 *addition of note [2].
*addition of note [2].
A long-running research program in philosophy is to seek a quantitative measure
C(h,x)
to capture intuitive ideas about “confirmation” and about “confirmational relevance”. The components of C(h,x) are allowed to be any statements, no reference to a probability model or to joint distributions are required. Then h is “confirmed” or supported by x if P(h|x) > P(h), disconfirmed (or undermined) if P(h|x) < P(h), (else x is confirmationally irrelevant to h). This is the generally accepted view of philosophers of confirmation (or Bayesian formal epistemologists) up to the present. There is generally a background “k” included, but to avoid a blinding mass of symbols I omit it. (We are rarely told how to get the probabilities anyway; but I’m going to leave that to one side, as it will not really matter here.)
A test of any purported philosophical confirmation theory is whether it elucidates or is even in sync with intuitive methodological principles about evidence or testing. One of the first problems that arises stems from asking…
Is Probability a good measure of confirmation?
A natural move then would be to identify the degree of confirmation of h by x with probability P(h|x), (which philosophers sometimes write as P(h,x)). Statement x affords hypothesis h higher confirmation than it does h’ iff P(h|x) > P(h’|x).
Some puzzles immediately arise. Hypothesis h can be confirmed by x, while h’ disconfirmed by x, and yet P(h|x) < P(h’|x). In other words, we can have P(h|x) > P(h) and P(h’|x) < P(h’) and yet P(h|x) < P(h’|x).
Popper (The Logic of Scientific Discovery, 1959, 390) gives this example, (I quote from him, only changing symbols slightly):
Consider the next toss with a homogeneous die.
h: 6 will turn up
h’: 6 will not turn up
x: an even number will turn up.
P(h) = 1/6, p(h’) = 5/6 P(x) = ½
The probability of h is raised by information x, while h’ is undermined by x. (It’s probability goes from 5/6 to 4/6.) If we identify probability with degree of confirmation, x confirms h and disconfirms h’ (i.e., P(h|x) >P(h) and P(h’|x) < P(h’)). Yet because P(h|x) < P(h’|x), h is less well confirmed given x than is h’. (This happens because P(h) is sufficiently low.) So P(h|x) cannot just be identified with the degree of confirmation that x affords h.
Note, these are not real statistical hypotheses but statements of events.
Obviously there needs to be a way to distinguish between some absolute confirmation for h, and a relative measure of how much it has increased due to x. From the start, Rudolf Carnap noted that “the verb ‘to confirm’ is ambiguous” but thought it had “the connotation of ‘making firmer’ even more often than that of ‘making firm’.” (Carnap, Logical Foundations of Probability (2nd), xviii ). x can increase the firmness of h, but C(h,x) < C(~h,x) (h is more firm, given x, than is ~h). Like Carnap, it’s the ‘making firmer’ that is generally assumed in Bayesian confirmation theory.
But there are many different measures of making firmer (Popper, Carnap, Fitelson). Referring to Popper’s example, we can report the ratio R: P(h|x)/P(h) = 2.
(In this case h’ = ~h).
Or we use the likelihood ratio LR: P(x|h)/P(x|~h) = (1/.4) = 2.5.
Many other ways of measuring the increase in confirmation x affords h could do as well. But what shall we say about the numbers like 2, 2.5? Do they mean the same thing in different contexts? What happens if we get beyond toy examples to scientific hypotheses where ~h would allude to all possible theories not yet thought of. What’s P(x|~h) where ~h is “the catchall” hypothesis asserting “something else”? (see, for example, Mayo 1997)
Perhaps this point won’t prevent confirmation logics from accomplishing the role of capturing and justifying intuitions about confirmation. So let’s consider the value of confirmation theories to that role. One of the early leaders of philosophical Bayesian confirmation, Peter Achinstein (2001), began to have doubts about the value of the philosopher’s a priori project. He even claims, rather provocatively, that “scientists do not and should not take … philosophical accounts of evidence seriously” (p. 9) because they give us formal syntactical (context –free) measures; whereas, scientists look to empirical grounds for confirmation. Philosophical accounts, moreover, make it too easy to confirm. He rejects confirmation as increased firmness, denying it is either necessary or sufficient for evidence. As far as making it too easy to get confirmation, there is the classic problem: it appears we can get everything to confirm everything, so long as one thing is confirmed. This is a famous argument due to Glymour (1980).
