I could have told them that the degree of accordance enabling the ASA’s “6 principles” on p-values was unlikely to be replicated when it came to most of the “other approaches” with which some would supplement or replace significance tests– notably Bayesian updating, Bayes factors, or likelihood ratios (confidence intervals are dual to hypotheses tests). [My commentary is here.] So now they may be advising a “hold off” or “go slow” approach until some consilience is achieved. Is that it? I don’t know. I was tweeted an article about the background chatter taking place behind the scenes; I wasn’t one of people interviewed for this. Here are some excerpts, I may add more later after it has had time to sink in. (check back later)
“Reaching for Best Practices in Statistics: Proceed with Caution Until a Balanced Critique Is In”
J. Hossiason
“[A]ll of the other approaches*, as well as most statistical tools, may suffer from many of the same problems as the p-values do. What level of likelihood ratio in favor of the research hypothesis will be acceptable to the journal? Should scientific discoveries be based on whether posterior odds pass a specific threshold (P3)? Does either measure the size of an effect (P5)?…How can we decide about the sample size needed for a clinical trial—however analyzed—if we do not set a specific bright-line decision rule? 95% confidence intervals or credence intervals…offer no protection against selection when only those that do not cover 0, are selected into the abstract (P4). (Benjamini, ASA commentary, pp. 3-4)
What’s sauce for the goose is sauce for the gander right? Many statisticians seconded George Cobb who urged “the board to set aside time at least once every year to consider the potential value of similar statements” to the recent ASA p-value report. Disappointingly, a preliminary survey of leaders in statistics, many from the original p-value group, aired striking disagreements on best and worst practices with respect to these other approaches. The Executive Board is contemplating a variety of recommendations, minimally, that practitioners move with caution until they can put forward at least a few agreed upon principles for interpreting and applying Bayesian inference methods. The words we heard ranged from “go slow” to “moratorium“ [emphasis mine]. Having been privy to some of the results of this survey, we at Stat Report Watch decided to contact some of the individuals involved. Continue reading →





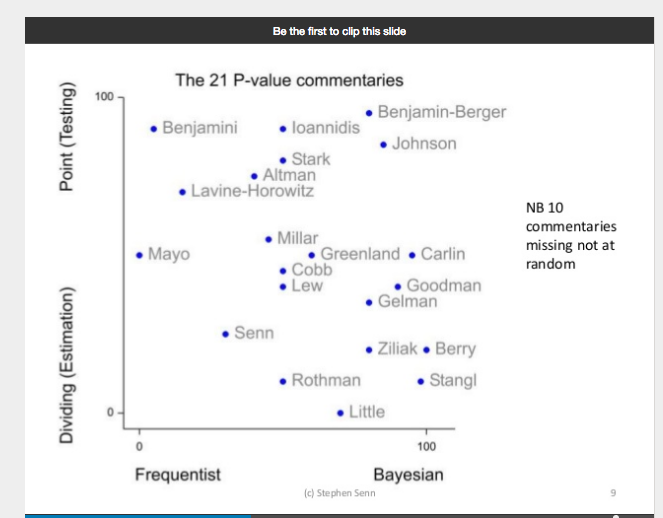
















")

