
By: Nathan Schachtman, Esq., PC*
When the Supreme Court decided this case, I knew that some people would try to claim that it was a decision about the irrelevance or unimportance of statistical significance in assessing epidemiologic data. Indeed, the defense lawyers invited this interpretation by trying to connect materiality with causation. Having rejected that connection, the Supreme Court’s holding could address only materiality because causation was never at issue. It is a fundamental mistake to include undecided, immaterial facts as part of a court’s holding or the ratio decidendi of its opinion.
Interstitial Doubts About the Matrixx
Statistics professors are excited that the United States Supreme Court issued an opinion that ostensibly addressed statistical significance. One such example of the excitement is an article, in press, by Joseph B. Kadane, Professor in the Department of Statistics, in Carnegie Mellon University, Pittsburgh, Pennsylvania. See Joseph B. Kadane, “Matrixx v. Siracusano: what do courts mean by ‘statistical significance’?” 11[x] Law, Probability and Risk 1 (2011).
Professor Kadane makes the sensible point that the allegations of adverse events did not admit of an analysis that would imply statistical significance or its absence. Id. at 5. See Schachtman, “The Matrixx – A Comedy of Errors” (April 6, 2011)”; David Kaye, ” Trapped in the Matrixx: The U.S. Supreme Court and the Need for Statistical Significance,” BNA Product Safety and Liability Reporter 1007 (Sept. 12, 2011). Unfortunately, the excitement has obscured Professor Kadane’s interpretation of the Court’s holding, and has led him astray in assessing the importance of the case. Continue reading →

 ader: My commentary, “How Can We Cultivate Senn’s Ability, Comment on Stephen Senn, ‘You May Believe You are a Bayesian But You’re Probably Wrong’” and Senn’s, “Names and Games, A Reply to Deborah G. Mayo” have been published under the Discussion Section of Rationality, Markets, and Morals.(Special Topic: Statistical Science and Philosophy of Science: Where Do/Should They Meet?”)
ader: My commentary, “How Can We Cultivate Senn’s Ability, Comment on Stephen Senn, ‘You May Believe You are a Bayesian But You’re Probably Wrong’” and Senn’s, “Names and Games, A Reply to Deborah G. Mayo” have been published under the Discussion Section of Rationality, Markets, and Morals.(Special Topic: Statistical Science and Philosophy of Science: Where Do/Should They Meet?”) Gelman responds on his blog today: “Gelman on
Gelman responds on his blog today: “Gelman on “
“

