Kent Staley has written a clear and engaging introduction to PhilSci that manages to blend the central key topics of philosophy of science with current philosophy of statistics. Quite possibly, Staley explains Error Statistics more clearly in many ways than I do in his 10 page section, 9.4. CONGRATULATIONS STALEY*
You can get this book for free by merely writing one of the simpler palindrome’s in the December contest.
Here’s an excerpt from that section:
Staley
9.4 Error-statistical philosophy of science and severe testing
Deborah Mayo has developed an alternative approach to the interpretation of frequentist statistical inference (Mayo 1996). But the idea at the heart of Mayo’s approach is one that can be stated without invoking probability at all. ….
Mayo takes the following “minimal scientific principle for evidence” to be uncontroversial:
Principle 3 (Minimal principle for evidence) Data xo provide poor evidence for H if they result from a method or procedure that has little or no ability of finding flaws in H, even if H is false.(Mayo and Spanos, 2009, 3) Continue reading →
S. Stanley Young, PhD Assistant Director Bioinformatics National Institute of Statistical Sciences Research Triangle Park, NC
Are there mortality co-benefits to the Clean Power Plan? It depends.
Some years ago, I listened to a series of lectures on finance. The professor would ask a rhetorical question, pause to give you some time to think, and then, more often than not, answer his question with, “It depends.” Are there mortality co-benefits to the Clean Power Plan? Is mercury coming from power plants leading to deaths? Well, it depends.
So, rhetorically, is an increase in CO2 a bad thing? There is good and bad in everything. Well, for plants an increase in CO2 is a good thing. They grow faster. They convert CO2 into more food and fiber. They give off more oxygen, which is good for humans. Plants appear to be CO2 starved.
It is argued that CO2 is a greenhouse gas and an increase in CO2 will raise temperatures, ice will melt, sea levels will rise, and coastal area will flood, etc. It depends. In theory yes, in reality, maybe. But a lot of other events must be orchestrated simultaneously. Obviously, that scenario depends on other things as, for the last 18 years, CO2 has continued to go up and temperatures have not. So it depends on other factors, solar radiance, water vapor, El Nino, sun spots, cosmic rays, earth presession, etc., just what the professor said.
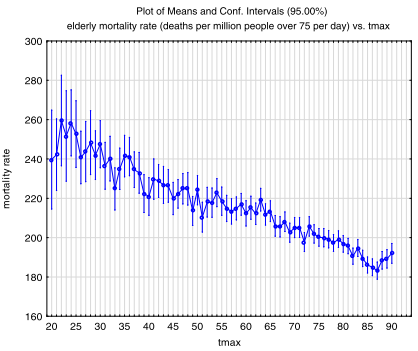
So suppose ambient temperatures do go up a few degrees. On balance, is that bad for humans? The evidence is overwhelming that warmer is better for humans. One or two examples are instructive. First, Cox et al., (2013) with the title, “Warmer is healthier: Effects on mortality rates of changes in average fine particulate matter (PM2.5) concentrations and temperatures in 100 U.S. cities.” To quote from the abstract of that paper, “Increases in average daily temperatures appear to significantly reduce average daily mortality rates, as expected from previous research.” Here is their plot of daily mortality rate versus Max temperature. It is clear that as the maximum temperature in a city goes up, mortality goes down. So if the net effect of increasing CO2 is increasing temperature, there should be a reduction in deaths. Continue reading →
1. What does it mean for a debate to be “media driven” or a battle to be “lost by the media”?In my last post, I noted that until a few weeks ago, I’d never heard of a “power morcellator.” Nor had I heard of the AAGL–The American Association of Gynecologic Laparoscopists. In an article “Battle over morcellation lost ‘in the media’”(Nov 26, 2014) Susan London reports on a recent meeting of the AAGL[i]
The media played a major role in determining the fate of uterine morcellation, suggested a study reported at a meeting sponsored by AAGL.
“How did we lose this battle of uterine morcellation? We lost it in the media,” asserted lead investigator Dr. Adrian C. Balica, director of the minimally invasive gynecologic surgery program at the Robert Wood Johnson Medical School in New Brunswick, N.J.
