

.
A. Spanos Probability/Statistics Lecture Notes 7: An Introduction to Bayesian Inference (4/10/14)
.
A. Spanos Probability/Statistics Lecture Notes 7: An Introduction to Bayesian Inference (4/10/14)
 “There was a vain and ambitious hospital director. A bad statistician. ..There were good medics and bad medics, good nurses and bad nurses, good cops and bad cops … Apparently, even some people in the Public Prosecution service found the witch hunt deeply disturbing.”
“There was a vain and ambitious hospital director. A bad statistician. ..There were good medics and bad medics, good nurses and bad nurses, good cops and bad cops … Apparently, even some people in the Public Prosecution service found the witch hunt deeply disturbing.”
This is how Richard Gill, statistician at Leiden University, describes a feature film (Lucia de B.) just released about the case of Lucia de Berk, a nurse found guilty of several murders based largely on statistics. Gill is widely-known (among other things) for showing the flawed statistical analysis used to convict her, which ultimately led (after Gill’s tireless efforts) to her conviction being revoked. (I hope they translate the film into English.) In a recent e-mail Gill writes:
“The Dutch are going into an orgy of feel-good tear-jerking sentimentality as a movie comes out (the premiere is tonight) about the case. It will be a good movie, actually, but it only tells one side of the story. …When a jumbo jet goes down we find out what went wrong and prevent it from happening again. The Lucia case was a similar disaster. But no one even *knows* what went wrong. It can happen again tomorrow.
I spoke about it a couple of days ago at a TEDx event (Flanders).
You can find some p-values in my slides [“Murder by Numbers”, pasted below the video]. They were important – first in convicting Lucia, later in getting her a fair re-trial.”
Since it’s Saturday night, let’s watch Gill’s TEDx talk, “Statistical Error in court”.
Slides from the Talk: “Murder by Numbers”:

Sell me that antiseptic!
We were reading “Out, Damned Spot: Can the ‘Macbeth effect’ be replicated?” (Earp,B., Everett,J., Madva,E., and Hamlin,J. 2014, in Basic and Applied Social Psychology 36: 91-8) in an informal gathering of our 6334 seminar yesterday afternoon at Thebes. Some of the graduate students are interested in so-called “experimental” philosophy, and I asked for an example that used statistics for purposes of analysis. The example–and it’s a great one (thanks Rory M!)–revolves around priming research in social psychology. Yes the field that has come in for so much criticism as of late, especially after Diederik Stapel was found to have been fabricating data altogether (search this blog, e.g., here).[1] Continue reading
 April 3, 2014: We interspersed discussion with slides; these cover the main readings of the day (check syllabus): the Duhem’s Problem and the Bayesian Way, and “Highly probable vs Highly Probed”. syllabus four. Slides are below (followers of this blog will be familiar with most of this, e.g., here). We also did further work on misspecification testing.
April 3, 2014: We interspersed discussion with slides; these cover the main readings of the day (check syllabus): the Duhem’s Problem and the Bayesian Way, and “Highly probable vs Highly Probed”. syllabus four. Slides are below (followers of this blog will be familiar with most of this, e.g., here). We also did further work on misspecification testing.
Monday, April 7, is an optional outing, “a seminar class trip”

