(xt, yt), t=1,2,…,n} would look like without the heterogeneity (‘detrended’) and without the dependence (‘dememorized’), we could get some ideas about the appropriateness of the Normality assumption. We do this by subtracting them out “on paper” (shown on graphs).
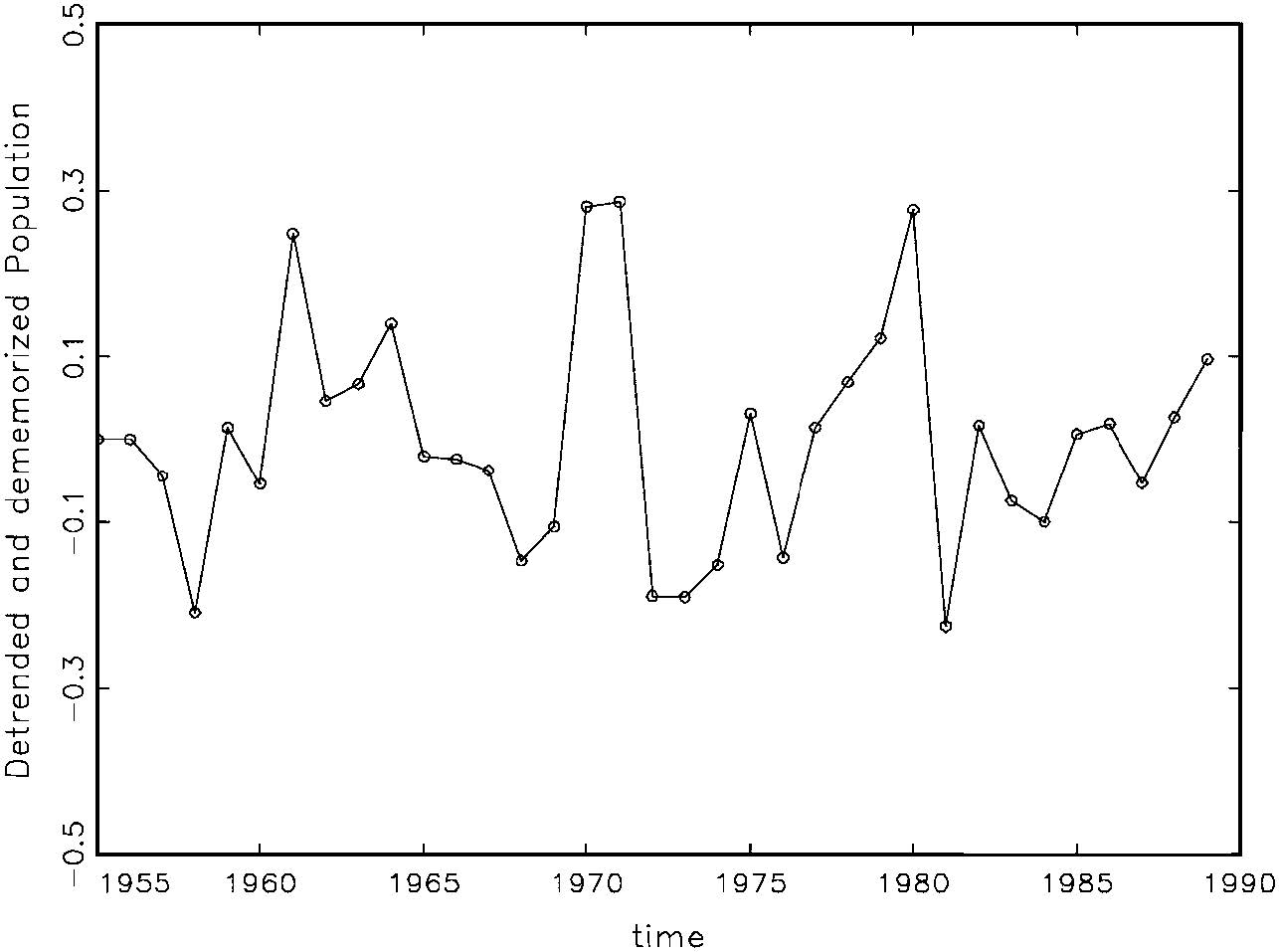
Fig. 6: Detrended & Dememorized Population (y-trend-lags)
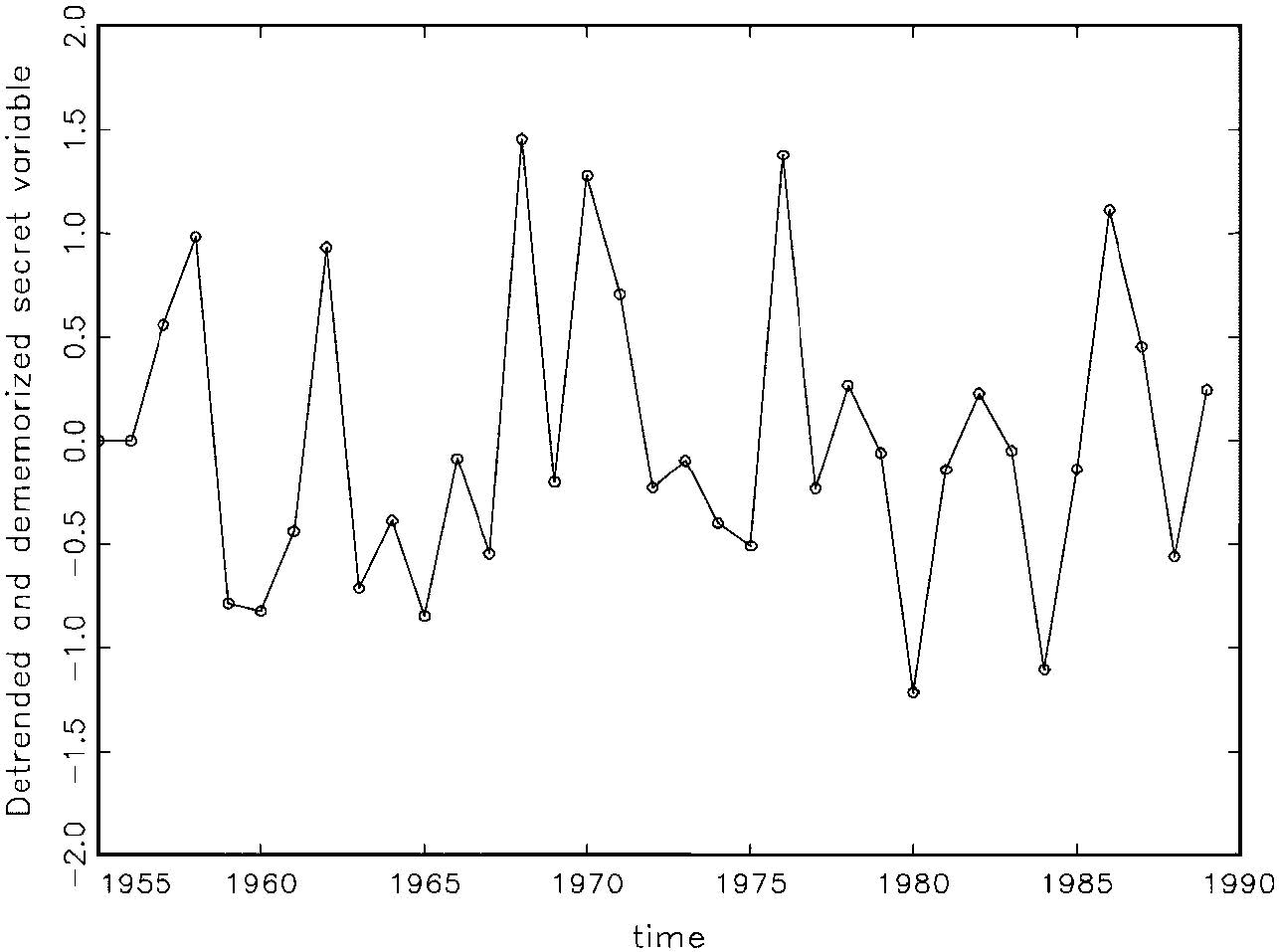
Fig. 7: Detrended & dememorized x (x-trend-lags)

Fig. 8: Scatter plot of detrended & dememorized (x, y)
These plots, as well as the scatter-plot of (xt, yt), show no telltale signs of departure from Normality (the scatter-plot seems elliptical enough). We can organize the resulting alternative models to the LRM that may be used to assess the validity of assumptions [1]-[5] (table 1):
| LRM | Alternatives | |
| (D) Distribution: | Normal | Normal |
| (M) Dependence: | Independent | Markov |
| (H) Heterogeneity: | Identically Distrib. | mean-heterogeneity |
While there are still several selections under each of the menu headings of Markov dependence and mean-heterogeneity, the length of the Markov dependence (m), and the degree (ℓ) of the polynomial in t, the idea is that these would be discerned in subsequent rounds of the probing strategy, which I am only illustrating.