The “investigation” Balica led consisted of collecting Internet search data using something called the Google Adwords Keyword Planner:
Results showed that the average monthly number of Google searches for the term ‘morcellation’ held steady throughout most of 2013 at about 250 per month, reported Dr. Balica. There was, however, a sharp uptick in December 2013 to more than 2,000 per month, and the number continued to rise to a peak of about 18,000 per month in July 2014. A similar pattern was seen for the terms ‘morcellator,’ ‘fibroids in uterus,’ and ‘morcellation of uterine fibroid.’
The “vitals” of the study are summarized at the start of the article:
Key clinical point: Relevant Google searches rose sharply as the debate unfolded.
Major finding: The mean monthly number of searches for “morcellation” rose from about 250 in July 2013 to 18,000 in July 2014.
Data source: An analysis of Google searches for terms related to the power morcellator debate.
Disclosures: Dr. Balica disclosed that he had no relevant conflicts of interest.
2. Here’s my question: Does a high correlation between Google searches and debate-related terms signify that the debate is “media driven”? I suppose you could call it that, but Dr. Balica is clearly suggesting that something not quite kosher, or not fully factual was responsible for losing “this battle of uterine morcellation”, downplaying the substantial data and real events that drove people (like me) to search the terms upon hearing the FDA announcement in November.Continue reading →
Until a few weeks ago, I’d never even heard of a “power morcellator.” Nor was I aware of the controversy that has pitted defenders of a woman’s right to choose a minimally invasive laparoscopic procedure in removing fibroids—enabled by the power morcellator–and those who decry the danger it poses in spreading an undetected uterine cancer throughout a woman’s abdomen. The most outspoken member of the anti-morcellation group is surgeon Hooman Noorchashm. His wife, Dr. Amy Reed, had a laparoscopic hysterectomy that resulted in morcellating a hidden cancer, progressing it to Stage IV sarcoma. Below is their video (link is here), followed by a recent FDA warning. I may write this in stages or parts. (I will withhold my view for now, I’d like to know what you think.)
Product: Laparoscopic power morcellators are medical devices used during different types of laparoscopic (minimally invasive) surgeries. These can include certain procedures to treat uterine fibroids, such as removing the uterus (hysterectomy) or removing the uterine fibroids (myomectomy). Morcellation refers to the division of tissue into smaller pieces or fragments and is often used during laparoscopic surgeries to facilitate the removal of tissue through small incision sites.
Purpose: When used for hysterectomy or myomectomy in women with uterine fibroids, laparoscopic power morcellation poses a risk of spreading unsuspected cancerous tissue, notably uterine sarcomas, beyond the uterus. The FDA is warning against using laparoscopic power morcellators in the majority of women undergoing hysterectomy or myomectomy for uterine fibroids. Health care providers and patients should carefully consider available alternative treatment options for the removal of symptomatic uterine fibroids.
Summary of Problem and Scope: Uterine fibroids are noncancerous growths that develop from the muscular tissue of the uterus. Most women will develop uterine fibroids (also called leiomyomas) at some point in their lives, although most cause no symptoms1. In some cases, however, fibroids can cause symptoms, including heavy or prolonged menstrual bleeding, pelvic pressure or pain, and/or frequent urination, requiring medical or surgical therapy.
Many women choose to undergo laparoscopic hysterectomy or myomectomy because these procedures are associated with benefits such as a shorter post-operative recovery time and a reduced risk of infection compared to abdominal hysterectomy and myomectomy2. Many of these laparoscopic procedures are performed using a power morcellator.
Based on an FDA analysis of currently available data, we estimate that approximately 1 in 350 women undergoing hysterectomy or myomectomy for the treatment of fibroids is found to have an unsuspected uterine sarcoma, a type of uterine cancer that includes leiomyosarcoma. At this time, there is no reliable method for predicting or testing whether a woman with fibroids may have a uterine sarcoma.