“Thebes”, Blacksburg, VA
you might say, here at Thebes at which time we will analyze the statistical curves of the mountains, pie charts of pizza, and (seriously) study some experiments on the problem of replication in “the Hamlet Effect in social psychology”. If you’re around please bop in!
Mayo’s slides on Duhem’s Problem and more from April 3 (Day#9):
 It was from my Virginia Tech colleague I.J. Good (in statistics), who died five years ago (April 5, 2009), at 93, that I learned most of what I call “howlers” on this blog. His favorites were based on the “paradoxes” of stopping rules. (I had posted this last year here.)
It was from my Virginia Tech colleague I.J. Good (in statistics), who died five years ago (April 5, 2009), at 93, that I learned most of what I call “howlers” on this blog. His favorites were based on the “paradoxes” of stopping rules. (I had posted this last year here.)
“In conversation I have emphasized to other statisticians, starting in 1950, that, in virtue of the ‘law of the iterated logarithm,’ by optional stopping an arbitrarily high sigmage, and therefore an arbitrarily small tail-area probability, can be attained even when the null hypothesis is true. In other words if a Fisherian is prepared to use optional stopping (which usually he is not) he can be sure of rejecting a true null hypothesis provided that he is prepared to go on sampling for a long time. The way I usually express this ‘paradox’ is that a Fisherian [but not a Bayesian] can cheat by pretending he has a plane to catch like a gambler who leaves the table when he is ahead” (Good 1983, 135) [*]
This is a blogpost on a talk (by Jeremy Fox) on blogging that will be live tweeted here at Virginia Tech on Monday April 7, and the moment I post this blog on “Blogging as a Mode of Scientific Communication” it will be tweeted. Live.
Jeremy’s upcoming talk on blogging will be live-tweeted by @FisheriesBlog, 1 pm EDT Apr. 7
Posted on April 3, 2014 by Jeremy Fox
If you like to follow live tweets of talks, you’re in luck: my upcoming Virginia Tech talk on blogging will be live tweeted by Brandon Peoples, a grad student there who co-authors The Fisheries Blog. Follow @FisheriesBlog at 1 pm US Eastern Daylight Time on Monday, April 7 for the live tweets.
Jeremy Fox’s excellent blog, “Dynamic Ecology,” often discusses matters statistical from a perspective in sync with error statistics.
I’ve never been invited to talk about blogging or even to blog about blogging, maybe this is a new trend. I look forward to meeting him (live!).

* Posts that don’t directly pertain to philosophy of science/statistics are placed under “rejected posts” but since this is a metablogpost on a talk on a blog pertaining to statistics it has been “conditionally accepted”, unconditionally, i.e., without conditions.

Danvers State Hospital
I had heard of medical designs that employ individuals who supply Bayesian subjective priors that are deemed either “enthusiastic” or “skeptical” as regards the probable value of medical treatments.[i] From what I gather, these priors are combined with data from trials in order to help decide whether to stop trials early or continue. But I’d never heard of these Bayesian designs in relation to decisions about building security or renovations! Listen to this…. Continue reading
 “Probability/Statistics Lecture Notes 6: An Introduction to Mis-Specification (M-S) Testing” (Aris Spanos)
“Probability/Statistics Lecture Notes 6: An Introduction to Mis-Specification (M-S) Testing” (Aris Spanos)
[Other slides from Day 9 by guest, John Byrd, can be found here.]
Winner of the March 2014 Palindrome Contest
Caitlin Parker
Palindrome:Able, we’d well aim on. I bet on a note. Binomial? Lewd. Ew, Elba!
The requirement was: A palindrome with Elba plus Binomial with an optional second word: bet. A palindrome that uses both Binomial and bet topped an acceptable palindrome that only uses Binomial.
Short bio:
Caitlin Parker is a first-year master’s student in the Philosophy department at Virginia Tech. Though her interests are in philosophy of science and statistics, she also has experience doing psychological research. Continue reading
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Central Identification Laboratory
JPAC
Guest, March 27, PHil 6334
“Statistical Considerations of the Histomorphometric Test Protocol for Determination of Human Origin of Skeletal Remains”
By:
 John E. Byrd, Ph.D. D-ABFA
John E. Byrd, Ph.D. D-ABFA
Maria-Teresa Tersigni-Tarrant, Ph.D.
Central Identification Laboratory
JPAC

.
We’re going to be discussing the philosophy of m-s testing today in our seminar, so I’m reblogging this from Feb. 2012. I’ve linked the 3 follow-ups below. Check the original posts for some good discussion. (Note visitor*)
“This is the kind of cure that kills the patient!”
is the line of Aris Spanos that I most remember from when I first heard him talk about testing assumptions of, and respecifying, statistical models in 1999. (The patient, of course, is the statistical model.) On finishing my book, EGEK 1996, I had been keen to fill its central gaps one of which was fleshing out a crucial piece of the error-statistical framework of learning from error: How to validate the assumptions of statistical models. But the whole problem turned out to be far more philosophically—not to mention technically—challenging than I imagined. I will try (in 3 short posts) to sketch a procedure that I think puts the entire process of model validation on a sound logical footing. Continue reading

