
 Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
[i]I was tempted to say power is one of the “most powerful” notions.It is.True, severity leads us to look, not at the cut-off for rejection (as with power) but the actual observed value, or observed p-value. But the reasoning is the same. Likewise for less artificial cases where the standard deviation has to be estimated. See Mayo and Spanos 2006.
[ii]
- Some say that to compute power requires either knowing the alternative hypothesis (whatever that means), or worse, the alternative’s prior probability! Then there’s the tendency (by reformers no less!) to transpose power in such a way as to get the appraisal of tests exactly backwards. An example is Ziliac and McCloskey (2008). See,for example, the will to understand power: https://errorstatistics.com/2011/10/03/part-2-prionvac-the-will-to-understand-power/
- Many allege that a null hypothesis may be rejected (in favor of alternative H’) with greater warrant, the greater the power of the test against H’, e.g., Howson and Urbach (2006, 154). But this is mistaken. The frequentist appraisal of tests is the reverse, whether Fisherian significance tests or those of the Neyman-Pearson variety. One may find the fallacy exposed back in Morrison and Henkel (1970)! See EGEK 1996, pp. 402-3.
- For a humorous post on this fallacy, see: “The fallacy of rejection and the fallacy of nouvelle cuisine”: https://errorstatistics.com/2012/04/04/jackie-mason/
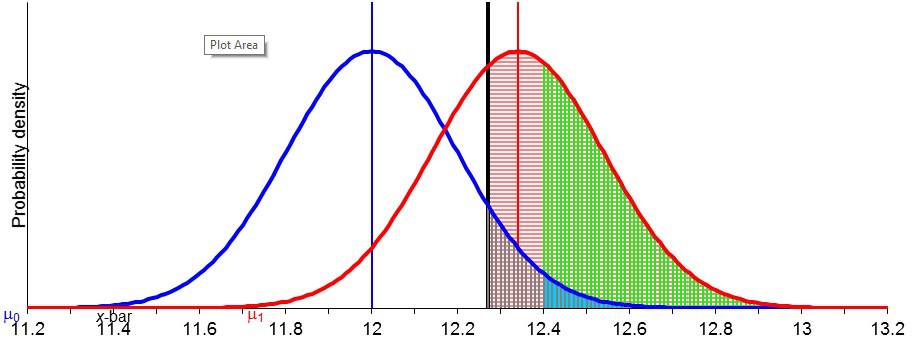
You can find a link to the Severity Excel Program (from which the pictures came) on the left hand column of this blog, and a link to basic instructions.This corresponds to EXAMPLE SET 1 pdf for Phil 6334.
Howson, C. and P. Urbach (2006). Scientific Reasoning: The Bayesian Approach. La Salle, Il: Open Court.
Mayo, D. G. and A. Spanos (2006) “Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction“ British Journal of Philosophy of Science, 57: 323-357.
Morrison and Henkel (1970), The significance Test controversy.
Ziliak, Z. and McCloskey, D. (2008), The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice and Lives, University of Michigan Press.


")


As mentioned before in a comment on Senn’s last posting, for me one of the most appealing properties of the power concept is that one can compute the power of a test against all kinds of alternative distributions, including those that don’t follow the “official” model assumptions. Obviously, as you wrote, one doesn’t need to “know” the alternative; one can compute power against all kinds of alternatives just out of pure curiosity.
… and similarly the bogosity (or not) of the p-values under the null, if the model assumptions don’t hold. It’s all too easy to find comparisons of different methods’ powers in which alpha is not actually controlled.
OG: I don’t see where the “similarly” comes in. Your claim seems to be that invalid computations of error probabilities will lead to invalid comparisons if based on them.
Updated: There may be some ambiguity in Christian’s remark about not following “the ‘official’ model assumptions”. One needs to distinguish the power of a test to detect flaws in an underlying statistical model, and the power to detect discrepancies from a null hypothesis defined within a statistical model.
Christian said one can compute the power under many alternatives. I commented that one can also compute the Type I error rate under many situations, again including those that don’t follow “official” model assumptions, e.g. true linearity of the mean, correctly-specified mean-variance relationships, patterns of correlation, asymptotic approximation achieving decent accuracy, etc.
The “claim”, if one can call it that, is that both exercises are useful. I don’t think this is very controversial, nor are the two exercises unconnected; power is only defined with respect to a particular type I error rate, after all.
But boiling the comment down to your statement that “invalid computations of error probabilities will lead to invalid comparisons” is a bit simplistic; often we don’t know enough to construct a valid (and also useful) p-value; see Bahadur and Savage 1956 for some related impossibility results. Because we’re never going to get exactly valid p-values in practice, we need some idea of how mis-calibrated what we can calculate is likely to be.
OG: I don’t think we require precise p-values, but I’m wondering how you think we can get “some idea of how mis-calibrated what we can calculate is likely to be”. thanks.
I agree about not needing precisely perfect p-values.