If laparoscopic power morcellation is performed in women with unsuspected uterine sarcoma, there is a risk that the procedure will spread the cancerous tissue within the abdomen and pelvis, significantly worsening the patient’s long-term survival. While the specific estimate of this risk may not be known with certainty, the FDA believes that the risk is higher than previously understood. Continue reading →
Below are the slides from my Rutgers seminar for the Department of Statistics and Biostatistics yesterday, since some people have been asking me for them. The abstract is here. I don’t know how explanatory a bare outline like this can be, but I’d be glad to try and answer questions[i]. I am impressed at how interested in foundational matters I found the statisticians (both faculty and students) to be. (There were even a few philosophers in attendance.) It was especially interesting to explore, prior to the seminar, possible connections between severity assessments and confidence distributions, where the latter are along the lines of Min-ge Xie (some recent papers of his may be found here.)
“Probing with Severity: Beyond Bayesian Probabilism and Frequentist Performance”
[i]They had requested a general overview of some issues in philosophical foundations of statistics. Much of this will be familiar to readers of this blog.
I’ll be talking about philosophy of statistics tomorrow afternoon at Rutgers University, in the Statistics and Biostatistics Department, if you happen to be in the vicinity and are interested.
RUTGERS UNIVERSITY DEPARTMENT OF STATISTICS AND BIOSTATISTICS www.stat.rutgers.edu
Seminar Speaker: Professor Deborah Mayo, Virginia Tech
Title: Probing with Severity: Beyond Bayesian Probabilism and Frequentist Performance
Time: 3:20 – 4:20pm, Wednesday, December 3, 2014 Place: 552 Hill Center
ABSTRACT
Probing with Severity: Beyond Bayesian Probabilism and Frequentist Performance Getting beyond today’s most pressing controversies revolving around statistical methods, I argue, requires scrutinizing their underlying statistical philosophies.Two main philosophies about the roles of probability in statistical inference are probabilism and performance (in the long-run). The first assumes that we need a method of assigning probabilities to hypotheses; the second assumes that the main function of statistical method is to control long-run performance. I offer a third goal: controlling and evaluating the probativeness of methods. An inductive inference, in this conception, takes the form of inferring hypotheses to the extent that they have been well or severely tested. A report of poorly tested claims must also be part of an adequate inference. I develop a statistical philosophy in which error probabilities of methods may be used to evaluate and control the stringency or severity of tests. I then show how the “severe testing” philosophy clarifies and avoids familiar criticisms and abuses of significance tests and cognate methods (e.g., confidence intervals). Severity may be threatened in three main ways: fallacies of statistical tests, unwarranted links between statistical and substantive claims, and violations of model assumptions.
MONTHLY MEMORY LANE: 3 years ago: November 2011. I mark in red 3 posts that seem most apt for general background on key issues in this blog.*
(11/1)RMM-4:“Foundational Issues in Statistical Modeling: Statistical Model Specification and Validation*” by Aris Spanos, in Rationality, Markets, and Morals (Special Topic: Statistical Science and Philosophy of Science: Where Do/Should They Meet?”)
(11/21) RMM-5: “Low Assumptions, High Dimensions” by Larry Wasserman, in Rationality, Markets, and Morals (Special Topic: Statistical Science and Philosophy of Science: Where Do/Should They Meet?”) See also my deconstruction of Larry Wasserman.
(11/23) Elbar Grease: Return to the Comedy Hour at the Bayesian Retreat
(11/28) The UN Charter: double-counting and data snooping
*I announced this new, once-a-month feature at the blog’s 3-year anniversary. I will repost and comment on one of the 3-year old posts from time to time. [I’ve yet to repost and comment on the one from Oct. 2011, but will shortly.] For newcomers, here’s your chance to catch-up; for old timers,this is philosophy: rereading is essential!
I insist on point against point, no matter how much it hurts
Have you ever noticed that some leading advocates of a statistical account, say a testing account A, upon discovering account A is unable to handle a certain kind of important testing problem that a rival testing account, account B, has no trouble at all with, will mount an argument that being able to handle that kind of problem is actually a bad thing? In fact, they might argue that testing account B is not a “real” testing account because it can handle such a problem? You have? Sure you have, if you read this blog. But that’s only a subliminal point of this post.
