
![]() TSA to remove nudie scanners from airports. See Rejected Posts
TSA to remove nudie scanners from airports. See Rejected Posts
Author Archives: Mayo
New Kvetch/PhilStock
Categories: Rejected Posts
Leave a comment
Ontology & Methdology: Second call for Abstracts, Papers

Deadline for submission of (abstracts for) contributed papers*:
February 1, 2013
Dates of Conference: May 4-5, 2013
Blacksburg, Va
Special invited speakers:
David Danks (CMU), Peter Godfrey-Smith (CUNY), Kevin Hoover (Duke), Laura Ruetsche (U. Mich.), James Woodward (Pitt)
Virginia Tech speakers:
Benjamin Jantzen, Deborah Mayo, Lydia Patton, Aris Spanos
*Accommodation costs will be covered for accepted contributed papers.
- How do scientists’ initial conjectures about the entities and processes under their scrutiny influence the choice of variables, the structure of mature scientific theories, and methods of interpretation of those theories?
- How do methods of data generation, statistical modeling, and analysis influence the construction and appraisal of theories at multiple levels?
- How does historical analysis of the development of scientific theories illuminate the interplay between scientific methodology, theory building, and the interpretation of scientific theories?
This conference brings together prominent philosophers of science, biology, cognitive science, causation, economics, and physics with philosophically minded scientists engaged in research into these interconnected methodological and ontological questions.
We invite (extended abstracts for) contributed papers that illuminate these issues as they arise in general philosophy of science, in causal explanation and modeling, in the philosophy of experiment and statistics, and in the history and philosophy of science.
For further information on submitting a paper or extended abstract, please visit the conference website: http://www.ratiocination.org/OM2013/.
Organizers: Benjamin Jantzen, Deborah Mayo, Lydia Patton
Sponsors: The Virginia Tech Department of Philosophy and the Fund for Experimental Reasoning, Reliability, and the Objectivity and Rationality of Science (E.R.R.O.R.)
Categories: Announcement
Leave a comment
Aris Spanos: James M. Buchanan: a scholar, teacher and friend
 Aris Spanos
Aris Spanos
Wilson Schmidt Professor of Economics
Department of Economics, Virginia Tech
Although I have known of James M. Buchanan all of my academic career, I got to known him at a personal level as a colleague and a friend in 2000.
Looking back, our first meeting established the nature of our relationship since then. Jim walked into my office at Virginia Tech, and began to introduce himself. I felt somewhat uncomfortable and interrupted him, saying that I knew who he was. Of course he did not know who I was and asked me what area of economics I have been working in. I replied that I was ‘an econometrician, working with actual data aiming to learn about economic phenomena of interest using statistical modeling and inference’, and I hastened to add that our two areas of expertise were rather far apart. His immediate response took me by surprise: ‘From what I know, one cannot do statistical inference unless one’s data come from random samples, which is not the case in economics’. My reply was equally surprising to him: ‘Jim, where have you been for the last 50 years?’ I went on to elaborate that he was expressing an erroneous view that was held in economics in the 1930s. We spent the rest of that afternoon educating each other about our respective areas of expertise and discussing their potential overlap. Continue reading
Categories: Announcement, Statistics
Leave a comment
James M. Buchanan
 Yesterday, our colleague and friend, James Buchanan (Nobel prize-winner: 1986, Economics) died at 93.
Yesterday, our colleague and friend, James Buchanan (Nobel prize-winner: 1986, Economics) died at 93.
From a NY Times obit [that runs a full half page]:
[He] was a leading proponent of public choice theory, which assumes that politicians and government officials, like everyone else, are motivated by self-interest — getting re-elected or gaining more power — and do not necessarily act in the public interest… He argued that their actions could be analyzed, and even predicted, by applying the tools of economics to political science in ways that yield insights into the tendencies of governments to grow, increase spending, borrow money, run large deficits and let regulations proliferate. Continue reading
RCTs, skeptics, and evidence-based policy
Senn’s post led me to investigate some links to Ben Goldacre (author of “Bad Science” and “Bad Pharma”) and the “Behavioral Insights Team” in the UK. The BIT was “set up in July 2010 with a remit to find innovative ways of encouraging, ena bling and supporting people to make better choices for themselves.” A BIT blog is here”. A promoter of evidence-based public policy, Goldacre is not quite the scientific skeptic one might have imagined. What do readers think? (The following is a link from Goldacre’s Jan. 6 blog.)
bling and supporting people to make better choices for themselves.” A BIT blog is here”. A promoter of evidence-based public policy, Goldacre is not quite the scientific skeptic one might have imagined. What do readers think? (The following is a link from Goldacre’s Jan. 6 blog.)
