

A. Spanos
Aris Spanos was asked to review my Statistical Inference as Severe Testing: how to Get Beyond the Statistics Wars (CUP, 2018), but he was to combine it with a review of the re-issue of Ian Hacking’s classic Logic of Statistical Inference. The journal is OEconomia: History, Methodology, Philosophy. Below are excerpts from his discussion of my book (pp. 843-860). I will jump past the Hacking review, and occasionally excerpt for length.To read his full article go to external journal pdf or stable internal blog pdf.
….
2 Mayo (2018). Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars

The sub-title of Mayo’s (2018) book provides an apt description of the primary aim of the book in the sense that its focus is on the current discussions pertaining to replicability and trustworthy empirical evidence that revolve around the main fault line in statistical inference: the nature, interpretation and uses of probability in statistical modeling and inference. This underlies not only the form and structure of inductive inference, but also the nature of the underlying statistical reasonings as well as the nature of the evidence it gives rise to.
A crucial theme in Mayo’s book pertains to the current confusing and confused discussions on reproducibility and replicability of empirical evidence. The book cuts through the enormous level of confusion we see today about basic statistical terms, and in so doing explains why the experts so often disagree about reforms intended to improve statistical science.
Mayo makes a concerted effort to delineate the issues and clear up these confusions by defining the basic concepts accurately and placing many widely held methodological views in the best possible light before scrutinizing them. In particular, the book discusses at length the merits and demerits of the proposed reforms which include: (a) replacing p-values with Confidence Intervals (CIs), (b) using estimation-based effect sizes and (c) redefining statistical significance.
The key philosophical concept employed by Mayo to distinguish between a sound empirical evidential claim for a hypothesis H and an unsound one is the notion of a severe test: if little has been done to rule out flaws (errors and omissions) in pronouncing that data x0 provide evidence for a hypothesis H, then that inferential claim has not passed a severe test, rendering the claim untrustworthy. One has trustworthy evidence for a claim C only to the extent that C passes a severe test; see Mayo (1983; 1996). A distinct advantage of the concept of severe testing is that it is sufficiently general to apply to both frequentist and Bayesian inferential methods.
Mayo makes a case that there is a two-way link between philosophy and statistics. On one hand, philosophy helps in resolving conceptual, logical, and methodological problems of statistical inference. On the other hand, viewing statistical inference as severe testing gives rise to novel solutions to crucial philosophical problems including induction, falsification and the demarcation of science from pseudoscience. In addition, it serves as the foundation for understanding and getting beyond the statistics wars that currently revolves around the replication crises; hence the title of the book, Statistical Inference as Severe Testing.
Chapter (excursion) 1 of Mayo’s (2018) book sets the scene by scrutinizing the different role of probability in statistical inference, distinguishing between:
(i) Probabilism. Probability is used to assign a degree of confirmation, support or belief in a hypothesis H, given data x0 (Bayesian, likelihoodist, Fisher (fiducial)). An inferential claim H is warranted when it is assigned a high probability, support, or degree of belief (absolute or comparative).
(ii) Performance. Probability is used to ensure the long-run reliability of inference procedures; type I, II, coverage probabilities (frequentist, behavioristic Neyman-Pearson). An inferential claim H is warranted when it stems from a procedure with a low long-run error.
(iii) Probativism. Probability is used to assess the probing capacity of inference procedures, pre-data (type I, II, coverage probabilities), as well as post-data (p-value, severity evaluation). An inferential claim H is warranted when the different ways it can be false have been adequately probed and averted.
Mayo argues that probativism based on the severe testing account uses error probabilities to output an evidential interpretation based on assessing how severely an inferential claim H has passed a test with data x0. Error control and long-run reliability is necessary but not sufficient for probativism. This perspective is contrasted to probabilism (Law of Likelihood (LL) and Bayesian posterior) that focuses on the relationships between data x0 and hypothesis H, and ignores outcomes x∈Rn other than x0 by adhering to the Likelihood Principle (LP): given a statistical model Mθ(x) and data x0, all relevant sample information for inference purposes is contained in L(θ; x0), ∀θ∈Θ. Such a perspective can produce unwarranted results with high probability, by failing to pick up on optional stopping, data dredging and other biasing selection effects. It is at odds with what is widely accepted as the most effective way to improve replication: predesignation, and transparency about how hypotheses and data were generated and selected.
