
I wanted to locate some uncluttered lounge space for one of the threads to emerge in comments from 6/14/13. Thanks to Stanley Young for permission to post this.
 S. Stanley Young, PhD
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
There is a relatively unknown problem with microarray experiments, in addition to the multiple testing problems. Samples should be randomized over important sources of variation; otherwise p-values may be flawed. Until relatively recently, the microarray samples were not sent through assay equipment in random order. Clinical trial statisticians at GSK insisted that the samples go through assay in random order. Rather amazingly the data became less messy and p-values became more orderly. The story is given here:
http://blog.goldenhelix.com/?p=322
Essentially all the microarray data pre-2010 is unreliable. For another example, Mass spec data was analyzed Petrocoin. The samples were not randomized that claims with very small p-values failed to replicate. See K.A. Baggerly et al., “Reproducibility of SELDI-TOF protein patterns in serum: comparing datasets from different experiments,” Bioinformatics, 20:777-85, 2004. So often the problem is not with p-value technology, but with the design and conduct of the study.
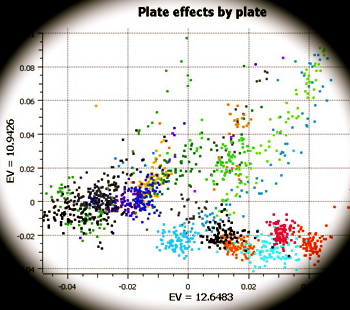
Please check other comments on microarrays from 6/14/13.


")


Response to Tom Kepler (from https://errorstatistics.com/2013/06/14/p-values-cant-be-trusted-except-when-used-to-argue-that-p-values-cant-be-trusted/)
Thanks for the reference to Benjamini. I am going to try to link to a Benjamini 2008 comment on Efron.
https://docs.google.com/file/d/0B8ssu_Mqjthed2JoelNlclAyNVk/edit?usp=sharing
Maybe at some point you can explain something I have puzzled over on p. 3 where he describes giving comments at a conference once and “was almost booed”. The worry about those selection effects seems obvious….or at least as much as the selection effects that give rise to the interest in FDR computations to begin with.
I find it interesting that he views the FDR as more appropriate in dealing with data-dependent selection effects (both for screening and reporting) than the “local” FDR, which he suggests is useful more for “the decision-making scientist”.
Stan: Your link is very interesting! Thanks. For good reason C.S. Peirce zeroed in on the two central features of reliable induction: randomization and predesignation.
“This account of the rationale of induction is distinguished from others in that it has as its consequences two rules of inductive inference which are very frequently violation namely, that the sample be (approximately) random and that the property being tested not be determined by the particular sample—i.e., predesignation.” (C.S. Peirce 1.95)
But also he also indicated how and when they may be violated (given the right kind of information).
“Peircean Induction and the Error-Correcting Thesis” (Mayo 2005)
Click to access Mayo_2005_PeircePaper.pdf
Wasserman posted on the value of adding randomness recently
http://normaldeviate.wordpress.com/2013/06/09/the-value-of-adding-randomness/
Gelman’s blog followed up: http://andrewgelman.com/2013/06/14/progress-on-the-understanding-of-the-role-of-randomization-in-bayesian-inference/
Stan: If microarray data pre-2010 is unreliable, then does that mean like 10+ of nearly wasted years? Can you give an update on this situation? Have the recommendations in the linked article been followed? The ending is worth noting:
“The bottom line is we need to stop the inefficient usage of taxpayer money inherent in running large-scale genetic studies without proper DOE [design of experiments]. Perhaps it is time for the NIH to set forth policy on this before further money is wasted. Perhaps grant reviewers should insist on experts in experimental design being involved before the experiments are run. It most certainly is time for every field that calls itself a science to devote teaching time to the theory and extensive hands-on practice of design of experiments. And then my head will not explode!”
In response to Sander’s remark (from 6/14/13):“’Lack of randomization can mess up p-values.’
Indeed – that was the topic of my 1990 paper “Randomization, statistics, and causal inference.Epidemiology,” 1, 421-429.
Note that almost nothing in epidemiologic research is randomized, and that is source of error in all its stats at least comparable to error from data dredging.”
Sander:
So, you’re saying the source of error is not significance tests, but failure/inability to randomize, or in some other way approximately satisfy the test assumptions, without which reported p-values are unreliable?
Greenland’s 1990 paper is by far one of my favorite papers of all time, it’s right on the money. It should be required reading of everybody involved in public health research. But of course this isn’t old news…. Fisher himself wrote “the physical act of randomization … is necessary for the validity of any test of significance” (Design of Experiments, 1966, p. 45).
Mark: It is not only design of experiments (DOE), and checking assumptions, that are routinely ignored in the way people are apparently taught these methods, there is also the fact (mentioned repeatedly on this blog) that:
” Fisher always denied, even with the lady tasting tea, that an “isolated record” of statistically significant results suffices:
‘In relation to the test of significance, we may say that a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result.’ (Fisher 1935, p.14)
It follows that, for Fisher, even showing the (statistical) reality of an experimental effect, much less showing the evidence of a specific explanation of the effect (be it an evolutionary story about beauty and daughters or something else), requires going beyond an ‘isolated record.'”
Mayo, agree completely, the importance of replication is all too often overlooked. On the other hand, replication in the face of confounding (I.e., absence of randomization) is misleading.
Mark: My interpretation of what Fisher is calling for is not mere replication, as ordinarily understood, but a variety of checks to block erroneously assuming a genuine experimental or reliable effect has been shown. That is why he called for drawing an “elaborate” or varied set of implications so as to put any claim of a real effect to a severe test. For a simple minded example, I need, not repeated weighing with the same scale, but a variety of scales, some of which would reveal errors with objects of known weight, if the weighing were flawed in the case of interest. The key is to be able to find ways that any error in the interpretation (in the case at hand) will have clear ramifications for other ascertainments. The trouble with many statistical inferences is that their mistaken interpretations do not ramify.