Test, Learn, Adapt: Developing Public Policy with Randomised Controlled Trials
‘Test, Learn, Adapt’ is a paper which the Behavioural Insights Team* is publishing in collaboration with Ben Goldacre, author of Bad Science, and David Torgerson, Director of the University of York Trials Unit. The paper argues that Randomised Controlled Trials (RCTs), which are now widely used in medicine, international development, and internet-based businesses, should be used much more extensively in public policy. …The introduction of a randomly assigned control group enables you to compare the effectiveness of new interventions against what would have happened if you had changed nothing. RCTs are the best way of determining whether a policy or intervention is working. We believe that policymakers should begin using them much more systematically. Continue reading
Guest post: Bad Pharma? (S. Senn)
 Professor Stephen Senn*
Professor Stephen Senn*
Full Paper: Bad JAMA?
Short version–Opinion Article: Misunderstanding publication bias
Video below
Data filters
The student undertaking a course in statistical inference may be left with the impression that what is important is the fundamental business of the statistical framework employed: should one be Bayesian or frequentist, for example? Where does one stand as regards the likelihood principle and so forth? Or it may be that these philosophical issues are not covered but that a great deal of time is spent on the technical details, for example, depending on framework, various properties of estimators, how to apply the method of maximum likelihood, or, how to implement Markov chain Monte Carlo methods and check for chain convergence. However much of this work will take place in a (mainly) theoretical kingdom one might name simple-random-sample-dom. Continue reading
Severity Calculator

SEV calculator (with comparisons to p-values, power, CIs)
In the illustration in the Jan. 2 post,
H0: μ < 0 vs H1: μ > 0
and the standard deviation SD = 1, n = 25, so σx = SD/√n = .2
Setting α to .025, the cut-off for rejection is .39. (can round to .4).
Let the observed mean X = .2 , a statistically insignificant result (p value = .16)
SEV (μ < .2) = .5
SEV(μ <.3) = .7
SEV(μ <.4) = .84
SEV(μ <.5) = .93
SEV(μ <.6*) = .975
*rounding
Some students asked about crunching some of the numbers, so here’s a rather rickety old SEV calculator*. It is limited, rather scruffy-looking (nothing like the pretty visuals others post) but it is very useful. It also shows the Normal curves, how shaded areas change with changed hypothetical alternatives, and gives contrasts with confidence intervals. Continue reading
Categories: Severity, statistical tests
Leave a comment
Severity as a ‘Metastatistical’ Assessment
 Some weeks ago I discovered an error* in the upper severity bounds for the one-sided Normal test in section 5 of: “Statistical Science Meets Philosophy of Science Part 2” SS & POS 2. The published article has been corrected. The error was in section 5.3, but I am blogging all of 5.
Some weeks ago I discovered an error* in the upper severity bounds for the one-sided Normal test in section 5 of: “Statistical Science Meets Philosophy of Science Part 2” SS & POS 2. The published article has been corrected. The error was in section 5.3, but I am blogging all of 5.
(* μo was written where xo should have been!)
5. The Error-Statistical Philosophy
I recommend moving away, once and for all, from the idea that frequentists must ‘sign up’ for either Neyman and Pearson, or Fisherian paradigms. As a philosopher of statistics I am prepared to admit to supplying the tools with an interpretation and an associated philosophy of inference. I am not concerned to prove this is what any of the founders ‘really meant’.