Chapter (excursion) 2 entitled ‘Taboos of Induction and Falsification’ relates the various uses of probability to draw certain parallels between probabilism, Bayesian statistics and Carnapian logics of confirmation on one side, and performance, frequentist statistics and Popperian falsification on the other. The discussion in this chapter covers a variety of issues in philosophy of science, including, the problem of induction, the asymmetry of induction and falsification, sound vs. valid arguments, enumerative induction (straight rule), confirmation theory (and formal epistemology), statistical affirming the consequent, the old evidence problem, corroboration, demarcation of science and pseudoscience, Duhem’s problem and novelty of evidence. These philosophical issues are also related to statistical conundrums as they relate to significance testing, fallacies of rejection, the cannibalization of frequentist testing known as Null Hypothesis Significance Testing (NHST) in psychology, and the issues raised by the reproducibility and replicability of evidence.
Chapter (excursion) 3 on ‘Statistical Tests and Scientific Inference’ provides a basic introduction to frequentist testing paying particular attention to crucial details, such as specifying explicitly the assumed statistical model Mθ(x) and the proper framing of hypotheses in terms of its parameter space Θ, with a view to provide a coherent account by avoiding undue formalism. The Neyman-Pearson (N-P) formulation of hypothesis testing is explained using a simple example, and then related to Fisher’s significance testing. What is different from previous treatments is that the claimed ‘inconsistent hybrid’ associated with the NHST caricature of frequentist testing is circumvented. The crucial difference often drawn is based on the N-P emphasis on pre-data long-run error probabilities, and the behavioristic interpretation of tests as accept/reject rules. By contrast, the post-data p-value associated with Fisher’s significance tests is thought to provide a more evidential interpretation. In this chapter, the two approaches are reconciled in the context of the error statistical framework. The N-P formulation provides the formal framework in the context of which an optimal theory of frequentist testing can be articulated, but in its current expositions lack a proper evidential interpretation. [For the detailed example see his review pdf.] …
If a hypothesis H0 passes a test Τα that was highly capable of finding discrepancies from it, were they to be present, then the passing result indicates some evidence for their absence. The resulting evidential result comes in the form of the magnitude of the discrepancy γ from H0 warranted with test Τα and data x0 at different levels of severity. The intuition underlying the post-data severity is that a small p-value or a rejection of H0 based on a test with low power (e.g. a small n) for detecting a particular discrepancy γ provides stronger evidence for the presence of γ than if the test had much higher power (e.g. a large n).
The post-data severity evaluation outputs the discrepancy γ stemming from the testing results and takes the probabilistic form:
SEV (θ ≶ θ1; x0)=P(d(X) ≷ d(x0); θ1=θ0+γ), for all θ1∈Θ1,
where the inequalities are determined by the testing result and the sign of d(x0). [Ed Note ≶ is his way of combining the definition of severity for both > and <, in order to abbreviate. It is not used in SIST.] When the relevant N-P test result is ‘accept (reject) H0’ one is seeking the smallest (largest) discrepancy γ, in the form of an inferential claim θ ≶ θ1=θ0+γ, warranted by Τα and x0 at a high enough probability, say .8 or .9. The severity evaluations are introduced by connecting them to more familiar calculations relating to observed confidence intervals and p-value calculations. A more formal treatment to the post-data severity evaluation is given in chapter (excursion) 5.[Ed. note: “Excursions” are actually Parts, Tours are chapters]
Mayo uses the post-data severity perspective to scorch several misinterpretations of the p-value, including the claim that the p-value is not a legitimate error probability. She also calls into question any comparisons of the tail areas of d(X) under H0 that vary with x∈Rn, with posterior distribution tail areas that vary with θ∈Θ, pointing out that this is tantamount to comparing apples and oranges!
The real life examples of the 1919 eclipse data for testing the General Theory of Relativity, as well as the 2012 discovery of the Higgs particle are used to illustrate some of the concepts in this chapter.
The discussion in this chapter sheds light on several important problems in statistical inference, including several howlers of statistical testing, Jeffreys’ tail area criticism, weak conditionality principle and the likelihood principle.