One way to get “some idea” of the imperfections is by simulating data under a mechanism that we believe is plausible, and accords with the idea of being “null”, but which doesn’t accord with “official” model assumptions, or where the relevant approximations may not be very good. Then try the method, whatever it is, and see what the Type I error rate is, empirically.
This is fairly standard, in methods papers. Careful statistical practitioners also do it as a form of sensitivity analysis. Either way, some notion of prior plausibility – perhaps not the full Bayes machinery – is essential; you can’t look at all possible mechanisms because there are too many, and you’ll end up obsessing over weird special cases that destroy the method. And you can’t just look at the one mechanism obtained by fitting your favorite model to your data, because there (often) isn’t sufficient information in the data to tell you that such a mechanism closely matches the truth.
Christian: Why do you spoze people claim, some of them, that you’d need to know the prior probability of the alternative to compute power?
I see that WordPress automatically spews out what it takes to be ‘related posts”. It does a pretty good job too.
Although the original guest has a point; actually it is also of interest to look at the test level under distributions that violate the model assumption but would be interpreted in the same way as the null, such as equal non-normal distributions in the two-sample t-test. Of course I’m not against testing model assumptions and using a different method if they are rejected. However, particularly with small samples misspecification tests are not really severe against certain alternatives (such as normality against t-distributions with moderate degrees of freedoms), so they can’t exactly confirm normality (or whatever model assumption is in doubt), and furthermore some deviations from normality are not really a problem, as could be shown by level/power analyses.
“Why do you spoze people claim, some of them, that you’d need to know the prior probability of the alternative to compute power?”
Honestly, no idea. I’d be rather surprised if one could find this position very often, it sounds so totally out of touch with everything non-Bayesian.
Christian – actually I’m not a fan of testing one’s way to the final model. I agree the tests of misspsecification often have poor power, which is bad, but they are more generally non-trivially correlated with the estimates or test results we actually care about. Ignoring the pre-testing step – as people often do – therefore messes up the overall inference.
But I’ve no problem with methods that are fairly insensitive to particular assumptions, provided it’s plausible that the truth doesn’t violate those assumptions by much.
“Why do you spoze people claim, some of them, that you’d need to know the prior probability of the alternative to compute power?”
Now that I think about it: actually the idea behind it could be that frequentists can only compute power as a function of the specific alternative distribution/parameter. If you want a single number characterising the power, these values need to be aggregated somehow, which requires a prior distribution indeed.
The frequentist can respond that we just don’t have to do this.
We report a few benchmarks indicating which discrepancies have an have not passed severely (using a SEV computation). You can give the whole curve. I don’t know that a single number is especially useful in any school, but knowing what’s clearly indicated, and what’s horribly indicated is a good start.
Well, no disagreement; I just tried to imagine what goes on in those Bayesians’ heads. 😉
Still, if you want to choose an optimal test and are not in a situation in which there is a uniformly best one, you could use a prior to get an “expected power” ranking. Even a frequentist could do that. Of course one wouldn’t interpret the prior as “probability that this-or-that alternative is true” then, but rather as a weighting device, expressing which alternatives are seen as more or less important for some reason.
Christian: Yeah, but do you think the prior would reflect frequencies? What’s the weighing device weighing?
In some situations the prior may reflect frequencies, if we have enough experience of that kind, but that’s not really what I have in mind here.
Let’s say I want a test to compare whether the distributions in two samples are the same. I may be interested in either solving the mathematical problem of finding an optimal test. or the practical problem of comparing a number of tests that I have in mind, t-test, Wilcoxon and others for example. I can imagine data to be coming from distributions that are approximately normal, or t_k, or even somewhat but not strongly skewed distributions. Let’s say that the sample size is so small than misspecification tests are not going to rule out any of these. I could define the problem by saying that I look at the t-distribution with up to 10 degrees of freedom, the normal, and the skew normal, all with different location parameters. Let’s assume that all tests have a level of <= \alpha, and also that I can compute power curves for all of the distributions in my collection (more precisely, for all the pairs of distributions and parameters that can occur in the two samples). In order to have a one-dimensional function to optimize, I need to weight the possible alternatives so that I can aggregate all the information. Let's further say I don't worry much (for the moment) about whether I have to write a paper afterwards which could be rejected if what I'm doing looks too subjective; I'm rather concerned about doing something that I think is best.
So I will think about how I need to weight the distributions so that they represent properly the space of possible alternatives and how important these are to me. There are a number of considerations. One of them will be good old de Finetti-style subjective belief. But actually I don't believe that any of these distributions will hold perfectly; I'd rather need to think about how much of what I believe could be relevant is represented by them. So I may give the skew normals a high weight because I weight them against an unduly large collection of symmetric distributions, in order to reflect the fact that I think that the chance that there is indeed some asymmetry in there is not too low. On the other hand, I may weight down the t_1-distribution and certain very extreme asymmetric distributions, not based on my beliefs but rather because I think that if what I observe is really very very skew, or has gross outliers, I will actually detect this and do something else with the data anyway, because this means that there are other reasons for concern than just group differences; also I can find these problems easily with misspecification testing, as opposed to some other things that could be going on. I also have to think about to what extent I believe that differences between the groups in distributional shape (as opposed to location) *count* as relevant differences in terms of the aim of my study. Do I *want* a rejection of the null if one of the distributions is clearly skew and the other one is about symmetric, but both have about the same mean? (Am I interested in finding out significantly that the shape of the outcomes under drug 1 is different from that under drug 2, despite them being equally good on average? Or do I put more importance on having power for alternatives where one drug is clearly better than the other?)