Philosopher
“Philosophy majors rule” according to this recent article. We philosophers should be getting the word out. Admittedly, the type of people inclined to do well in philosophy are already likely to succeed in analytic areas. Coupled with the chuzpah of taking up an “outmoded and impractical” major like philosophy in the first place, innovative tendencies are not surprising. But can the study of philosophy also promote these capacities? I think it can and does; yet it could be far more effective than it is, if it was less hermetic and more engaged with problem-solving across the landscape of science,statistics,law,medicine,and evidence-based policy. Here’s the article: Continue reading
.
We spent the first half of Thursday’s seminar discussing the Fisher, Neyman, and E. Pearson “triad”[i]. So, since it’s Saturday night, join me in rereading for the nth time these three very short articles. The key issues were: error of the second kind, behavioristic vs evidential interpretations, and Fisher’s mysterious fiducial intervals. Although we often hear exaggerated accounts of the differences in the Fisherian vs Neyman-Pearson (NP) methodology, in fact, N-P were simply providing Fisher’s tests with a logical ground (even though other foundations for tests are still possible), and Fisher welcomed this gladly. Notably, with the single null hypothesis, N-P showed that it was possible to have tests where the probability of rejecting the null when true exceeded the probability of rejecting it when false. Hacking called such tests “worse than useless”, and N-P develop a theory of testing that avoids such problems. Statistical journalists who report on the alleged “inconsistent hybrid” (a term popularized by Gigerenzer) should recognize the extent to which the apparent disagreements on method reflect professional squabbling between Fisher and Neyman after 1935 [A recent example is a Nature article by R. Nuzzo in ii below]. The two types of tests are best seen as asking different questions in different contexts. They both follow error-statistical reasoning. Continue reading