…[To read about excursion 4, see his full review pdf.]
Chapter (excursion) 5, entitled ‘Power and Severity’, provides an in-depth discussion of power and its abuses or misinterpretations, as well as scotch several confusions permeating the current discussions on the replicability of empirical evidence.
Confusion 1: The power of a N-P test Τα:= {d(X), C1(α)} is a pre-data error probability that calibrates the generic (for any sample realization x∈Rn ) capacity of the test in detecting different discrepancies from H0, for a given type I error probability α. As such, the power is not a point function one can evaluate arbitrarily at a particular value θ1. It is defined for all values in the alternative space θ1∈Θ1.
Confusion 2: The power function is properly defined for all θ1∈Θ1 only when (Θ0, Θ1) constitute a partition of Θ. This is to ensure that θ∗ is not in a subset of Θ ignored by the comparisons since the main objective is to narrow down the unknown parameter space Θ using hypothetical values of θ. …Hypothesis testing poses questions as to whether a hypothetical value θ0 is close enough to θ∗ in the sense that the difference (θ∗ – θ0) is ‘statistically negligible’; a notion defined using error probabilities.
Confusion 3: Hacking (1965) raised the problem of using predata error probabilities, such as the significance level α and power, to evaluate the testing results post-data. As mentioned above, the post-data severity aims to address that very problem, and is extensively discussed in Mayo (2018), excursion 5.
Confusion 4: Mayo and Spanos (2006) define “attained power” by replacing cα with the observed d(x0). But this should not be confused with replacing θ1 with its observed estimate [e.g., xn], as in what is often called “observed” or “retrospective” power. To compare the two in example 2, contrast:
Attained power: POW(µ1)=Pr(d(X) > d(x0); µ=µ1), for all µ1>µ0,
with what Mayo calls Shpower which is defined at µ=xn:
Shpower: POW(xn)=Pr(d(X) > d(x0); µ=xn).
Shpower makes very little statistical sense, unless point estimation justifies the inferential claim xn ≅ µ∗, which it does not, as argued above. Unfortunately, the statistical literature in psychology is permeated with (implicitly) invoking such a claim when touting the merits of estimation-based effect sizes. The estimate xn represents just a single value of Xn ∼N(µ, σ2/n ), and any inference pertaining to µ needs to take into account the uncertainty described by this sampling distribution; hence, the call for using interval estimation and hypothesis testing to account for that sampling uncertainty. The post-data severity evaluation addresses this problem using hypothetical reasoning and taking into account the relevant statistical context (11). It outputs the discrepancy from H0 warranted by test Τα and data x0, with high enough severity, say bigger than .85. Invariably, inferential claims of the form µ ≷ µ1= xn are assigned low severity of .5.
Confusion 5: Frequentist error probabilities (type I, II, coverage, p-value) are not conditional on H (H0 or H1) since θ=θ0 or θ=θ1 being ‘true or false’ do not constitute legitimate events in the context of Mθ(x); θ is an unknown constant. The clause ‘given H is true’ refers to hypothetical scenarios under which the sampling distribution of the test statistic d(X) is evaluated as in (10).
This confusion undermines the credibility of Positive Predictive Value (PPV):
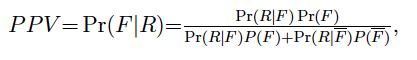
where (i) F = H0 is false, (ii) R=test rejects H0, and (iii) H0: no disease, used by Ioannidis (2005) to make his case that ‘most published research findings are false’ when PPV = Pr(F|R)<.5. His case is based on ‘guessing’ probabilities at a discipline wide level, such as Pr(F)=.1, Pr(R|F)=.8 and Pr(R|F)=.15, and presuming that the last two relate to the power and significance level of a N-P test. He then proceeds to blame the wide-spread abuse of significance testing (p-hacking, multiple testing, cherry-picking, low power) for the high de facto type I error (.15). Granted, such abuses do contribute to untrustworthy evidence, but not via false positive/negative rates since (i) and (iii) are not legitimate events in the context of Mθ(x), and thus Pr(R|F) and Pr(R|F) have nothing to do with the significance level and the power of a N-P test. Hence, the analogical reasoning relating the false positive and false negative rates in medical detecting devices to the type I and II error probabilities in frequentist testing is totally misplaced. These rates are established by the manufacturers of medical devices after running a very large number (say, 10000) of medical ‘tests’ with specimens that are known to be positive or negative; they are prepared in a lab. Known ‘positive’ and ‘negative’ specimens constitute legitimate observable events one can condition upon. In contrast, frequentist error probabilities (i) are framed in terms of θ (which are not observable events in Mθ(x)) and (ii) depend crucially on the particular statistical context (11); there is no statistical context for the false positive and false negative rates.
