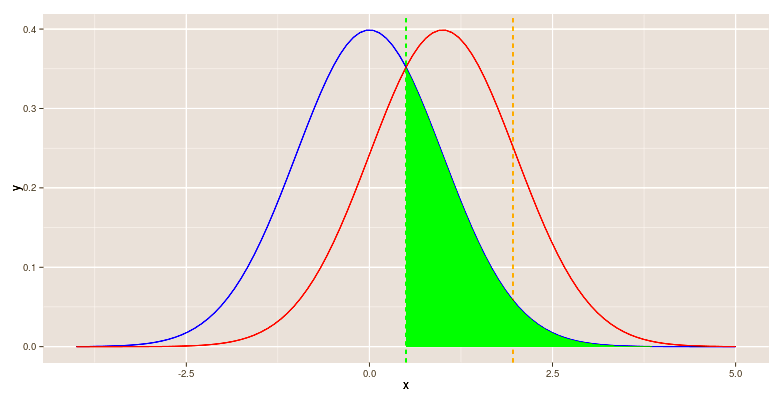
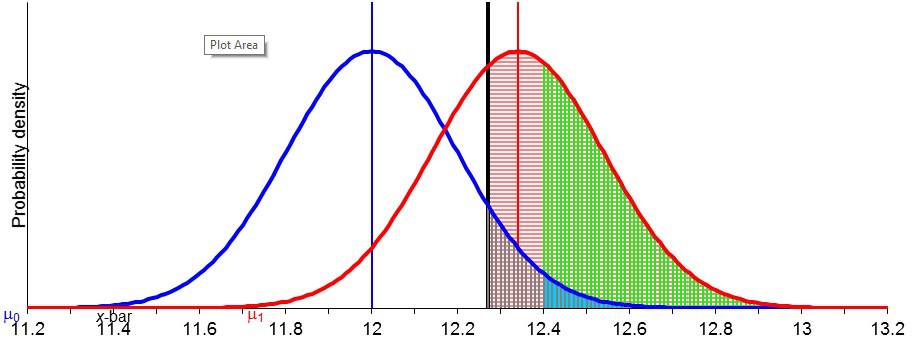
 Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
Statistical power is one of the neatest [i], yet most misunderstood statistical notions [ii].So here’s a visual illustration (written initially for our 6334 seminar), but worth a look by anyone who wants an easy way to attain the will to understand power.(Please see notes below slides.)
[i]I was tempted to say power is one of the “most powerful” notions.It is.True, severity leads us to look, not at the cut-off for rejection (as with power) but the actual observed value, or observed p-value. But the reasoning is the same. Likewise for less artificial cases where the standard deviation has to be estimated. See Mayo and Spanos 2006.
[ii]
- Some say that to compute power requires either knowing the alternative hypothesis (whatever that means), or worse, the alternative’s prior probability! Then there’s the tendency (by reformers no less!) to transpose power in such a way as to get the appraisal of tests exactly backwards. An example is Ziliac and McCloskey (2008). See,for example, the will to understand power: https://errorstatistics.com/2011/10/03/part-2-prionvac-the-will-to-understand-power/
- Many allege that a null hypothesis may be rejected (in favor of alternative H’) with greater warrant, the greater the power of the test against H’, e.g., Howson and Urbach (2006, 154). But this is mistaken. The frequentist appraisal of tests is the reverse, whether Fisherian significance tests or those of the Neyman-Pearson variety. One may find the fallacy exposed back in Morrison and Henkel (1970)! See EGEK 1996, pp. 402-3.
- For a humorous post on this fallacy, see: “The fallacy of rejection and the fallacy of nouvelle cuisine”: https://errorstatistics.com/2012/04/04/jackie-mason/
You can find a link to the Severity Excel Program (from which the pictures came) on the left hand column of this blog, and a link to basic instructions.This corresponds to EXAMPLE SET 1 pdf for Phil 6334.
Howson, C. and P. Urbach (2006). Scientific Reasoning: The Bayesian Approach. La Salle, Il: Open Court.
Mayo, D. G. and A. Spanos (2006) “Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction“ British Journal of Philosophy of Science, 57: 323-357.
Morrison and Henkel (1970), The significance Test controversy.
Ziliak, Z. and McCloskey, D. (2008), The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice and Lives, University of Michigan Press.

 S. Stanley Young, PhD
S. Stanley Young, PhD 





















")