The model derived by re-partitioning the set of all possible models P, using the new reduction assumptions of: Normality, Markov and mean-heterogeneity on D(Z1,…,Zn;φ), is the Dynamic Linear Regression Model (DLRM(ℓ,m), ℓ>0, m>0):
M2: yt = β0 + β1xt + (ℓ-th degree polyonomial in t)+ (m lags in both yt and xt) +ut, t=1,2,…,n,…
The values of (ℓ,m) chosen on statistical adequacy grounds are: ℓ=1,m=2.
Thorough M-S testing show that these values give rise to a statistical model whose assumptions are valid. Three remarks:
First, this DLRM could be used as a basis for ‘designing’ effective M-S tests (often joint tests that include more than one assumption at a time) in order to assess the validity of the original LRM model assumptions.
Second, in light of the M-S testing results viewed as interdependence pieces of information about possible departures from [1]-[5], the DLRM could be used as a basis for respecification: select a new statistical model that does account for all the systematic information we detected using both the informal graphical techniques as well as the more formal M-S tests.
Third, the DLRM is arrived at by probatively ‘looking at the data’ through the graphical discernments, but we must be clear on what is licensed by such qualitative assessments.
Stay tuned for part four–the final part!


")


Deborah, I’m a little confused as to where you’re going with this. There is no assumption in the LRM that Y and X are marginally normally distributed. The typical distributional assumption is that Y is conditionally normally distributed, given X. Thus, although I see the rationale for using the DW test in the previous post, I can’t see how figures 1-3 or the figures presented in this post can make you question the LRM model since they aren’t based on the assumptions of that model, for what they’re worth.
I’m also a bit concerned that the whole assumption of random sampling seems to get dumped by the wayside… going back to our previous “black box” conversation, I understand the difference between design-based and model-based inference, but it seems to me that all model and no design sends the idea of a sampling distribution straight down the rabbit hole. As Oscal Kempthorne said “I have never met random samples except when sampling has been under human control and choice as in random sampling from a finite population or in experimental randomization in the comparative experiment.”
The reason the t-plots and the scatter plot of (x(t), y(t), t=1,2,…,n), are very useful in practice is that the NIID assumptions for the vector process Z(t):=(y(t),X(t)) are sufficient in ensuring that the model assumptions [1]-[5] are valid. This is useful because the conditional process {[y(t) | X(t)=x(t)], t=1,2,…,n,..} is not directly observable, and one can use the plots pertaining to the marginal and joint processes to get some idea of the probabilistic structure of the conditional process. Hence, before the prespecified statistical model is even estimated, one can get a good idea whether the model is reasonable by looking at these data plots. Of course, the M-S testing will be applied to the model assumptions [1]-[5]. However, these plots are also very useful in choosing the relevant M-S tests, and when the model assumptions are found wanting the same plots can guide one to a better, hopefully, statistically adequate model. This is the procedure use to decide that the Dynamic Linear Regression model with mean heterogeneity might be such a better model.
The issue of “random samples” boils down to testing the validity of the IID assumptions using one’s data, and thus it’s an empirical issue. One needs to be skeptical about the appopriateness of such probabilistic assumptions, but also to know what to do when they are invalid, as in the empirical example above.