A stronger case can be made that abuses and misinterpretations of frequentist testing are only symptomatic of a more extensive problem: the recipe-like/uninformed implementation of statistical methods. This contributes in many different ways to untrustworthy evidence, including: (i) statistical misspecification (imposing invalid assumptions on one’s data), (ii) poor implementation of inference methods (insufficient understanding of their assumptions and limitations), and (iii) unwarranted evidential interpretations of their inferential results (misinterpreting p-values and CIs, etc.).
Mayo uses the concept of a post-data severity evaluation to illuminate the above mentioned issues and explain how it can also provide the missing evidential interpretation of testing results. The same concept is also used to clarify numerous misinterpretations of the p-value throughout this book, as well as the fallacies:
(a) Fallacy of acceptance (non-rejection). No evidence against H0 is misinterpreted as evidence for it. This fallacy can easily arise when the power of a test is low (e.g. small n problem) in detecting sizeable discrepancies.
(b) Fallacy of rejection. Evidence against H0 is misinterpreted as evidence for a particular H1. This fallacy can easily arise when the power of a test is very high (e.g. large n problem) and it detects trivial discrepancies; see Mayo and Spanos (2006).
In chapter 5 Mayo returns to a recurring theme throughout the book, the mathematical duality between Confidence Intervals (CIs) and hypothesis testing, with a view to call into question certain claims about the superiority of CIs over p-values. This mathematical duality derails any claims that observed CIs are less vulnerable to the large n problem and more informative than p-values. Where they differ is in terms of their inferential claims stemming from their different forms of reasoning, factual vs. hypothetical. That is, the mathematical duality does not imply inferential duality. This is demonstrated by contrasting CIs with the post-data severity evaluation.
Indeed, a case can be made that the post-data severity evaluation addresses several long-standing problems associated with frequentist testing, including the large n problem, the apparent arbitrariness of the N-P framing that allows for simple vs. simple hypotheses, say H0: µ= 1 vs. H1: µ=1, the arbitrariness of the rejection thresholds, the problem of the sharp dichotomy (e.g. reject H0 at .05 but accept H0 at .0499), and distinguishing between statistical and substantive significance. It also provides a natural framework for evaluating reproducibility/replicability issues and brings out the problems associated with observed CIs and estimation-based effect sizes; see Spanos (2019).
Chapter 5 also includes a retrospective view of the disputes between Neyman and Fisher in the context of the error statistical perspective on frequentist inference, bringing out their common framing and their differences in emphasis and interpretation. The discussion also includes an interesting summary of their personal conflicts, not always motivated by statistical issues; who said the history of statistics is boring?
Chapter (excursion) 6 of Mayo (2018) raises several important foundational issues and problems pertaining to Bayesian inference, including its primary aim, subjective vs. default Bayesian priors and their interpretations, default Bayesian inference vs. the Likelihood Principle, the role of the catchall factor, the role of Bayes factors in Bayesian testing, and the relationship between Bayesian inference and error probabilities. There is also discussion about attempts by ‘default prior’ Bayesians to unify or reconcile frequentist and Bayesian accounts.
