
I wanted to locate some uncluttered lounge space for one of the threads to emerge in comments from 6/14/13. Thanks to Stanley Young for permission to post this.
 S. Stanley Young, PhD
S. Stanley Young, PhD
Assistant Director for Bioinformatics
National Institute of Statistical Sciences
Research Triangle Park, NC
There is a relatively unknown problem with microarray experiments, in addition to the multiple testing problems. Samples should be randomized over important sources of variation; otherwise p-values may be flawed. Until relatively recently, the microarray samples were not sent through assay equipment in random order. Clinical trial statisticians at GSK insisted that the samples go through assay in random order. Rather amazingly the data became less messy and p-values became more orderly. The story is given here:
http://blog.goldenhelix.com/?p=322
Essentially all the microarray data pre-2010 is unreliable. For another example, Mass spec data was analyzed Petrocoin. The samples were not randomized that claims with very small p-values failed to replicate. See K.A. Baggerly et al., “Reproducibility of SELDI-TOF protein patterns in serum: comparing datasets from different experiments,” Bioinformatics, 20:777-85, 2004. So often the problem is not with p-value technology, but with the design and conduct of the study.
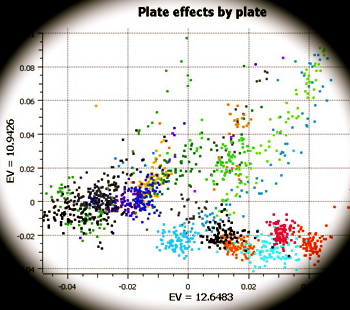
Please check other comments on microarrays from 6/14/13.


")