Senn
Stephen Senn
Head, Methodology and Statistics Group,
Competence Center for Methodology and Statistics (CCMS),
Luxembourg
Delta Force
To what extent is clinical relevance relevant?
Inspiration
This note has been inspired by a Twitter exchange with respected scientist and famous blogger David Colquhoun. He queried whether a treatment that had 2/3 of an effect that would be described as clinically relevant could be useful. I was surprised at the question, since I would regard it as being pretty obvious that it could but, on reflection, I realise that things that may seem obvious to some who have worked in drug development may not be obvious to others, and if they are not obvious to others are either in need of a defence or wrong. I don’t think I am wrong and this note is to explain my thinking on the subject. Continue reading
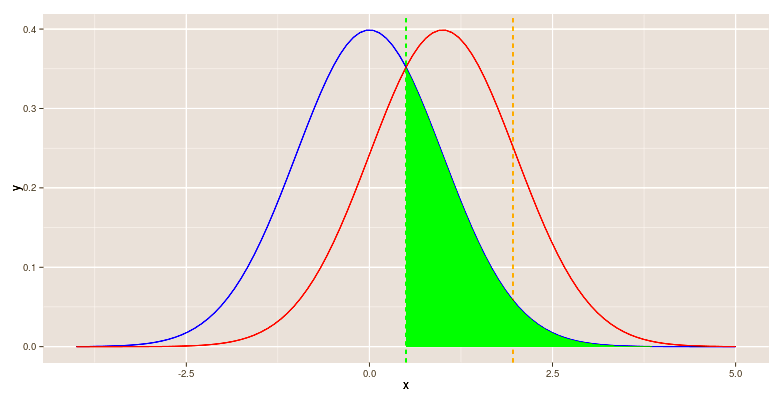 Karthik Durvasula, a blog follower[i], sent me a highly apt severity app that he created: https://karthikdurvasula.shinyapps.io/Severity_Calculator/
Karthik Durvasula, a blog follower[i], sent me a highly apt severity app that he created: https://karthikdurvasula.shinyapps.io/Severity_Calculator/ If a test’s power to detect µ’ is low then a statistically significant result is good/lousy evidence of discrepancy µ’? Which is it?
If a test’s power to detect µ’ is low then a statistically significant result is good/lousy evidence of discrepancy µ’? Which is it?
If your smoke alarm has little capability of triggering unless your house is fully ablaze, then if it has triggered, is that a strong or weak indication of a fire? Compare this insensitive smoke alarm to one that is so sensitive that burning toast sets it off. The answer is: that the alarm from the insensitive detector is triggered is a good indication of the presence of (some) fire, while hearing the ultra sensitive alarm go off is not.[i]
Yet I often hear people say things to the effect that: Continue reading
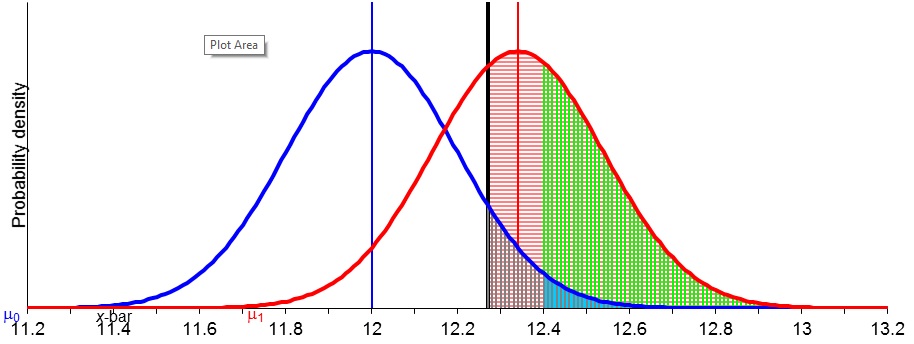 Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.
Below are slides from March 6, 2014: (a) the 2nd half of “Frequentist Statistics as a Theory of Inductive Inference” (Selection Effects),”* and (b) the discussion of the Higgs particle discovery and controversy over 5 sigma.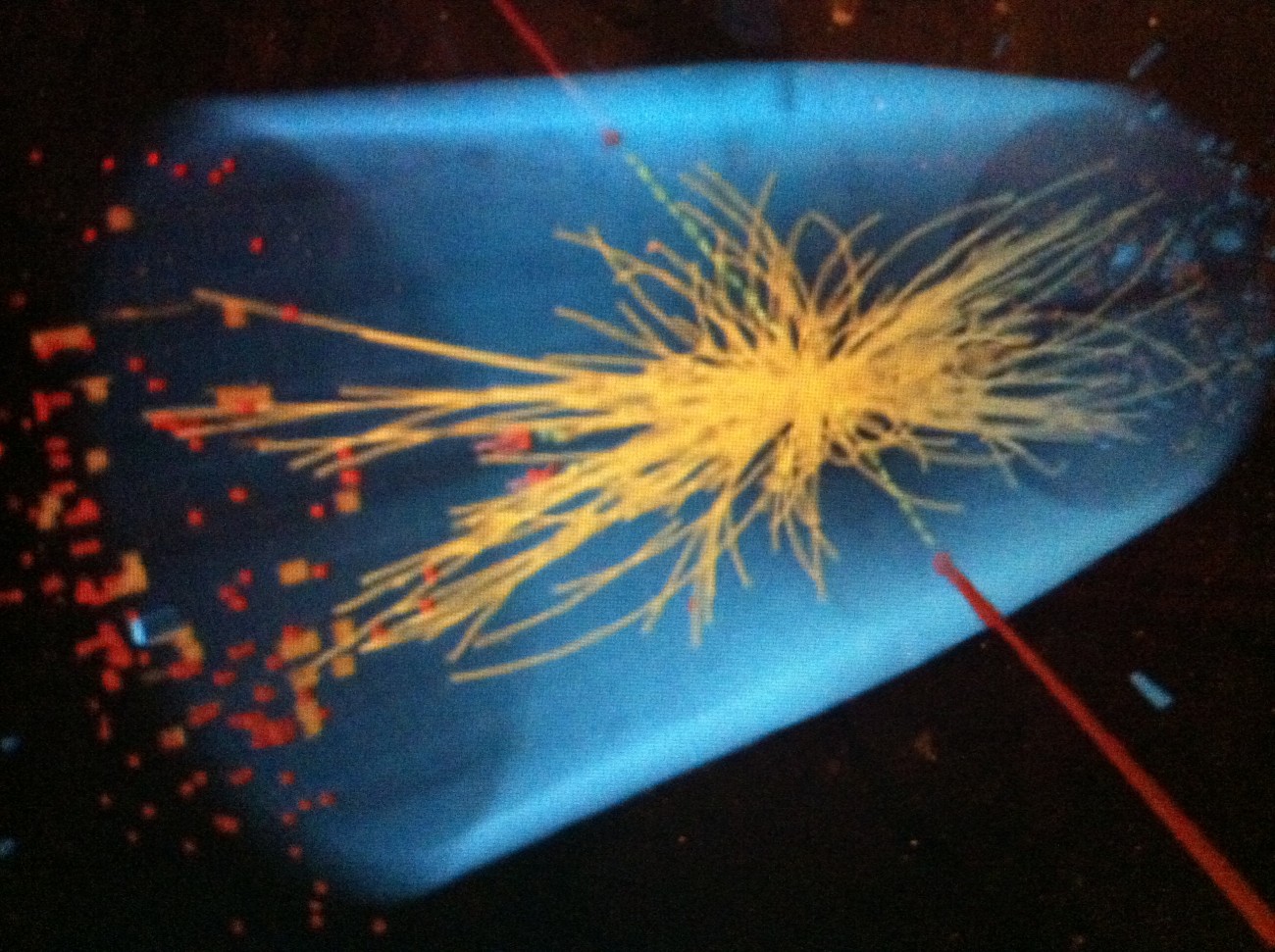