Aris, random sampling is absolutely not an empirical issue, it is a design issue (and it’s not even true that random sampling is synonymous with iid, consider, e.g., cluster-randomization or multi-stage sampling … and there’s still a random sampling assumption in the DLRM). Now, if modelers want to pretend that data they just stumbled upon are an iid random sample from some distribution, then one can certainly assess empirically whether one’s data “fit” with such an assumption. That’s fine, although the late David Freedman had much to say about that. But I generally want to know to which (real) population my inferences might apply, and that’s where the sampling distribution comes in — and, as I understand it, the sampling distribution is what provides a basis for inductive inference. If all one has is a model (and if pretend random sampling is part of that model), then the only inductive inference available is to either assume that the model will continue to hold true in the future or that it will hold true for all new data that arise. How many models hold up to such empirical testing? Moreover, if you find a model that fits a single observed dataset almost perfectly, what error-statistical approaches are available to severly test the hypothesis that your model will apply to any data beyond those you used to build the model?
There seems considerable alacrity here about how we’re going to test the model; let’s take a look at the model, choose a way in which it looks defective, and then pick a test that exploits that defect to get a significant result. Is that what AS is suggesting?
Can you imagine if we ran clinical trials in the same way? Let the pharma company come up with data, eyeball it to spot ways in which the treated group look better, and then test to see that, why yes, of *course* they’re different! Bodies like the FDA go to considerable lengths to avoid this sort of thing. Surely inference designed to convince the skeptic won’t permit unregulated peeking at the data?
I agree with Mark about how confused this discussion seems. I suggest a motivating example from something other than bivariate time series; most intro statistical classes use two group comparisons, often in a designed experiment setting. If that’s too simple, do a “simple” regression of one outcome on one covariate.
In an attempt to avoid further misunderstandings and talk passed each other, let me reiterate what are the hypotheses of interest in this empirical example. The primary (substantive) hypothesis of interest is that x(t) is a good predictor of y(t). This is framed, in the first place, as a test of the hypothesis that its coefficient is significantly different from zero. Given that the t-statistic for this coefficient is 79.141 [critical value at .05 around 2], it seems that it is statistically highly significant. However, to ensure that this inference is trustworthy, one needs to ensure that the probabilistic assumptions of the estimated model, that render this t-test reliable, are valid for this particular data. That is where, Mis-Specification (M-S) testing comes into the picture. The basic question posed by M-S testing is whether the particular data constitute a “truly typical” realization of the stochastic process {[y(t)|X(t)=x(t)], t=1,2,…,n..} underlying the Linear Regression (LR) model, i.e. whether assumptions [1]-[5] are valid for this particular data. Hence, the secondary (statistical) hypotheses of interest relevant for M-S testing are the assumptions [1]-[5] which are predesignated once the LR model is selected as the relevant statistical model.
Statistical model validation is all about a modeler doing a thorough job in probing for potential departures from these (predesignated) assumptions; effective probing of potential misspecification errors. When I teach M-S testing I tell my students that there are two crucial problems that can lead a modeler down into the self-delusion cul de sac. The first is to begin M-S testing without knowning what the model assumptions are; have an incomplete list of assumptions – hence the list [1]-[5]. The second is to apply some arbitrary battery of M-S tests that had no capacity [low power] to detect the departures from assumptions [1]-[5]. The idea behind using graphical techniques, in this context, is to make the choice of M-S tests less arbitrary and render the selected M-S tests potentially capable of detecting any departures from [1]-[5]. Looking or graphing the data does not affect either the primary or secondary hypotheses of interest because they are all predesignated. If the data exhibit temporal dependence/heterogeneity nothing in looking or graphing the data will alter that in any shape or form. However, graphing and looking at the data renders M-S testing much more effective by enabling the modeler to select M-S tests that have the capacity to detect the existing departures from [1]-[5], and thus avoid the self-delusion cul de sac. A third potential problem that I warn my students against is to confuse M-S testing with Neyman-Pearson (N-P) testing. The latter is testing withing the boundaries of the prespecified statistical model and the latter is testing outside the boundaries. This gives rise to several differences in both the underlying reasoning and what one can infer from the two types of tests. For instance, the most serious error in M-S testing is actually the type II error (not the type I), because it can lead the unaware into the self-delusion cul de sac! For those interested in these issues, I discuss them extensive in various published papers; e.g. Spanos, A. (2000), “Revisiting Data Mining: `hunting’ with or without a license,” The Journal of Economic Methodology, 7: 231-264.