So I could come up with a weighting scheme (mathematically equivalent to a prior distribution) that takes into account all these.
Honestly I don't work like this, but I think it's not a too bad idea. (The most difficult job is to justify the chosen weighting to others, but in terms of the quality of what is done, I think this could be pretty good.)
Christian: I’m afraid that in all these misspecification musings we’re getting too far afield of the issue of power, which is the probability of rejecting a null hypothesis by means of a given test (with its given rejection rule), computed under a particular alternative hypothesis (about the data generating mechanism) . That assessment depends on reference to a given statistical model in which the test is defined. I’m not saying these various other informal ponderings couldn’t arise in contemplating the underlying model.
“Christian: I’m afraid that in all these misspecification musings we’re getting too far afield of the issue of power”
Well, maybe for you but not for me.
If we realize that misspecification tests can have rather limited power (the concept applies there, too) and we therefore very often cannot guarantee that the assumed model holds (with a not too unhealthy degree of approximation), it seems clear enough to me why the power of a test against “nonstandard” (i.e., outside the nominal model) alternatives is relevant.
As an application of the general concept of power, I think that this should be perfectly legitimate, although you can of course choose not to be interested in it.
Christian: (sorry for slow approval, I’ve been in planes and trains) I am interested in the issue of m-s tests with limited power, and it exemplifies the reasoning I’m trying to emphasize: if there was little capability of detecting flawed assumptions, then finding no flaws isn’t good evidence of the absence of flaws. By the same token, if the tests with low power finds flaws, it indicates they’re present.
Were/are formal notions of power given for these m-s tests?
No, m-s tests don’t usually come with an indication of power.
Also, you write that “By the same token, if the tests with low power finds flaws, it indicates they’re present.” Huh? If the test with power=0.06 gets p just below 0.05, there’s not much to distinguish the data from that obtained by chance alone; it’s about as unusual under both scenarios. No?
OG: OMG you just fell into a common misunderstanding! See my March 12, 2014 post (not up yet).
Here it is:
https://errorstatistics.com/2014/03/12/get-empowered-to-detect-power-howlers/
The concept of power is so straightforward that I don’t think a separate formal notion is needed.
The definition is straightforward. For example, if you take the Lilliefors test for normality, the power against any non-normal distribution can be computed as the probability of rejecting normality under this distribution. That’s not rocket science, is it?
What is indeed difficult are the practicalities.
1) It’s often difficult to compute such powers explicitly (they can be simulated though) and
2) there is a large variety of possible alternatives and the power behavior cannot usually be summarized by a single nice curve.
Some choices have to be made at which alternatives one wants to look.
(Actually this gives me an idea for another student project.)
Christian: What’s the project?
Well, simulating some powers for some misspecification tests (and trying to make sense of the results).
(Not sure whether this reply will appear in the right place… the comment hierarchy seems exhausted.)
By the way, John W. Tukey wrote about “Configural Polysampling”, which is also about looking at several families of distributions in a weighted way in order to find an optimal estimator (there may be something about tests, too, in the Morgenthaler & Tukey book about this). Their weighting scheme doesn’t have to do with priors (these guys don’t like Bayesian statistics too much), but then this idea never really took off and one could speculate that they’d have had better chances had they set it up in a way more appealing to Bayesians.
For interested readers, the start of a discussion of misspecification testing is https://errorstatistics.com/2012/02/22/2294/.
My interest for the moment is what kind of reasoning can be based on power, especially post data, even assuming the assessments are approximately correct. A good many of the current-day critical appraisals of tests, including by “reformers” seeking to improve the process, start with given appraisals of power. They don’t doubt they can find, for example, alternatives against which a test has .8 power (a common alternative purportedly of interest). So we may start there. What perplexes me, and demonstrates that they’re up to something very different, is that they wind up declaring a stat sig result is better evidence against the null the stronger the power. In some cases, not all, they seem to be transposing the power; in other cases they are using the size and power as affording a kind of likelihood ratio for a hybridized Bayesian computation. I will come back and link to some examples.* My main point now is to investigate whether I’m right in alleging they are getting the testing logic wrong. I’m not saying they aren’t free to do something entirely different either….but they purport to be in sync with frequentist error statistical testing logic.
*Here’s one: https://errorstatistics.com/2013/11/09/beware-of-questionable-front-page-articles-warning-you-to-beware-of-questionable-front-page-articles-i/
The discussion also reminds me of Hennig’s comment: from https://errorstatistics.com/2013/01/23/p-values-as-posterior-odds/#comment-9894.