We spent the rest of the seminar computing significance levels, rejection regions, and power (by hand and with the Excel program). Here is the updated syllabus (3rd installment).
A relevant paper on selection effects on this blog is here.
 Any Jackie Mason fans out there? In connection with our discussion of power,and associated fallacies of rejection*–and since it’s Saturday night–I’m reblogging the following post.
Any Jackie Mason fans out there? In connection with our discussion of power,and associated fallacies of rejection*–and since it’s Saturday night–I’m reblogging the following post.
In February [2012], in London, criminologist Katrin H. and I went to see Jackie Mason do his shtick, a one-man show billed as his swan song to England. It was like a repertoire of his “Greatest Hits” without a new or updated joke in the mix. Still, hearing his rants for the nth time was often quite hilarious.
A sample: If you want to eat nothing, eat nouvelle cuisine. Do you know what it means? No food. The smaller the portion the more impressed people are, so long as the food’s got a fancy French name, haute cuisine. An empty plate with sauce!
As one critic wrote, Mason’s jokes “offer a window to a different era,” one whose caricatures and biases one can only hope we’ve moved beyond: But it’s one thing for Jackie Mason to scowl at a seat in the front row and yell to the shocked audience member in his imagination, “These are jokes! They are just jokes!” and another to reprise statistical howlers, which are not jokes, to me. This blog found its reason for being partly as a place to expose, understand, and avoid them. Recall the September 26, 2011 post “Whipping Boys and Witch Hunters”: [i]
Fortunately, philosophers of statistics would surely not reprise decades-old howlers and fallacies. After all, it is the philosopher’s job to clarify and expose the conceptual and logical foibles of others; and even if we do not agree, we would never merely disregard and fail to address the criticisms in published work by other philosophers. Oh wait, ….one of the leading texts repeats the fallacy in their third edition: Continue reading

")

Experts convene to explore new philosophy of statistics field



Power taboos: Statue of Liberty, Senn, Neyman, Carnap, Severity
My fire alarm analogy is here. My analogy presumes you are assessing the situation (about the fire) long distance. Continue reading →