A point emphasized in this chapter pertains to model validation. Despite the fact that Bayesian statistics shares the same concept of a statistical model Mθ(x) with frequentist statistics, there is hardly any discussion on validating Mθ(x) to secure the reliability of the posterior distribution:…upon which all Bayesian inferences are based. The exception is the indirect approach to model validation in Gelman et al (2013) based on the posterior predictive distribution: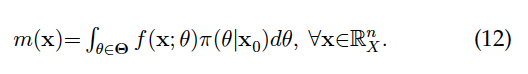 Since m(x) is parameter free, one can use it as a basis for simulating a number of replications x1, x2, …, xn to be used as indirect evidence for potential departures from the model assumptions vis-à-vis data x0, which is clearly different from frequentist M-S testing of the Mθ(x) assumptions. The reason is that m(x) is a smoothed mixture of f(x; θ) and π(θ|x0 ) and one has no way of attributing blame to one or the other when any departures are detected. For instance, in the case of the simple Normal model in (9), a highly skewed prior might contribute (indirectly) to departures from the Normality assumption when tested using simulated data using (12). Moreover, the ‘smoothing’ with respect to the parameters in deriving m(x) is likely to render testing departures from the IID assumptions a lot more unwieldy.
Since m(x) is parameter free, one can use it as a basis for simulating a number of replications x1, x2, …, xn to be used as indirect evidence for potential departures from the model assumptions vis-à-vis data x0, which is clearly different from frequentist M-S testing of the Mθ(x) assumptions. The reason is that m(x) is a smoothed mixture of f(x; θ) and π(θ|x0 ) and one has no way of attributing blame to one or the other when any departures are detected. For instance, in the case of the simple Normal model in (9), a highly skewed prior might contribute (indirectly) to departures from the Normality assumption when tested using simulated data using (12). Moreover, the ‘smoothing’ with respect to the parameters in deriving m(x) is likely to render testing departures from the IID assumptions a lot more unwieldy.
On the question posed by the title of this review, Mayo’s answer is that the error statistical framework, a refinement or extension of the original Fisher-Neyman-Pearson framing in the spirit of Peirce, provides a pertinent foundation for frequentist modeling and inference.
3 Conclusions
A retrospective view of Hacking (1965) reveals that its main weakness is that its perspective on statistical induction adheres too closely to the philosophy of science framing of that period, and largely ignores the formalism based on the theory of stochastic processes {Xt, t∈N} that revolves around the concept of a statistical model Mθ(x). Retrospectively, its value stems primarily from a number of very insightful arguments and comments that survived the test of time. The three that stand out are: (i) an optimal point estimator [θ-hat(X)] of θ does not warrant the inferential claim [θ-hat(x0)]≅ θ∗, (ii) a statistical inference is very different from a decision, and (iii) the distinction between the pre-data error probabilities and the post-data evaluation of the evidence stemming from testing results; a distinction that permeates Mayo’s (2018) book. Hacking’s change of mind on the aptness of logicism and the problems with the long run frequency is also particularly interesting. Hacking’s (1980) view of the long run frequency is almost indistinguishable from that of Cramer (1946, 332) and Neyman (1952, 27) mentioned above, or Mayo (2018), when he argues: “Probabilities conform to the usual probability axioms which have among their consequences the essential connection between individual and repeated trials, the weak law of large numbers proved by Bernoulli. Probabilities are to be thought of as theoretical properties, with a certain looseness of fit to the observed world. Part of this fit is judged by rules for testing statistical hypotheses along the lines described by Neyman and Pearson. It is a “frequency view of probability” in which probability is a dispositional property…” (Hacking, 1980, 150-151).
Probability as a dispositional property’ of a chance set-up alludes to the propensity interpretation of probability associated with Peirce and Popper, which is in complete agreement with the model-based frequentist interpretation; see Spanos (2019).
The main contribution of Mayo’s (2018) book is to put forward a framework and a strategy to evaluate the trustworthiness of evidence resulting from different statistical accounts. Viewing statistical inference as a form of severe testing elucidates the most widely employed arguments surrounding commonly used (and abused) statistical methods. In the severe testing account, probability arises in inference, not to measure degrees of plausibility or belief in hypotheses, but to evaluate and control how severely tested different inferential claims are. Without assuming that other statistical accounts aim for severe tests, Mayo proposes the following strategy for evaluating the trustworthiness of evidence: begin with a minimal requirement that if a test has little or no chance to detect flaws in a claim H, then H’s passing result constitutes untrustworthy evidence. Then, apply this minimal severity requirement to the various statistical accounts as well as to the proposed reforms, including estimation-based effect sizes, observed CIs and redefining statistical significance. Finding that they fail even the minimal severity requirement provides grounds to question the trustworthiness of their evidential claims. One need not reject some of these methods just because they have different aims, but because they give rise to evidence [claims] that fail the minimal severity requirement. Mayo challenges practitioners to be much clearer about their aims in particular contexts and different stages of inquiry. It is in this way that the book ingeniously links philosophical questions about the roles of probability in inference to the concerns of practitioners about coming up with trustworthy evidence across the landscape of the natural and the social sciences.