I’ve had three posts recently on the Law of Likelihood (LL): Breaking the [LL](a)(b), [c], and [LL] is bankrupt. Please read at least one of them for background. All deal with Royall’s comparative likelihoodist account, which some will say only a few people even use, but I promise you that these same points come up again and again in foundational criticisms from entirely other quarters.[i]
An example from Royall is typical: He makes it clear that an account based on the (LL) is unable to handle composite tests, even simple one-sided tests for which account B supplies uniformly most powerful (UMP) tests. He concludes, not that his test comes up short, but that any genuine test or ‘rule of rejection’ must have a point alternative! Here’s the case (Royall, 1997, pp. 19-20):
[M]edical researchers are interested in the success probability, θ, associated with a new treatment. They are particularly interested in how θ relates to the old treatment’s success probability, believed to be about 0.2. They have reason to hope θ is considerably greater, perhaps 0.8 or even greater. To obtain evidence about θ, they carry out a study in which the new treatment is given to 17 subjects, and find that it is successful in nine.
Let me interject at this point that of all of Stephen Senn’s posts on this blog, my favorite is the one where he zeroes in on the proper way to think about the discrepancy we hope to find (the .8 in this example). (See note [ii]) Continue reading →
A NYT op-ed the other day,”How Medical Care Is Being Corrupted” (by Pamela Hartzband and Jerome Groopman, physicians on the faculty of Harvard Medical School), gives a good sum-up of what I fear is becoming the new normal, even under so-called “personalized medicine”.
“It is obsolete for the doctor to approach each patient strictly as an individual; medical decisions should be made on the basis of what is best for the population as a whole.”
Remember that when they tell you you’re getting your very own, individualized, custom-tailored, personalized medicine!
I see a future role for independent experts in medicine and medical statistics to whom individuals and consumer groups could turn to get the real scoop, as well as to critically assess the statistics of any clinical trials that bear upon their treatment decisions.(Remember the Potti case.) No wonder I hear of so many doctors getting out of the field. Perhaps some of them,along with interested medical statisticians, can put out their shingle for a company of advisors. I don’t see this as far-fetched [i]
WHEN we are patients, we want our doctors to make recommendations that are in our best interests as individuals. As physicians, we strive to do the same for our patients.
But financial forces largely hidden from the public are beginning to corrupt care and undermine the bond of trust between doctors and patients. Insurers, hospital networks and regulatory groups have put in place both rewards and punishments that can powerfully influence your doctor’s decisions.
Erich Lehmann 20 November 1917 – 12 September 2009
Memory Lane 1 Year(with update): Today is Erich Lehmann’s birthday. The last time I saw him was at the Second Lehmann conference in 2004, at which I organized a session on philosophical foundations of statistics (including David Freedman and D.R. Cox).
I got to know Lehmann, Neyman’s first student, in 1997. One day, I received a bulging, six-page, handwritten letter from him in tiny, extremely neat scrawl (and many more after that). He told me he was sitting in a very large room at an ASA meeting where they were shutting down the conference book display (or maybe they were setting it up), and on a very long, dark table sat just one book, all alone, shiny red. He said he wondered if it might be of interest to him! So he walked up to it…. It turned out to be my Error and the Growth of Experimental Knowledge (1996, Chicago), which he reviewed soon after. Some related posts on Lehmann’s letter are here and here.
That same year I remember having a last-minute phone call with Erich to ask how best to respond to a “funny Bayesian example” raised by Colin Howson. It is essentially the case of Mary’s positive result for a disease, where Mary is selected randomly from a population where the disease is very rare. See for example here. (It’s just like the case of our high school student Isaac). His recommendations were extremely illuminating, and with them he sent me a poem he’d written (which you can read in my published response here*). Aside from being a leading statistician, Erich had a (serious) literary bent. Continue reading →
There was a session at the Philosophy of Science Association meeting last week where two of the speakers, Greg Gandenberger and Jiji Zhang had insightful things to say about the “Law of Likelihood” (LL)[i]. Recall from recent posts here and here that the (LL) regards data x as evidence supporting H1 over H0 iff
Pr(x; H1) > Pr(x; H0).
On many accounts, the likelihood ratio also measures the strength of that comparative evidence. (Royall 1997, p.3). [ii]
H0 andH1 are statistical hypothesis that assign probabilities to the random variable X taking value x.As I recall, the speakers limited H1 and H0 to simple statistical hypotheses (as Richard Royall generally does)–already restricting the account to rather artificial cases, but I put that to one side. Remember, with likelihoods, the data x are fixed, the hypotheses vary.
