

I’m surprised it’s a year already since posting my published comments on the ASA Document on P-Values. Since then, there have been a slew of papers rehearsing the well-worn fallacies of tests (a tad bit more than the usual rate). Doubtless, the P-value Pow Wow raised people’s consciousnesses. I’m interested in hearing reader reactions/experiences in connection with the P-Value project (positive and negative) over the past year. (Use the comments, share links to papers; and/or send me something slightly longer for a possible guest post.)
Some people sent me a diagram from a talk by Stephen Senn (on “P-values and the art of herding cats”). He presents an array of different cat commentators, and for some reason Mayo cat is in the middle but way over on the left side,near the wall. I never got the key to interpretation. My contribution is below:
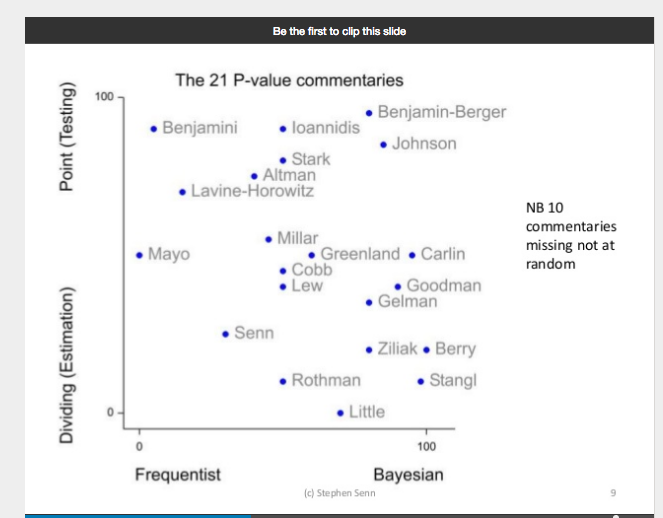
Chart by S.Senn
“Don’t Throw Out The Error Control Baby With the Bad Statistics Bathwater”
D. Mayo*[1]
The American Statistical Association is to be credited with opening up a discussion into p-values; now an examination of the foundations of other key statistical concepts is needed.
Statistical significance tests are a small part of a rich set of “techniques for systematically appraising and bounding the probabilities (under respective hypotheses) of seriously misleading interpretations of data” (Birnbaum 1970, p. 1033). These may be called error statistical methods (or sampling theory). The error statistical methodology supplies what Birnbaum called the “one rock in a shifting scene” (ibid.) in statistical thinking and practice. Misinterpretations and abuses of tests, warned against by the very founders of the tools, shouldn’t be the basis for supplanting them with methods unable or less able to assess, control, and alert us to erroneous interpretations of data.
p-value. The significance test arises to test the conformity of the particular data under analysis with H0 in some respect:
To do this we find a function t = t(y) of the data, to be called the test statistic, such that
- the larger the value of t the more inconsistent are the data with H0;
- the corresponding random variable T = t(Y) has a (numerically) known probability distribution when H0 is true.
…[We define the] p-value corresponding to any t as
p = p(t) = P(T ≥ t; H0). (Mayo and Cox 2006, p. 81)
Clearly, if even larger differences than t occur fairly frequently under H0 (p-value is not small), there’s scarcely evidence of incompatibility. But even a small p-value doesn’t suffice to infer a genuine effect, let alone a scientific conclusion–as the ASA document correctly warns (Principle 3). R.A. Fisher was clear that we need not isolated significant results:
…but a reliable method of procedure. In relation to the test of significance, we may say that a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result. (Fisher 1947, p. 14)
If such statistically significant effects are produced reliably, as Fisher required, they indicate a genuine effect. This is the essence of statistical falsification in science. The logic differs from inductive updating probabilities of a hypothesis, or a comparison of how much more probable H1 makes the data than does H0, as in likelihood ratios. Given the need to use an eclectic toolbox in statistics, it’s important to avoid expecting an agreement on numbers from methods evaluating different things. Hence, it’s incorrect to claim a p-value is “invalid” for not matching a posterior probability based on one or another prior distribution (whether subjective, empirical, or one of the many conventional measures).
Effect sizes. Acknowledging Principle 5, tests should be accompanied by interpretive tools that avoid the fallacies of rejection and non-rejection. These correctives can be articulated in either Fisherian or Neyman-Pearson terms (Mayo and Cox 2006, Mayo and Spanos 2006). For an example of the former, looking at the p-value distribution under various discrepancies from H0: μ= μ0 allows inferring those that are well or poorly indicated. If you very probably would have observed a more impressive (smaller) p-value than you did, if μ>μ1 (where μ1 = μ0 + γ), then the data are good evidence that μ< μ1. This is akin to confidence intervals (which are dual to tests) but we get around their shortcomings: We do not fix a single confidence level, and the evidential warrant for different points in any interval are distinguished. The same reasoning allows ruling out discrepancies when p-values aren’t small. This is more meaningful than power analysis, or taking non-significant results as uninformative. Most importantly, we obtain an evidential use of error probabilities: to assess how well or severely tested claims are. Allegations that frequentist measures, including p-values, must be misinterpreted to be evidentially relevant are scotched.
Biasing selection effects. We often hear it’s too easy to obtain small p-values, yet replication attempts find it difficult to get small p-values with preregistered results. This shows the problem isn’t p-values but failing to adjust them for cherry picking, multiple testing, post-data subgroups and other biasing selection effects. The ASA correctly warns that “[c]onducting multiple analyses of the data and reporting only those with certain p-values” leads to spurious p-values (Principle 4). The actual probability of erroneously finding significance with this gambit is not low, but high, so a reported small p-value is invalid. However, the same flexibility can occur with likelihood ratios, Bayes factors, and Bayesian updating, with one big difference: The direct grounds to criticize inferences as flouting error statistical control is lost (unless they are supplemented with principles that are not now standard). The reason is that they condition on the actual data; whereas error probabilities take into account other outcomes that could have occurred but did not.
The introduction of prior probabilities –which may also be data dependent–offers further leeway in determining if there has even been replication failure. Notice the problem with biasing selection effects isn’t about long-run error rates, it’s being unable to say that the case at hand has done a good job of avoiding misinterpretations.
Model validation. Many of the “other approaches” rely on statistical models that require “diagnostic checks and tests of fit which, I will argue, require frequentist theory significance tests for their formal justification” (Box 1983, p. 57), leading Box to advocate ecumenism. Echoes of Box may be found among holders of different statistical philosophies. “What we are advocating, then, is what Cox and Hinkley (1974) call ‘pure significance testing’, in which certain of the model’s implications are compared directly to the data…” (Gelman and Shalizi, p. 20).
We should oust recipe-like uses of p-values that have been long lampooned, but without understanding their valuable (if limited) roles, there’s a danger of blithely substituting “alternative measures of evidence” that throw out the error control baby with the bad statistics bathwater.
*I was a “philosophical observer” at one of the intriguing P-value ‘pow wows’, and was not involved in the writing of the document, except for some proposed changes. I thank Ron Wasserstein for inviting me.
[1] I thank Aris Spanos for very useful comments on earlier drafts.
RERERENCES
Birnbaum, A. (1970), “Statistical Methods in Scientific Inference (letter to the Editor),” Nature 225(5237): 1033.
Box, G. (1983), “An Apology for Ecumenism in Statistics,” in Scientific Inference, Data Analysis, and Robustness, eds. G. E. P. Box, T. Leonard, and D. F. J. Wu, New York: Academic Press, pp. 51-84.
Cox, D. and Hinkley, D. (1974), Theoretical Statistics, London: Chapman and Hall.
Gelman, A. and Shalizi, C. (2013), “Philosophy and the Practice of Bayesian Statistics” and “Rejoinder’” British Journal of Mathematical and Statistical Psychology 66(1): 8–38; 76-80.
Mayo, D. “Don’t Throw Out the Error Control Baby With the Bad Statistics Bathwater“(#15)
Mayo, D. G. and Cox, D. R. (2006), “Frequentists Statistics as a Theory of Inductive Inference,” in Optimality: The Second Erich L. Lehmann Symposium, ed. J. Rojo, Lecture Notes-Monograph series, Institute of Mathematical Statistics (IMS), Vol. 49: 77-97.
Mayo, D. G. and Spanos, A. (2006), “Severe Testing as a Basic Concept in a Neyman–Pearson Philosophy of Induction,” British Journal for the Philosophy of Science 57(2): 323–57.
Wasserstein and Lazar (2016), “The ASA’s Statement on p-Values: Context, Process, and Purpose”.Volume 70, 2016 – Issue 2