References
- Barnard, George. 1972. Review article: Logic of Statistical Inference. The British Journal of the Philosophy of Science, 23: 123- 190.
- Cramer, Harald. 1946. Mathematical Methods of Statistics, Princeton: Princeton University Press.
- Fisher, Ronald A. 1922. On the Mathematical Foundations of Theoretical Statistics. Philosophical Transactions of the Royal Society A, 222(602): 309-368.
- Fisher, Ronald A. 1925. Statistical Methods for Research Workers. Edinburgh: Oliver & Boyd.
- Gelman, Andrew. John B. Carlin, Hal S. Stern, Donald B. Rubin. 2013. Bayesian Data Analysis, 3rd ed. London: Chapman & Hall/CRC.
- Hacking, Ian. 1972. Review: Likelihood. The British Journal for the Philosophy of Science, 23(2): 132-137.
- Hacking, Ian. 1980. The Theory of Probable Inference: Neyman, Peirce and Braithwaite. In D. Mellor (ed.), Science, Belief and Behavior: Essays in Honour of R. B. Braithwaite. Cambridge: Cambridge University Press, 141-160.
- Ioannidis, John P. A. 2005. Why Most Published Research Findings Are False. PLoS medicine, 2(8): 696-701.
- Koopman, Bernard O. 1940. The Axioms and Algebra of Intuitive Probability. Annals of Mathematics, 41(2): 269-292.
- Mayo, Deborah G. 1983. An Objective Theory of Statistical Testing. Synthese, 57(3): 297-340.
- Mayo, Deborah G. 1996. Error and the Growth of Experimental Knowledge. Chicago: The University of Chicago Press.
- Mayo, Deborah G. 2018. Statistical Inference as Severe Testing: How to Get Beyond the Statistical Wars. Cambridge: Cambridge University Press.
- Mayo, Deborah G. and Aris Spanos. 2004. Methodology in Practice: Statistical Misspecification Testing. Philosophy of Science, 71(5): 1007-1025.
- Mayo, Deborah G. and Aris Spanos. 2006. Severe Testing as a Basic Concept in a Neyman–Pearson Philosophy of Induction. British Journal for the Philosophy of Science, 57(2): 323- 357.
- Mayo, Deborah G. and Aris Spanos. 2011. Error Statistics. In D. Gabbay, P. Thagard, and J. Woods (eds), Philosophy of Statistics, Handbook of Philosophy of Science. New York: Elsevier, 151-196.
- Neyman, Jerzy. 1952. Lectures and Conferences on Mathematical Statistics and Probability, 2nd ed. Washington: U.S. Department of Agriculture.
- Royall, Richard. 1997. Statistical Evidence: A Likelihood Paradigm. London: Chapman & Hall.
- Salmon, Wesley C. 1967. The Foundations of Scientific Inference. Pittsburgh: University of Pittsburgh Press.
- Spanos, Aris. 2013. A Frequentist Interpretation of Probability for Model-Based Inductive Inference. Synthese, 190(9):1555- 1585.
- Spanos, Aris. 2017. Why the Decision-Theoretic Perspective Misrepresents Frequentist Inference. In Advances in Statistical Methodologies and Their Applications to Real Problems. http://dx.doi.org/10.5772/65720, 3-28.
- Spanos, Aris. 2018. Mis-Specification Testing in Retrospect. Journal of Economic Surveys, 32(2): 541-577.
- Spanos, Aris. 2019. Probability Theory and Statistical Inference: Empirical Modeling with Observational Data, 2nd ed. Cambridge: Cambridge University Press.
- Von Mises, Richard. 1928. Probability, Statistics and Truth, 2nd ed. New York: Dover.
- Williams, David. 2001. Weighing the Odds: A Course in Probability and Statistics. Cambridge: Cambridge University Press.


")