1. Maximally likely alternatives. I didn’t really disagree with anything the speakers said. I welcomed their recognition that a central problem facing the (LL) is the ease of constructing maximally likely alternatives: so long as Pr(x; H0) < 1, a maximum likely alternative H1 would be evidentially “favored”. There is no onus on the likelihoodist to predesignate the rival, you are free to search, hunt, post-designate and construct a best (or better) fitting rival. If you’re bothered by this, says Royall, then this just means the evidence disagrees with your prior beliefs.
After all, Royall famously distinguishes between evidence and belief (recall the evidence-belief-action distinction), and these problematic cases, he thinks, do not vitiate his account as an account of evidence. But I think they do! In fact, I think they render the (LL) utterly bankrupt as an account of evidence. Here are a few reasons. (Let me be clear that I am not pinning Royall’s defense on the speakers[iii], so much as saying it came up in the general discussion[iv].) Continue reading →
[Statistical debate] “often boils down to this: is the question that you have asked in applying your statistical method the most even-handed, the most open-minded, the most unbiased question that you could possibly ask?
It’s not asking whether someone made a mathematical mistake. It is asking whether they cheated — whether they adjusted the rules unfairly — and biased the answer through the question they chose…”
(Nov. 2014):I am impressed (i.e., struck by the fact) that he goes so far as to call it “cheating”. Anyway, here is the rest of the reblog from Strassler which bears on a number of recent discussions:
“…If there are 23 people in a room, the chance that two of them have the same birthday is 50 percent, while the chance that two of them were born on a particular day, say, January 1st, is quite low, a small fraction of a percent. The more you specify the coincidence, the rarer it is; the broader the range of coincidences at which you are ready to express surprise, the more likely it is that one will turn up.Continue reading →
The NY Times Magazine had a feature on the Amazing Randi yesterday, “The Unbelievable Skepticism of the Amazing Randi.” It described one of the contestants in Randi’s most recent Million Dollar Challenge, Fei Wang:
“[Wang] claimed to have a peculiar talent: from his right hand, he could transmit a mysterious force a distance of three feet, unhindered by wood, metal, plastic or cardboard. The energy, he said, could be felt by others as heat, pressure, magnetism or simply “an indescribable change.” Tonight, if he could demonstrate the existence of his ability under scientific test conditions, he stood to win $1 million.”
Isn’t “an indescribable change” rather vague?
…..The Challenge organizers had spent weeks negotiating with Wang and fine-tuning the protocol for the evening’s test. A succession of nine blindfolded subjects would come onstage and place their hands in a cardboard box. From behind a curtain, Wang would transmit his energy into the box. If the subjects could successfully detect Wang’s energy on eight out of nine occasions, the trial would confirm Wang’s psychic power. …”
After two women failed to detect the “mystic force” the M.C. announced the contest was over.
“With two failures in a row, it was impossible for Wang to succeed. The Million Dollar Challenge was already over.”
You think they might have given him another chance or something.
“Stepping out from behind the curtain, Wang stood center stage, wearing an expression of numb shock, like a toddler who has just dropped his ice cream in the sand. He was at a loss to explain what had gone wrong; his tests with a paranormal society in Boston had all succeeded. Nothing could convince him that he didn’t possess supernatural powers. ‘This energy is mysterious,’ he told the audience. ‘It is not God.’ He said he would be back in a year, to try again.”
The article is here. If you don’t know who A. Randi is, you should read it.
Randi, much better known during Uri Geller spoon-bending days, has long been the guru to skeptics and fraudbusters, but also a hero to some critical psi believers like I.J. Good. Geller continually sued Randi for calling him a fraud. As such, I.J. Good warned me that I might be taking a risk in my use of “gellerization” in EGEK (1996), but I guess Geller doesn’t read philosophy of science. A post on “Statistics and ESP Research” and Diaconis is here.
I’d love to have seen Randi break out of these chains!