Paradox of irrelevant conjunctions
We now switch to emphasizing that the hypotheses may be statistical hypotheses or substantive theories. Both for this reason and because I think they look better, I move away from Popper and Carnap’s lower case letters for hypotheses.
The problem of irrelevant conjunctions (the “tacking paradox”) is this: If x confirms H, then x also confirms (H & J), even if hypothesis J is just “tacked on” to H. As with most of these chestnuts, there is a long history (e.g., Earman 1992, Rosenkrantz 1977), but consider just a leading contemporary representative, Branden Fitelson. Fitelson has importantly emphasized how many different C functions there are for capturing “makes firm”. Fitelson defines:
J is an irrelevant conjunct to H, with respect to x just in case P(x|H) = P(x|J & H).
For instance, x might be radioastronomic data in support of:
H: the deflection of light effect (due to gravity) is as stipulated in the General Theory of Relativity (GTR), 1.75” at the limb of the sun.
and the irrelevant conjunct:
J: the radioactivity of the Fukushima water being dumped in the Pacific ocean is within acceptable levels.
(1) Bayesian (Confirmation) Conjunction: If x Bayesian confirms H, then x Bayesian-confirms (H & J), where P(x| H & J ) = P(x|H) for any J consistent with H.
The reasoning is as follows:
P(x|H) /P(x) > 1 (x Bayesian confirms H)
P(x|H & J) = P(x|H) (given)
So [P(x|H & J) /P(x)]> 1
Therefore x Bayesian confirms (H & J)
However, it is also plausible to hold :
(2) Entailment condition: If x confirms T, and T entails J, then x confirms J.
In particular, if x confirms (H & J), then x confirms J.
(3) From (1) and (2) , if x confirms H, then x confirms J for any irrelevant J consistent with H.
(Assume neither H nor J have probabilities 0 or 1).
It follows that if x confirms any H, then x confirms any J.
Branden Fitelson’s solution
Fitelson (2002), and Fitelson and Hawthorne (2004) offer this “solution”: He will allow that x confirms (H & J), but deny the entailment condition. So, in particular, x confirms the conjunction although x does not confirm the irrelevant conjunct. Moreover, Fitelson shows, even though (H & J) is confirmed by x, (H & J) gets less of a confirmation (firmness) boost than does H—so long as one doesn’t measure the confirmation boost using R: P(h|x)/P(x). If one does use R, then (H & J) is just as well confirmed as is H, which is disturbing.
But even if we use the LR as our firmness boost, I would agree with Glymour that the solution scarcely solves the real problem. Paraphrasing him, we would not be assured by an account that tells us deflection of light data (x) confirms both GTR (H) and the radioactivity of the Fukushima water is within acceptable levels (J), while assuring us that x does not confirm the Fukishima water having acceptable levels of radiation (31).
The tacking paradox is to be expected if confirmation is taken as a variation on probabilistic affirming the consequent. Hypothetico-deductivists had the same problem, which is why Popper said we need to supplement each of the measures of confirmation boost with the condition of “severity”. However, he was unable to characterize severity adequately, and ultimately denied it could be formalized. He left it as an intuitive requirement that before applying any C-function, the confirming evidence must be the result of “a sincere (and ingenious) attempt to falsify the hypothesis” in question. I try to supply a more adequate account of severity (e.g., Mayo 1996, 2/3/12 post (no-pain philosophy III)).
How would the tacking method fare on the severity account? We’re not given the details we’d want for an error statistical appraisal, but let’s do the best with their stipulations. From our necessary condition, we have that (H and J) cannot warrant taking x as evidence for (H and J) if x counts as a highly insevere test of (H and J). The “test process” with tacking is something like this: having confirmed H, tack on any consistent but irrelevant J to obtain (H & J).(Sentence was amended on 10/21/13)
A scrutiny of well-testedness may proceed by denying either condition for severity. To follow the confirmation theorists, let’s grant the fit requirement (since H fits or entails x). This does not constitute having done anything to detect the falsity of H& J. The conjunction has been subjected to a radically non-risky test. (See also 1/2/13 post, esp. 5.3.4 Tacking Paradox Scotched.)