 Nathan Schactman has an interesting blog post on “
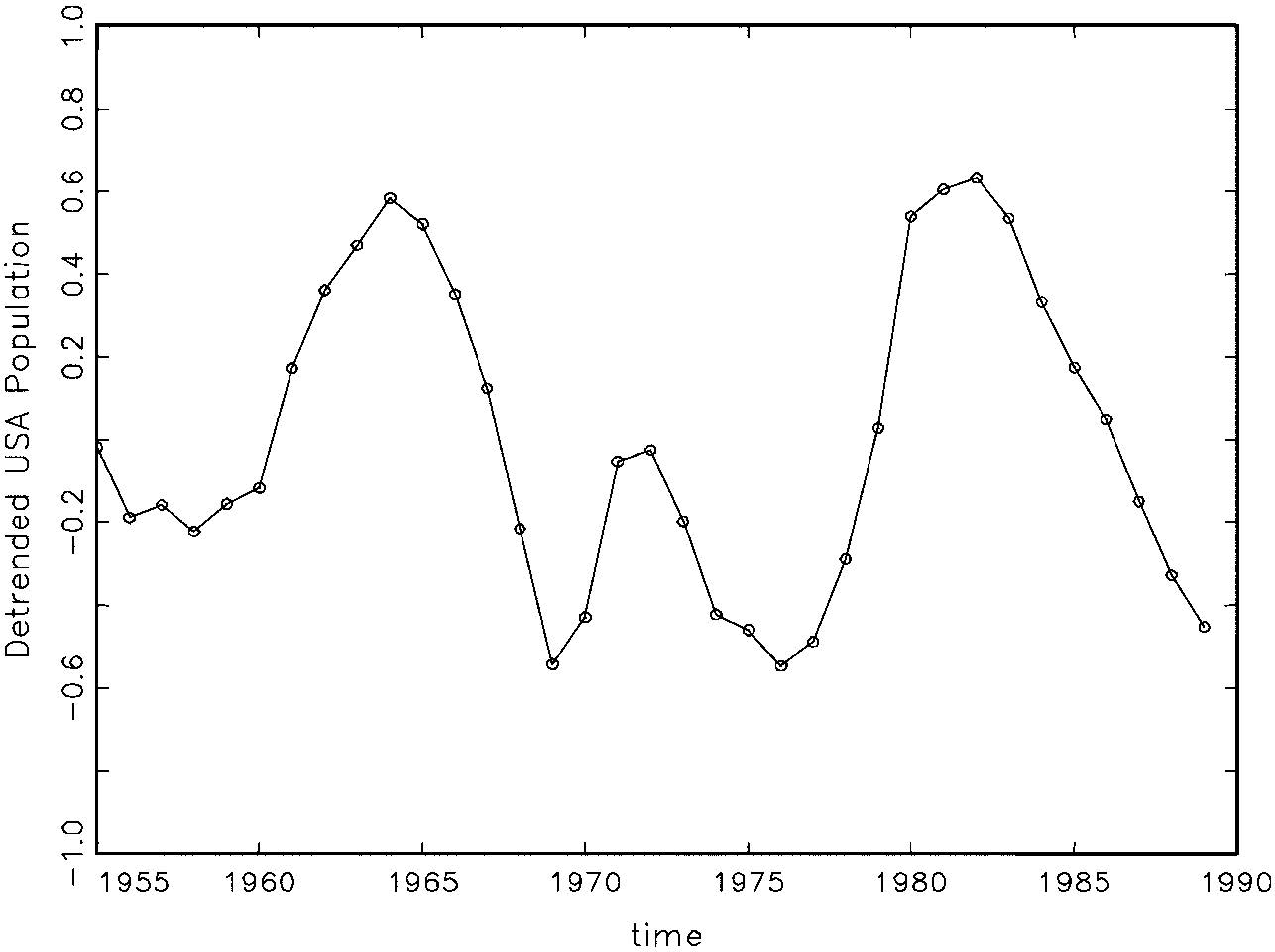
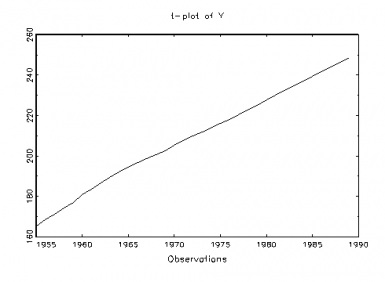
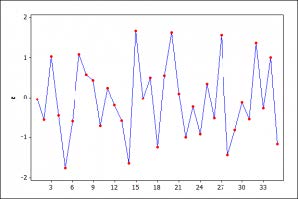
Nathan Schactman has an interesting blog post on “ The Nature of the Inferences From Graphical Techniques: What is the status of the learning from graphs? In this view, the graphs afford good ideas about the kinds of violations for which it would be useful to probe, much as looking at a forensic clue (e.g., footprint, tire track) helps to narrow down the search for a given suspect, a fault-tree, for a given cause. The same discernment can be achieved with a formal analysis (with parametric and nonparametric tests), perhaps more discriminating than can be accomplished by even the most trained eye, but the reasoning and the justification are much the same. (The capabilities of these techniques may be checked by simulating data deliberately generated to violate or obey the various assumptions.)
The Nature of the Inferences From Graphical Techniques: What is the status of the learning from graphs? In this view, the graphs afford good ideas about the kinds of violations for which it would be useful to probe, much as looking at a forensic clue (e.g., footprint, tire track) helps to narrow down the search for a given suspect, a fault-tree, for a given cause. The same discernment can be achieved with a formal analysis (with parametric and nonparametric tests), perhaps more discriminating than can be accomplished by even the most trained eye, but the reasoning and the justification are much the same. (The capabilities of these techniques may be checked by simulating data deliberately generated to violate or obey the various assumptions.)















")