Fisherian simple-significance tests, with their single null hypothesis and at most an idea of a directional alternative (and a corresponding notion of the ‘sensitivity’ of a test), are commonly distinguished from Neyman and Pearson tests, where the null and alternative exhaust the parameter space, and the corresponding notion of power is explicit. On the interpretation of tests that I am proposing, these are just two of the various types of testing contexts appropriate for different questions of interest. My use of a distinct term, ‘error statistics’, frees us from the bogeymen and bogeywomen often associated with ‘classical’ statistics, and it is to be hoped that that term is shelved. (Even ‘sampling theory’, technically correct, does not seem to represent the key point: the sampling distribution matters in order to evaluate error probabilities, and thereby assess corroboration or severity associated with claims of interest.) Nor do I see that my comments turn on whether one replaces frequencies with ‘propensities’ (whatever they are). Continue reading
Midnight With Birnbaum-reblog
 Reblogging Dec. 31, 2011:
Reblogging Dec. 31, 2011:
You know how in that recent movie, “Midnight in Paris,” the main character (I forget who plays it, I saw it on a plane) is a writer finishing a novel, and he steps into a cab that mysteriously picks him up at midnight and transports him back in time where he gets to run his work by such famous authors as Hemingway and Virginia Wolf? He is impressed when his work earns their approval and he comes back each night in the same mysterious cab…Well, imagine an error statistical philosopher is picked up in a mysterious taxi at midnight (New Year’s Eve 2011 2012) and is taken back fifty years and, lo and behold, finds herself in the company of Allan Birnbaum.[i]
ERROR STATISTICIAN: It’s wonderful to meet you Professor Birnbaum; I’ve always been extremely impressed with the important impact your work has had on philosophical foundations of statistics. I happen to be writing on your famous argument about the likelihood principle (LP). (whispers: I can’t believe this!)
BIRNBAUM: Ultimately you know I rejected the LP as failing to control the error probabilities needed for my Confidence concept.
ERROR STATISTICIAN: Yes, but I actually don’t think your argument shows that the LP follows from such frequentist concepts as sufficiency S and the weak conditionality principle WLP.[ii] Sorry,…I know it’s famous… Continue reading
Categories: Birnbaum Brakes, strong likelihood principle
Tags: Birnbaum, fallacious argument, Likelihood Principle, proofs
2 Comments
An established probability theory for hair comparison? “is not — and never was”
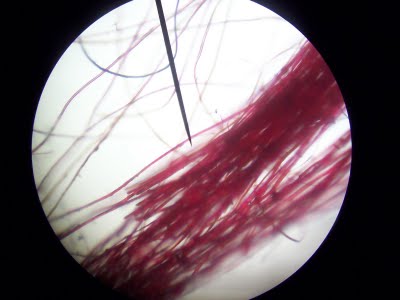
Hypothesis H: “person S is the source of this hair sample,” if indicated by a DNA match, has passed a more severe test than if it were indicated merely by a visual analysis under a microscopic. There is a much smaller probability of an erroneous hair match using DNA testing than using the method of visual analysis used for decades by the FBI.
The Washington Post reported on its latest investigation into flawed statistics behind hair match testimony. “Thousands of criminal cases at the state and local level may have relied on exaggerated testimony or false forensic evidence to convict defendants of murder, rape and other felonies”. Below is an excerpt of the Post article by Spencer S. Hsu.
I asked John Byrd, forensic anthropologist and follower of this blog, what he thought. It turns out that “hair comparisons do not have a well-supported weight of evidence calculation.” (Byrd). I put Byrd’s note at the end of this post. Continue reading
Categories: Severity, Statistics
14 Comments
3 msc kvetches on the blog bagel circuit

In the past week, I’ve kvetched over at 3 of the blogs on my blog bagel:
- I. On an error in Mark Chang’s treatment of my Birnbaum disproof on Xi’an’s Og.
- II. On Normal Deviant’s post offering “New Names For Statistical Methods”
- III. On a statistics chapter in Nate Silver’s book, discussed over at Gelman’s blog.
You may find some of them, with links, on Rejected Posts.
Categories: Metablog, Rejected Posts, Statistics
2 Comments
13 well-worn criticisms of significance tests (and how to avoid them)
 2013 is right around the corner, and here are 13 well-known criticisms of statistical significance tests, and how they are addressed within the error statistical philosophy, as discussed in Mayo, D. G. and Spanos, A. (2011) “Error Statistics“.
2013 is right around the corner, and here are 13 well-known criticisms of statistical significance tests, and how they are addressed within the error statistical philosophy, as discussed in Mayo, D. G. and Spanos, A. (2011) “Error Statistics“.
- (#1) error statistical tools forbid using any background knowledge.