What they call confirmation we call mere “fit”
In fact, all their measures of confirmation C, be it the ratio measure R: P(H|x)/P(H) or the (so-called[1]) likelihood ratio LR: P(H|x)/P(~H|x), or one of the others, count merely as “fit” or “accordance” measures to the error statistician. There is no problem allowing each to be relevant for different problems and different dimensions of evidence. What we need to add in each case are the associated error probabilities:
P([H & J] is Bayesian confirmed; ~(J&H)) = maximal, so x is “bad evidence, no test” (BENT) for the conjunction.
We read “;” as “under the assumption that”.
In fact, all their measures of confirmation C are mere “fit” measures, be it the ratio measure R: P(H|x)/P(H) or the LR or other.
The following was added on 10-21-13: The above probability stems from taking the “fit measure” as a statistic, and assessing error probabilities by taking account the test process, as in error statistics. The result is
SEV[(H & J), tacking test, x] is minimal
I have still further problems with these inductive logic paradigms: an adequate philosophical account should answer questions and explicate principles about the methodology of scientific inference. Yet the Bayesian inductivist starts out assuming the intuition or principle, the task then being the homework problem of assigning priors and likelihoods that mesh with the principles. This often demands beating a Bayesian analysis into line, while still not getting at its genuine rationale. “The idea of putting probabilities over hypotheses delivered to philosophy a godsend, and an entire package of superficiality.” (Glymour 2010, 334). Perhaps philosophers are moving away from analytic reconstructions. Enough tears have been shed. But does an analogous problem crop up in Bayesian logic more generally?
I may update this post, and if I do I will alter the number following the title.
Oct. 20, 2013: I am updating this to reflect corrections pointed out by James Hawthorne, for which I’m very grateful. I will call this draft (ii).
Oct. 21, 2013 (updated in blue). I think another sentence might have accidentally got moved around.
Oct. 23, 2013. Given some issues that cropped up in the discussion (and the fact that certain symbols didn’t always come out right in the comments, I’m placing the point below in Note [2]):
[1] I say “so-called” because there’s no requirement of a proper statistical model here.
[2] Can P = C?
Spoze there’s a case where z confirms hh’ more than z confirms h’: C(hh’,z) > C(h’,z)
Now h’ = (~hh’ or hh’)
So,
(i) C(hh’,z) > C(~hh’ or hh’,z)
Since ~hh’ and hh’ are mutually exclusive, we have from special addition rule
(ii) P(hh’,z) < P(~hh’ or hh’,z)
So if P = C, (i) and (ii) yield a contradiction.
REFERENCES
Achinstein, P. (2001). The Book of Evidence. Oxford: Oxford University Press.
Carnap, R. (1962). Logical Foundations of Probability. Chicago: University of Chicago Press.
Earman, J. (1992). Bayes or Bust? A Critical Examination of Bayesian Confirmation Theory Cambridge MA: MIT Press.
Fitelson, B. (2002). Putting the Irrelevance Back Into the Problem of Irrelevant Conjunction. Philosophy of Science 69(4), 611–622.
Fitelson, B. & Hawthorne, J. (2004). Re-Solving Irrelevant Conjunction with Probabilistic Independence, Philosophy of Science, 71: 505–514.
Glymour, C. (1980) . Theory and Evidence. Princeton: Princeton University Press
_____. (2010). Explanation and Truth. In D. G. Mayo & A. Spanos (Eds.), Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability, and the Objectivity and Rationality of Science, 305–314. Cambridge: Cambridge University Press.
Mayo, D. (1996). Error and the Growth of Experimental Knowledge. Chicago: University of Chicago Press.
_____. (1997). “Duhem’s Problem, The Bayesian Way, and Error Statistics, or ‘What’s Belief got To Do With It?‘” and “Response to Howson and Laudan,” Philosophy of Science 64(1): 222-244 and 323-333.
_____. (2010). Explanation and Testing Exchanges with Clark Glymour. In D. G. Mayo & A. Spanos (Eds.), Error and Inference: Recent Exchanges on Experimental Reasoning, Reliability, and the Objectivity and Rationality of Science, 305–314. Cambridge: Cambridge University Press.
Popper, K. (1959). The Logic of Scientific Discovery. New York: Basic Books.
Rosenkranz, R. (1977). Inference, Method and Decision: Towards a Bayesian Philosophy of Science. Dordrecht, The Netherlands: D. Reidel.



















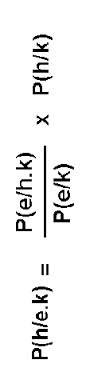




")

