

Stephen Senn
Stephen Senn
Head of Competence Center for Methodology and Statistics (CCMS)
Luxembourg Institute of Health
Twitter @stephensenn
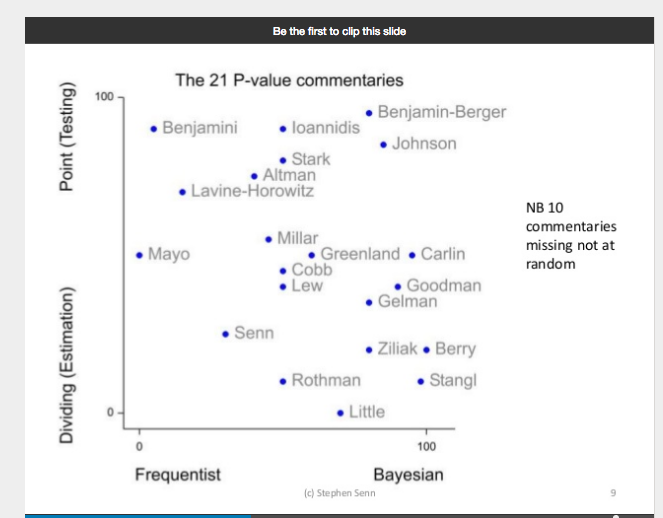
Automatic for the people? Not quite
What caught my eye was the estimable (in its non-statistical meaning) Richard Lehman tweeting about the equally estimable John Ioannidis. For those who don’t know them, the former is a veteran blogger who keeps a very cool and shrewd eye on the latest medical ‘breakthroughs’ and the latter a serial iconoclast of idols of scientific method. This is what Lehman wrote
Ioannidis hits 8 on the Richter scale: http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0173184 … Bayes factors consistently quantify strength of evidence, p is valueless.
Since Ioannidis works at Stanford, which is located in the San Francisco Bay Area, he has every right to be interested in earthquakes but on looking up the paper in question, a faint tremor is the best that I can afford it. I shall now try and explain why, but before I do, it is only fair that I acknowledge the very generous, prompt and extensive help I have been given to understand the paper[1] in question by its two authors Don van Ravenzwaaij and Ioannidis himself. Continue reading





















")