- (#2) All statistically significant results are treated the same.
- (#3) The p-value does not tell us how large a discrepancy is found.
- (#4) With large enough sample size even a trivially small discrepancy from the null can be detected.
- (#5) Whether there is a statistically significant difference from the null depends on which is the null and which is the alternative.
- (#6) Statistically insignificant results are taken as evidence that the null hypothesis is true.
- (#7) Error probabilities are misinterpreted as posterior probabilities.
- (#8) Error statistical tests are justified only in cases where there is a very long (if not infinite) series of repetitions of the same experiment.
- (#9) Specifying statistical tests is too arbitrary.
- (#10) We should be doing confidence interval estimation rather than significance tests.
- (#11) Error statistical methods take into account the intentions of the scientists analyzing the data.
- (#12) All models are false anyway.
- (#13) Testing assumptions involves illicit data-mining.
You can read how we avoid them in the full paper here.
Mayo, D. G. and Spanos, A. (2011) “Error Statistics” in Philosophy of Statistics , Handbook of Philosophy of Science Volume 7 Philosophy of Statistics, (General editors: Dov M. Gabbay, Paul Thagard and John Woods; Volume eds. Prasanta S. Bandyopadhyay and Malcolm R. Forster.) Elsevier: 1-46.
Categories: Error Statistics, significance tests, Statistics
Tags: criticism of frequentist methods
Leave a comment
Msc kvetch: unfair but lawful discrimination (vs the irresistibly attractive)
 See rejected posts.
See rejected posts.
Categories: Rejected Posts
Leave a comment
Rejected Post: Clinical Trial Statistics Doomed by Mayan Apocalypse?
See Rejected Posts.
Categories: Rejected Posts, Statistics
Leave a comment
PhilStat/Law/Stock: more on “bad statistics”: Schachtman
 Nathan Schachtman has an update on the case of U.S. v. Harkonen discussed in my last 3 posts: here, here, and here.
Nathan Schachtman has an update on the case of U.S. v. Harkonen discussed in my last 3 posts: here, here, and here.
United States of America v. W. Scott Harkonen, MD — Part III
Background
The recent oral argument in United States v. Harkonen (see “The (Clinical) Trial by Franz Kafka” (Dec. 11, 2012)), pushed me to revisit the brief filed by the Solicitor General’s office in Matrixx Initiatives Inc. v. Siracusano, 131 S. Ct. 1309 (2011). One of Dr. Harkonen’s post-trial motions contended that the government’s failure to disclose its Matrixx amicus brief deprived him of a powerful argument that would have resulted from citing the language of the brief, which disparaged the necessity of statistical significance for “demonstrating” causal inferences. See “Multiplicity versus Duplicity – The Harkonen Conviction” (Dec. 11, 2012). Continue reading
Categories: PhilStatLaw, PhilStock, Statistics
Leave a comment
PhilStat/Law/Stock: multiplicity and duplicity
 So what’s the allegation that the prosecutors are being duplicitous about statistical evidence in the case discussed in my two previous (‘Bad Statistics’) posts? As a non-lawyer, I will ponder only the evidential (and not the criminal) issues involved.
So what’s the allegation that the prosecutors are being duplicitous about statistical evidence in the case discussed in my two previous (‘Bad Statistics’) posts? As a non-lawyer, I will ponder only the evidential (and not the criminal) issues involved.
“After the conviction, Dr. Harkonen’s counsel moved for a new trial on grounds of newly discovered evidence. Dr. Harkonen’s counsel hoisted the prosecutors with their own petards, by quoting the government’s amicus brief to the United States Supreme Court in Matrixx Initiatives Inc. v. Siracusano, 131 S. Ct. 1309 (2011). In Matrixx, the securities fraud plaintiffs contended that they need not plead ‘statistically significant’ evidence for adverse drug effects.” (Schachtman’s part 2, ‘The Duplicity Problem – The Matrixx Motion’)
The Matrixx case is another philstat/law/stock example taken up in this blog here, here, and here. Why are the Harkonen prosecutors “hoisted with their own petards” (a great expression, by the way)? Continue reading
PhilStat/Law (“Bad Statistics” Cont.)