AS: thanks. I remain concerned at what happens when a model is found wanting, for the purposes of testing a primary hypothesis (or for primary estimation). A weakness having been found, a different model will be proposed, tested, and then when something’s wrong with it we go round again, possibly ad nauseum. Even if we discount the problem that data is often not good at telling us what power the diagnostics at each go round, the fundamental ad hoccery about when to stop means calibrating the frequentist properties of the final product is impossible.
But I’ll read your paper, with interest.
Viewing a statistical model as a parameterization of the stochastic process underlying the data in question, renders statistical model specification and respecification much less ad hoc. One is not just choosing, testing and eliminating one model at a time in an arbitrary fashion; I agree that such a strategy will be an impossible task. The Probabilistic Reduction perspective views statistical model specification as arising from partitioning the set of all possible models that could have given rise to this particular data using three types of probabilistic assumptions: (D) Distributional, (M) Dependence and (H) Heterogeneity. This renders all three aspects of modeling, specification, M-S testing and respecification a lot more coherent and does not involve eliminating one model at a time, but a whole infinite subset of these potential models at a time. In the case of the empirical example, the original model, the Linear Regression (LR), was viewed as a parameterization of a NIID process. In the respecification those reduction assumptions were replaced with a Normal, Markov and mean-heterogeneous process. The latter gave rise to the Dynamic LR model with a trend. M-S testing confirmed that selecting 2 lags and a first degree trend polynomial gives rise to a statistically adequate model.
Alacrity?
I think at least part of the confusion stems from not seeing that the resulting model is tested for statistical adequacy, regardless of where it came from.
laxness, not alacrity, sorry.
Guest: I thought maybe you meant to say “unclarity”. Anyway, I will soon take up some general issues that need clarification, and argue that those clarifications are central here. I do wish people wouldn’t be so quick to assert what they’ve seen before, because there are many long-standing problems that turn out to have been based on essential confusions/presuppositions never really called out. A great example is that of double-counting/non-novel/use-constructed hypotheses. It doesn’t matter how famous the person who makes the argument—or so I have learned. The only reason I’ve stayed in philosophy—a rather absurd field to be in—is that I have been able to unravel, through philosophical/logical means some knotty problems that had long been “decided” one way or another (perhaps in rival ways, but still unchanging within the way chosen).
On violations of novelty, there’s a difference between a method that is bound to find some hypotheses or other that fits data, and one that is bound to find a hypothesis that fits, whether or not that hypothesis is false. (Only the latter violates severity.) There is a difference between the hazards of inferring a real effect (when there may be none) and explaining a known effect (e.g., by elimination). (This parallels a logical distinction we make in non-formal logic).
If there are blurred images in their eclipse photos (in 1919), then “trying and trying again” until it is reliably pinned on a distortion due to the sun’s heat on the lens does not decrease the severity with which the inference (about the distortion’s cause) passes the test—it’s the opposite. See discussion of DNA in Mayo and Cox 2005, reprinted in 2010. I hope the analogy to a proper m-s inference is evident….
I think that two issues that should be mentioned here are identifiability and model complexity. Pick Figure 4 as an isolated example. Of course one can model this with Markov dependence, but one could also model this with a nonlinear function with independent error terms. Admittedly, the nonlinear function will have to be somewhat messy, more complex probably in terms of numbers of parameters, or at least requiring some complex selection work to find a fitting one. Still, it will be statistically as adequate as the Markov model in the sense that the data cannot be distinguished from what can be expected under this model.
Such a model may lead to very different inference, so it would be nice to spell out what role in your modelling procedure and reasoning is played by the nicety and relative simplicity of the Markov model in order to prefer it to a messy nonlinear one, and whether (and why or why not) you’d find it relevant that a quite different model leading to different inference would be statistically adequate for the same data (in other words, the data do not allow to distinguish between these models, which is an identifiability problem).