We had an excellent discussion at our symposium yesterday: “How Many Sigmas to Discovery? Philosophy and Statistics in the Higgs Experiments” with Robert Cousins, Allan Franklin and Kent Staley. Slides from my presentation, “Statistical Flukes, the Higgs Discovery, and 5 Sigma” are posted below (we each only had 20 minutes, so this is clipped,but much came out in the discussion). Even the challenge I read about this morning as to what exactly the Higgs researchers discovered (and I’ve no clue if there’s anything to the idea of a “techni-higgs particle”) — would not invalidate* the knowledge of the experimental effects severely tested.
*Although, as always, there may be a reinterpretation of the results. But I think the article is an isolated bit of speculation. I’ll update if I hear more.
Philosophy and Statistics in the Higgs Experiments
on Nov.8 with Robert Cousins, Allan Franklin, and Kent Staley. If you’re in the neighborhood stop by.
Summary
“A 5 sigma effect!” is how the recent Higgs boson discovery was reported. Yet before the dust had settled, the very nature and rationale of the 5 sigma (or 5 standard deviation) discovery criteria began to be challenged and debated both among scientists and in the popular press. Why 5 sigma? How is it to be interpreted? Do p-values in high-energy physics (HEP) avoid controversial uses and misuses of p-values in social and other sciences? The goal of our symposium is to combine the insights of philosophers and scientists whose work interrelates philosophy of statistics, data analysis and modeling in experimental physics, with critical perspectives on how discoveries proceed in practice. Our contributions will link questions about the nature of statistical evidence, inference, and discovery with questions about the very creation of standards for interpreting and communicating statistical experiments. We will bring out some unique aspects of discovery in modern HEP. We also show the illumination the episode offers to some of the thorniest issues revolving around statistical inference, frequentist and Bayesian methods, and the philosophical, technical, social, and historical dimensions of scientific discovery.
Questions:
1) How do philosophical problems of statistical inference interrelate with debates about inference and modeling in high energy physics (HEP)?
2) Have standards for scientific discovery in particle physics shifted? And if so, how has this influenced when a new phenomenon is “found”?
3) Can understanding the roles of statistical hypotheses tests in HEP resolve classic problems about their justification in both physical and social sciences?
4) How do pragmatic, epistemic and non-epistemic values and risks influence the collection, modeling, and interpretation of data in HEP?
Abstracts for Individual Presentations
(1) Unresolved Philosophical Issues Regarding Hypothesis Testing in High Energy Physics Robert D. Cousins. Professor, Department of Physics and Astronomy, University of California, Los Angeles (UCLA)
The discovery and characterization of a Higgs boson in 2012-2013 provide multiple examples of statistical inference as practiced in high energy physics (elementary particle physics). The main methods employed have a decidedly frequentist flavor, drawing in a pragmatic way on both Fisher’s ideas and the Neyman-Pearson approach. A physics model being tested typically has a “law of nature” at its core, with parameters of interest representing masses, interaction strengths, and other presumed “constants of nature”. Additional “nuisance parameters” are needed to characterize the complicated measurement processes. The construction of confidence intervals for a parameter of interest q is dual to hypothesis testing, in that the test of the null hypothesis q=q0 at significance level (“size”) a is equivalent to whether q0 is contained in a confidence interval for q with confidence level (CL) equal to 1-a. With CL or a specified in advance (“pre-data”), frequentist coverage properties can be assured, at least approximately, although nuisance parameters bring in significant complications. With data in hand, the post-data p-value can be defined as the smallest significance level a at which the null hypothesis would be rejected, had that a been specified in advance. Carefully calculated p-values (not assuming normality) are mapped onto the equivalent number of standard deviations (“s”) in a one-tailed test of the mean of a normal distribution. For a discovery such as the Higgs boson, experimenters report both p-values and confidence intervals of interest. Continue reading →
Memory Lane: 3 years ago.Oxford Jail (also called Oxford Castle) is an entirely fitting place to be on (and around) Halloween! Moreover, rooting around this rather lavish set of jail cells (what used to be a single cell is now a dressing room) is every bit as conducive to philosophical reflection as is exile on Elba! (It is now a boutique hotel, though many of the rooms are still too jail-like for me.) My goal (while in this gaol—as the English sometimes spell it) is to try and free us from the bogeymen and bogeywomen often associated with “classical” statistics. As a start, the very term “classical statistics” should, I think, be shelved, not that names should matter.