As a philosopher of science and statistics, as well as a sometime trader in (those dangerous) biotech stocks, I realize that what is warranted inferentially need not follow what appears to be licensed/unlicensed by the straight and narrow path of officially sanctioned statistics. Understanding the background theories, history, detailed data, and assorted rulings are relevant for evidential grounds, which (despite what we might sometimes think) are rather different from legal grounds. (Grounds for stock trading decisions take one to yet a third and different world, but there are intersections). I only heard of the particular (Actimmune) episode mentioned in my previous blog entry from reading Schactman’s recent post[i], and have only a smattering of the background—some of which might shift the initial impressions of readers. As I’m about to leave London (not even time for a pic), I’ll just post the controversial press release itself, posted on (Dr. Barbara Martin’s) website PATHOPHILIA[ii]:
INTERMUNE ANNOUNCES PHASE III DATA DEMONSTRATING SURVIVAL BENEFIT OF ACTIMMUNE IN IPF
—Reduces Mortality by 70% in Patients with Mild to Moderate Disease— Continue reading
Categories: PhilStatLaw
Leave a comment
“Bad statistics”: crime or free speech?
 Hunting for “nominally” significant differences, trying different subgroups and multiple endpoints, can result in a much higher probability of erroneously inferring evidence of a risk or benefit than the nominal p-value, even in randomized controlled trials. This was an issue that arose in looking at RCTs in development economics (an area introduced to me by Nancy Cartwright), as at our symposium at the Philosophy of Science Association last month[i][ii]. Reporting the results of hunting and dredging in just the same way as if the relevant claims were predesignated can lead to misleading reports of actual significance levels.[iii]
Hunting for “nominally” significant differences, trying different subgroups and multiple endpoints, can result in a much higher probability of erroneously inferring evidence of a risk or benefit than the nominal p-value, even in randomized controlled trials. This was an issue that arose in looking at RCTs in development economics (an area introduced to me by Nancy Cartwright), as at our symposium at the Philosophy of Science Association last month[i][ii]. Reporting the results of hunting and dredging in just the same way as if the relevant claims were predesignated can lead to misleading reports of actual significance levels.[iii]
Still, even if reporting spurious statistical results is considered “bad statistics,” is it criminal behavior? I noticed this issue in Nathan Schachtman’s blog over the past couple of days. The case concerns a biotech company, InterMune, and its previous CEO, Dr. Harkonen. Here’s an excerpt from Schachtman’s discussion (part 1). Continue reading
Categories: PhilStatLaw, significance tests, spurious p values, Statistics
27 Comments
Mayo on S. Senn: “How Can We Cultivate Senn’s-Ability?”–reblogs
Since Stephen Senn will be leading our seminar at the LSE tomorrow morning (see PH500 page), I’m reblogging my deconstruction of his paper (“You May Believe You Are a Bayesian But You Probably Are Wrong”) from Jan.15 2012 (though not his main topic tomorrow). At the end I link to other “U-Phils” on Senn’s paper (by Andrew Gelman, Andrew Jaffe, Christian Robert), Senn’s response, and my response to them). Queries, write me at: error@vt.edu
Mayo Philosophizes on Stephen Senn: “How Can We Cultivate Senn’s-Ability?”

Where’s Mayo?
Although, in one sense, Senn’s remarks echo the passage of Jim Berger’s that we deconstructed a few weeks ago, Senn at the same time seems to reach an opposite conclusion. He points out how, in practice, people who claim to have carried out a (subjective) Bayesian analysis have actually done something very different—but that then they heap credit on the Bayesian ideal. (See also “Who Is Doing the Work?”)![]()
“A very standard form of argument I do object to is the one frequently encountered in many applied Bayesian papers where the first paragraphs laud the Bayesian approach on various grounds, in particular its ability to synthesize all sources of information, and in the rest of the paper the authors assume that because they have used the Bayesian machinery of prior distributions and Bayes theorem they have therefore done a good analysis. It is this sort of author who believes that he or she is Bayesian but in practice is wrong.” (Senn 58) Continue reading
Categories: Bayesian/frequentist, U-Phil
11 Comments

The Statistics Wars & Their Casualties

LSE PH500 Research Seminar (May 21-June 25, 2020): Controversies in Phil Stat
")
Summer Seminar 2019 (article)

Experts convene to explore new philosophy of statistics field