")


This is more meaningful than power analysis,
Not sure what you mean here? Power analysis is about the design of studies so that the results of a study are informative. Whether you then compute p-values, confidence intervals, or conduct some other inferential statistics is a different question. If a study has good power, all inferential tests will show stronger evidence for a real effect than a study with low power.
If you do not do a power analysis, how would you determine the sample size of your study?
Dr. R: I meant it is more meaningful for a post-data analysis. One still can uses power for planning, but that’s not all. For a contrast, see this post: https://errorstatistics.com/2016/07/21/nonsignificance-plus-high-power-does-not-imply-support-for-the-null-over-the-alternative/
I’ll return to this later.
Power is only defined for a specific effect size. We agree that observed power based on the sample effect size is not useful (Heisey & Hoenig, 2001) to draw inferences about H0.
Dr. R: H & H are talking about “shpower” (can search it on this blog). I compute Pr(d> do;H’) for various H’discrepancies from a test hypothesis.
Dr. R. Power isn’t only about design. N-P set out 3 roles for power: to plan sample size, compare different test, and interpret non-significant results. Only the third is post data. You can find this under Neyman and power on this blog.
Does anyone know why Senn calls dividing estimation and point testing? Surely dividing is testing.
I would say that of all the comments, Benjamini’s is the most spot on–that the ASA statement would terrify people off using tests, while encouraging other methods whose credentials haven’t been put to an ASA analysis. Having failed to recognize the proper role of statistical significance testing, while scaring people off their use, we see a growth of a third generation of quite bad arguments against error statistical methods in general. In this connection, it’s noteworthy that nowhere in the ASA doc, unless I missed it, is there mention of the role of significance tests in controlling and assessing error probabilities.
I have a very naive question – Mayo what is your definition of a statistical parameter? Do you only consider hypotheses stated in terms of identifiable parameters?
Om: No I’m not restricted to stat hyps (a smallish part of science and learning), but when it comes to stat hypotheses, I don’t have my own definition, it’s how the notion is used in stat. So, for ex., a non-parametric runs test would have hypothesis: IID satisfied, say, but is deemed non-parametric.
Thanks. I meant identifiable in the statistical sense – https://en.m.wikipedia.org/wiki/Identifiability
Om: Well there are two parts to your question, parameters and identifiable and the answer is no.
Do you have an example of your approach applied to a nonidentifiable problem? I’d be very interested to see one
Om: state your point if you have one. My approach includes entirely non-statistical hypotheses.
I ask because I think the issue is relevant re:what the assumptions included in the null hypothesis are