In appraising statistical accounts at the foundational level, we need to realize the extent to which accounts are viewed through the eyeholes of a mask or philosophical theory. Moreover, the mask some wear while pursuing this task might well be at odds with their ordinary way of looking at evidence, inference, and learning. In any event, to avoid non-question-begging criticisms, the standpoint from which the appraisal is launched must itself be independently defended. But for (most) Bayesian critics of error statistics the assumption that uncertain inference demands a posterior probability for claims inferred is thought to be so obvious as not to require support. Critics are implicitly making assumptions that are at odds with the frequentist statistical philosophy. In particular, they assume a certain philosophy about statistical inference (probabilism), often coupled with the allegation that error statistical methods can only achieve radical behavioristic goals, wherein all that matters are long-run error rates (of some sort)
Criticisms then follow readily: the form of one or both:
Error probabilities do not supply posterior probabilities in hypotheses, interpreted as if they do (and some say we just can’t help it), they lead to inconsistencies
Methods with good long-run error rates can give rise to counterintuitive inferences in particular cases.
I have proposed an alternative philosophy that replaces these tenets with different ones:
the role of probability in inference is to quantify how reliably or severely claims (or discrepancies from claims) have been tested
the severity goal directs us to the relevant error probabilities, avoiding the oft-repeated statistical fallacies due to tests that are overly sensitive, as well as those insufficiently sensitive to particular errors.
Control of long run error probabilities, while necessary is not sufficient for good tests or warranted inferences.
Bioethicist Arthur Caplan gives “7 Reasons Ebola Quarantine Is a Bad, Bad Idea”.I’m interested to know what readers think (I claim no expertise in this area.) My occasional comments are in maroon.
“Bioethicist: 7 Reasons Ebola Quarantine Is a Bad, Bad Idea”
BY ARTHUR CAPLAN
In the fight against Ebola some government officials in the U.S. are now managing fear, not the virus. Quarantines have been declared in New York, New Jersey and Illinois. In Connecticut, nine people are in quarantine: two students at Yale; a worker from AmeriCARES; and a West African family.
Many others are or soon will be.
Quarantining those who do not have symptoms is not the way to combat Ebola. In fact it will only make matters worse. Far worse. Why?
Quarantining people without symptoms makes no scientific sense.
They are not infectious. The only way to get Ebola is to have someone vomit on you, bleed on you, share spit with you, have sex with you or get fecal matter on you when they have a high viral load.
How do we know this?
Because there is data going back to 1975 from outbreaks in the Congo, Uganda, Sudan, Gabon, Ivory Coast, South Africa, not to mention current experience in the United States, Spain and other nations.
The list of “the only way to get Ebola” does not suggest it is so extraordinarily difficult to transmit as to imply the policy “makes no scientific sense”. That there is “data going back to 1975” doesn’t tell us how it was analyzed. They may not be infectious today, but…
Quarantine is next to impossible to enforce.
If you don’t want to stay in your home or wherever you are supposed to stay for three weeks, then what? Do we shoot you, Taser you, drag you back into your house in a protective suit, or what?
And who is responsible for watching you 24-7? Quarantine relies on the honor system. That essentially is what we count on when we tell people with symptoms to call 911 or the health department.
It does appear that this hasn’t been well thought through yet. NY Governor Cuomo said that “Doctors Without Borders”, the group that sponsors many of the volunteers, already requires volunteers to “decompress” for three weeks upon return from Africa, and they compensate their doctors during this time (see the above link). The state of NY would fill in for those sponsoring groups that do not offer compensation (at least in NY). Is the existing 3 week decompression period already a clue that they want people cleared before they return to work?Continue reading →
*I indicated I’d begin this new, once-a-month feature at the 3-year anniversary. I will repost and comment on one each month. (I might repost others that I do not comment on, as Oct. 31, 2014). For newcomers, here’s your chance to catch-up; for old timers, this is philosophy: rereading is essential!






















")

